 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexander Ihler
A Deep Q-Learning based, Base-Station Connectivity-Aware, Decentralized Pheromone Mobility Model for Autonomous UAV Networks
Nov 28, 2023
UAV networks consisting of low SWaP (size, weight, and power), fixed-wing UAVs are used in many applications, including area monitoring, search and rescue, surveillance, and tracking. Performing these operations efficiently requires a scalable, decentralized, autonomous UAV network architecture with high network connectivity. Whereas fast area coverage is needed for quickly sensing the area, strong node degree and base station (BS) connectivity are needed for UAV control and coordination and for transmitting sensed information to the BS in real time. However, the area coverage and connectivity exhibit a fundamental trade-off: maintaining connectivity restricts the UAVs' ability to explore. In this paper, we first present a node degree and BS connectivity-aware distributed pheromone (BS-CAP) mobility model to autonomously coordinate the UAV movements in a decentralized UAV network. This model maintains a desired connectivity among 1-hop neighbors and to the BS while achieving fast area coverage. Next, we propose a deep Q-learning policy based BS-CAP model (BSCAP-DQN) to further tune and improve the coverage and connectivity trade-off. Since it is not practical to know the complete topology of such a network in real time, the proposed mobility models work online, are fully distributed, and rely on neighborhood information. Our simulations demonstrate that both proposed models achieve efficient area coverage and desired node degree and BS connectivity, improving significantly over existing schemes.
Boosting AND/OR-Based Computational Protein Design: Dynamic Heuristics and Generalizable UFO
Aug 31, 2023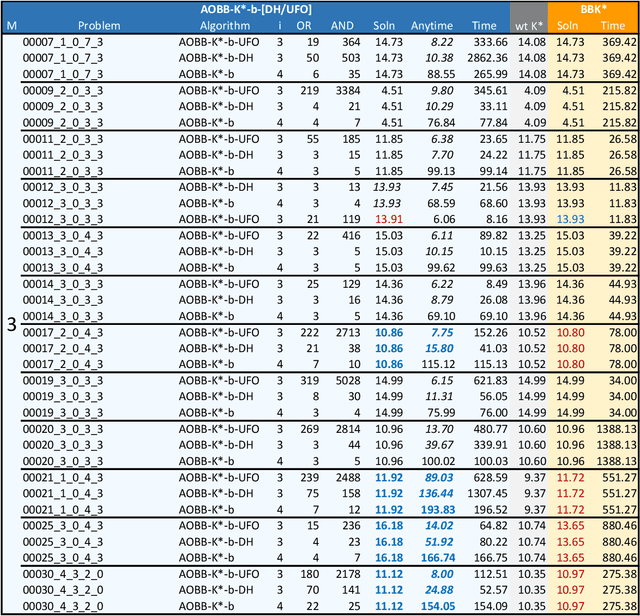
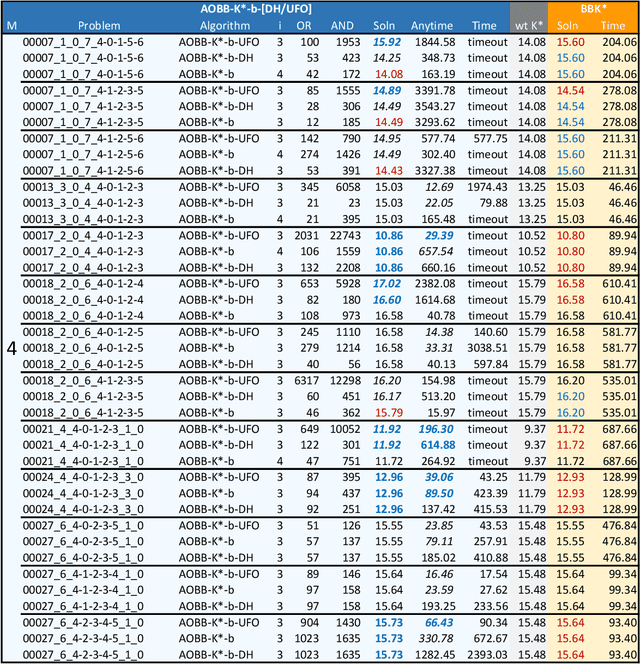
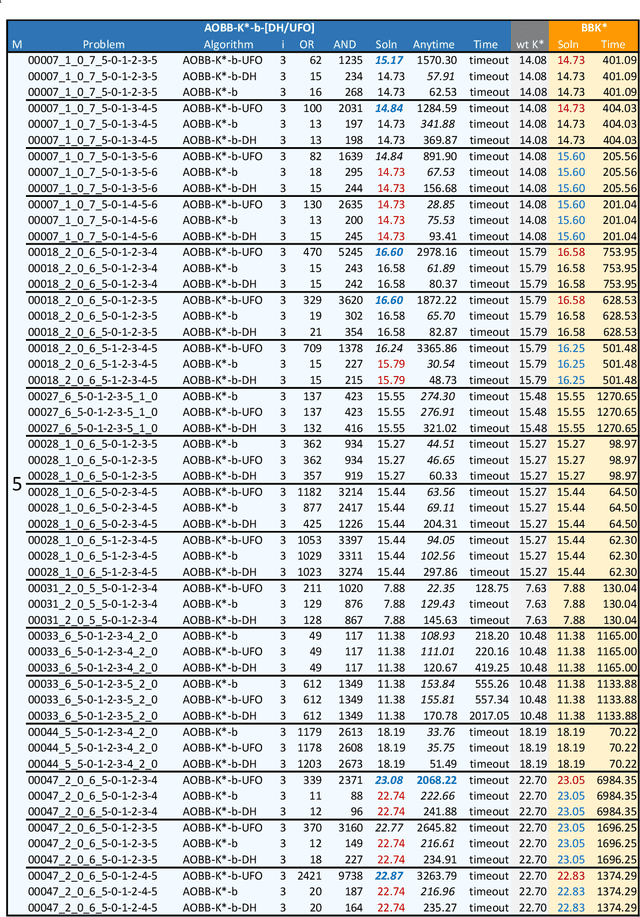
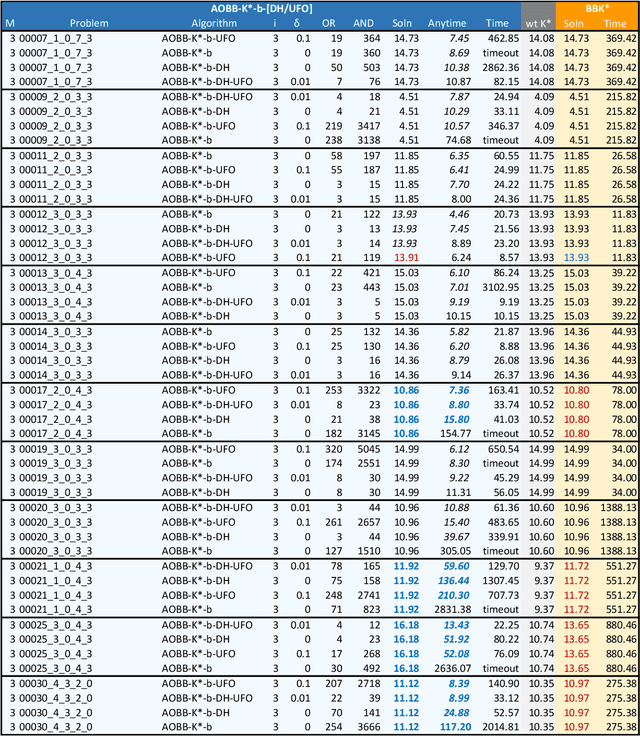
Scientific computing has experienced a surge empowered by advancements in technologies such as neural networks. However, certain important tasks are less amenable to these technologies, benefiting from innovations to traditional inference schemes. One such task is protein re-design. Recently a new re-design algorithm, AOBB-K*, was introduced and was competitive with state-of-the-art BBK* on small protein re-design problems. However, AOBB-K* did not scale well. In this work we focus on scaling up AOBB-K* and introduce three new versions: AOBB-K*-b (boosted), AOBB-K*-DH (with dynamic heuristics), and AOBB-K*-UFO (with underflow optimization) that significantly enhance scalability.
* In proceedings of the 39th Conference on Uncertainty in Artificial Intelligence (UAI 2023) and published in Proceedings of Machine Learning Research (PMLR)
Design Amortization for Bayesian Optimal Experimental Design
Oct 07, 2022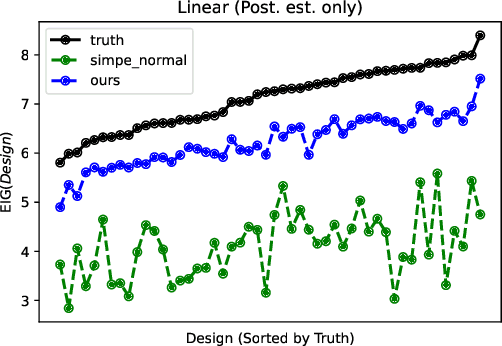
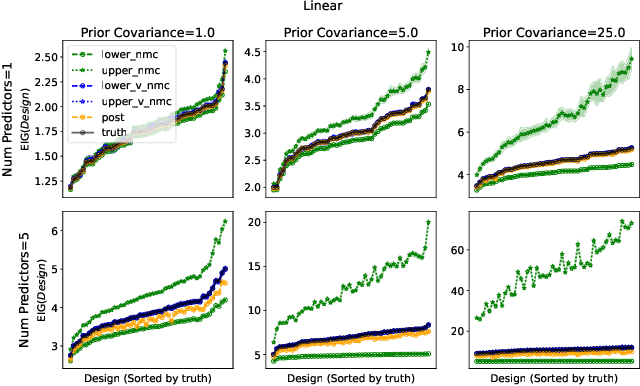
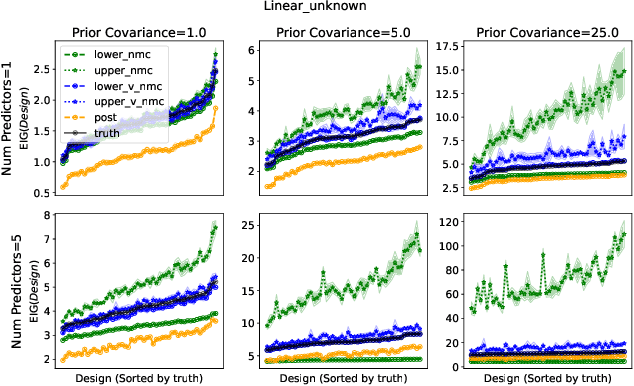
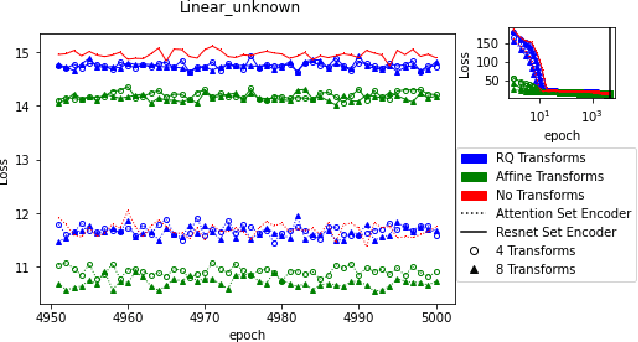
Bayesian optimal experimental design is a sub-field of statistics focused on developing methods to make efficient use of experimental resources. Any potential design is evaluated in terms of a utility function, such as the (theoretically well-justified) expected information gain (EIG); unfortunately however, under most circumstances the EIG is intractable to evaluate. In this work we build off of successful variational approaches, which optimize a parameterized variational model with respect to bounds on the EIG. Past work focused on learning a new variational model from scratch for each new design considered. Here we present a novel neural architecture that allows experimenters to optimize a single variational model that can estimate the EIG for potentially infinitely many designs. To further improve computational efficiency, we also propose to train the variational model on a significantly cheaper-to-evaluate lower bound, and show empirically that the resulting model provides an excellent guide for more accurate, but expensive to evaluate bounds on the EIG. We demonstrate the effectiveness of our technique on generalized linear models, a class of statistical models that is widely used in the analysis of controlled experiments. Experiments show that our method is able to greatly improve accuracy over existing approximation strategies, and achieve these results with far better sample efficiency.
Reducing Variance in Temporal-Difference Value Estimation via Ensemble of Deep Networks
Sep 16, 2022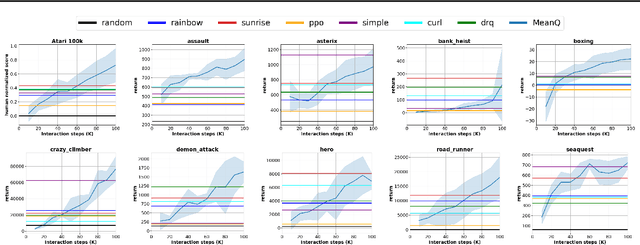

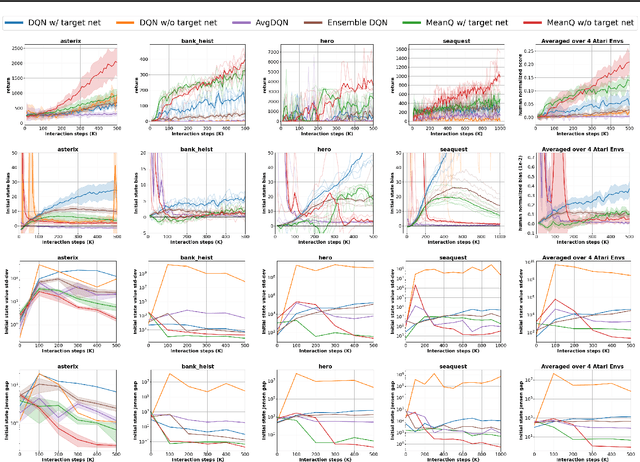
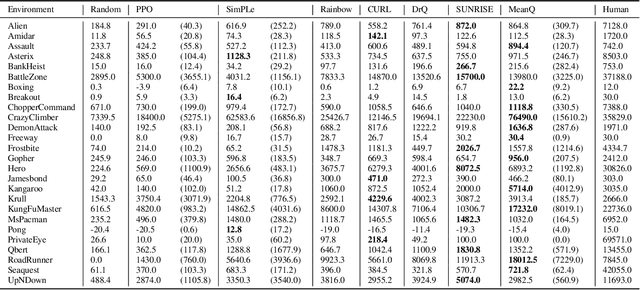
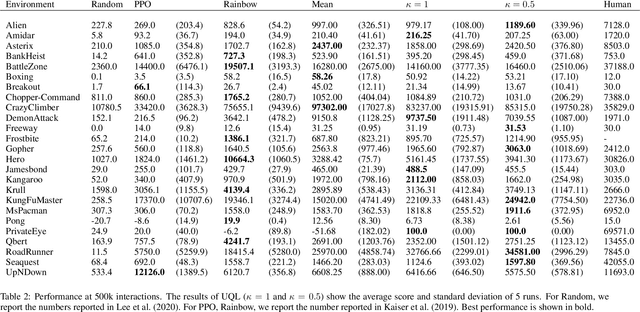
In temporal-difference reinforcement learning algorithms, variance in value estimation can cause instability and overestimation of the maximal target value. Many algorithms have been proposed to reduce overestimation, including several recent ensemble methods, however none have shown success in sample-efficient learning through addressing estimation variance as the root cause of overestimation. In this paper, we propose MeanQ, a simple ensemble method that estimates target values as ensemble means. Despite its simplicity, MeanQ shows remarkable sample efficiency in experiments on the Atari Learning Environment benchmark. Importantly, we find that an ensemble of size 5 sufficiently reduces estimation variance to obviate the lagging target network, eliminating it as a source of bias and further gaining sample efficiency. We justify intuitively and empirically the design choices in MeanQ, including the necessity of independent experience sampling. On a set of 26 benchmark Atari environments, MeanQ outperforms all tested baselines, including the best available baseline, SUNRISE, at 100K interaction steps in 16/26 environments, and by 68% on average. MeanQ also outperforms Rainbow DQN at 500K steps in 21/26 environments, and by 49% on average, and achieves average human-level performance using 200K ($\pm$100K) interaction steps. Our implementation is available at https://github.com/indylab/MeanQ.
Accurate Link Lifetime Computation in Autonomous Airborne UAV Networks
Jan 31, 2022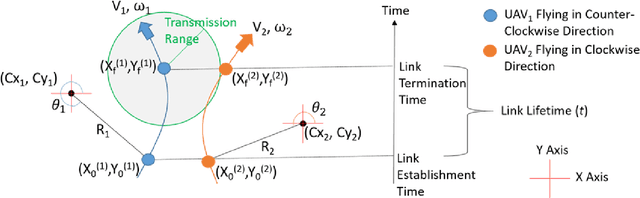
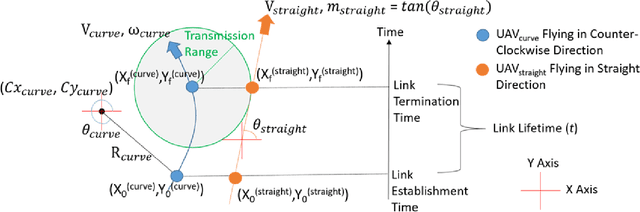
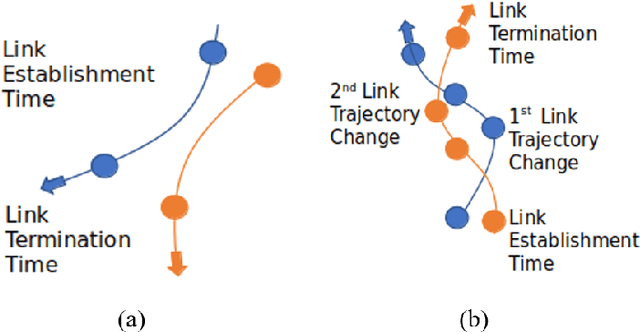
An autonomous airborne network (AN) consists of multiple unmanned aerial vehicles (UAVs), which can self-configure to provide seamless, low-cost and secure connectivity. AN is preferred for applications in civilian and military sectors because it can improve the network reliability and fault tolerance, reduce mission completion time through collaboration, and adapt to dynamic mission requirements. However, facilitating seamless communication in such ANs is a challenging task due to their fast node mobility, which results in frequent link disruptions. Many existing AN-specific mobility-aware schemes restrictively assume that UAVs fly in straight lines, to reduce the high uncertainty in the mobility pattern and simplify the calculation of link lifetime (LLT). Here, LLT represents the duration after which the link between a node pair terminates. However, the application of such schemes is severely limited, which makes them unsuitable for practical autonomous ANs. In this report, a mathematical framework is described to accurately compute the \textit{LLT} value for a UAV node pair, where each node flies independently in a randomly selected smooth trajectory. In addition, the impact of random trajectory changes on LLT accuracy is also discussed.
Temporal-Difference Value Estimation via Uncertainty-Guided Soft Updates
Oct 28, 2021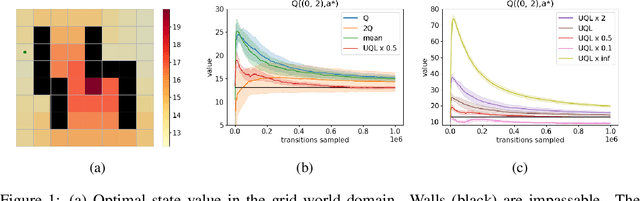

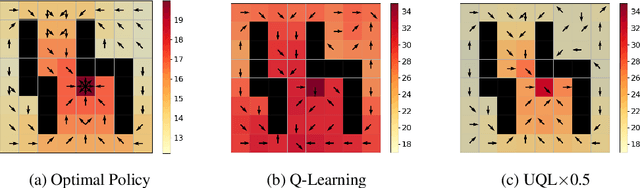
Temporal-Difference (TD) learning methods, such as Q-Learning, have proven effective at learning a policy to perform control tasks. One issue with methods like Q-Learning is that the value update introduces bias when predicting the TD target of a unfamiliar state. Estimation noise becomes a bias after the max operator in the policy improvement step, and carries over to value estimations of other states, causing Q-Learning to overestimate the Q value. Algorithms like Soft Q-Learning (SQL) introduce the notion of a soft-greedy policy, which reduces the estimation bias via soft updates in early stages of training. However, the inverse temperature $\beta$ that controls the softness of an update is usually set by a hand-designed heuristic, which can be inaccurate at capturing the uncertainty in the target estimate. Under the belief that $\beta$ is closely related to the (state dependent) model uncertainty, Entropy Regularized Q-Learning (EQL) further introduces a principled scheduling of $\beta$ by maintaining a collection of the model parameters that characterizes model uncertainty. In this paper, we present Unbiased Soft Q-Learning (UQL), which extends the work of EQL from two action, finite state spaces to multi-action, infinite state space Markov Decision Processes. We also provide a principled numerical scheduling of $\beta$, extended from SQL and using model uncertainty, during the optimization process. We show the theoretical guarantees and the effectiveness of this update method in experiments on several discrete control environments.
Active learning with RESSPECT: Resource allocation for extragalactic astronomical transients
Oct 26, 2020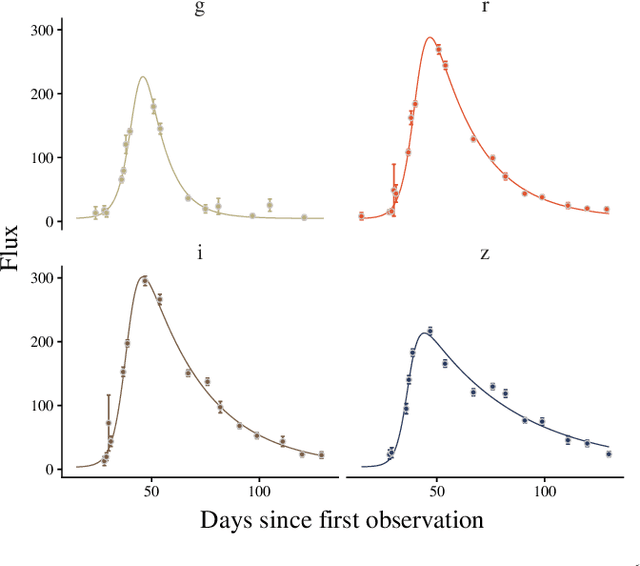
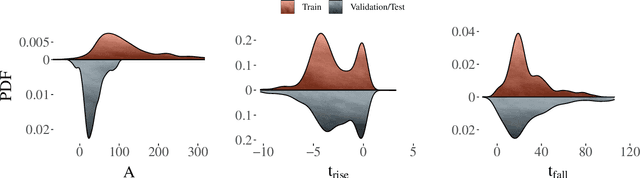
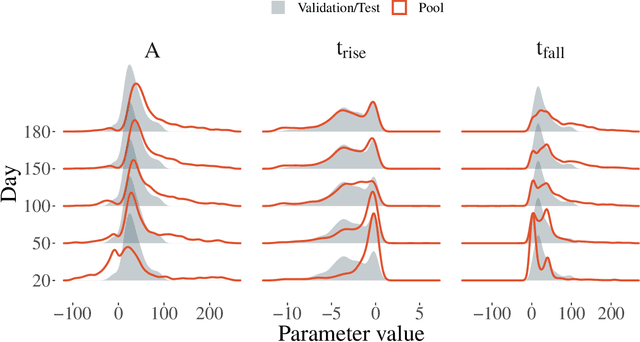
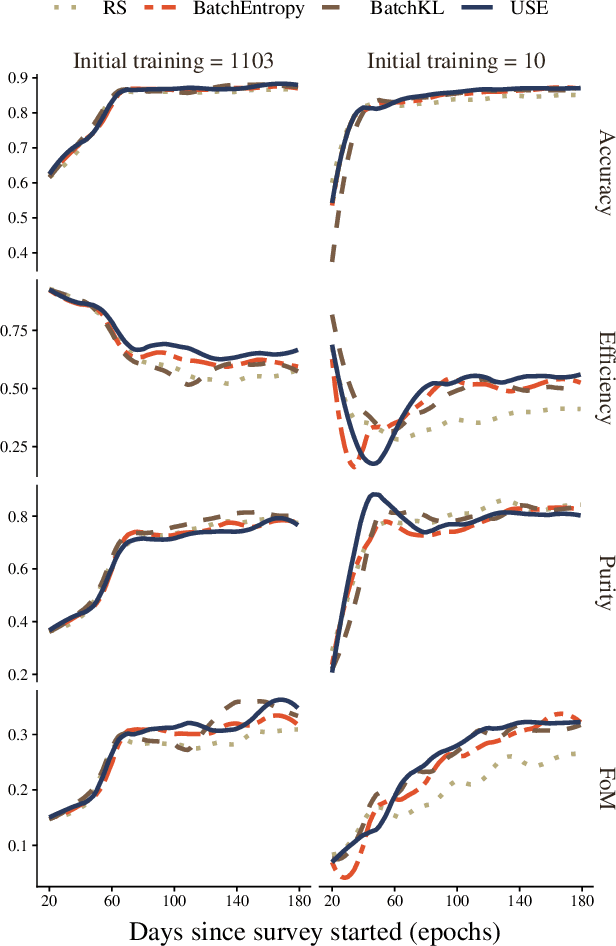
The recent increase in volume and complexity of available astronomical data has led to a wide use of supervised machine learning techniques. Active learning strategies have been proposed as an alternative to optimize the distribution of scarce labeling resources. However, due to the specific conditions in which labels can be acquired, fundamental assumptions, such as sample representativeness and labeling cost stability cannot be fulfilled. The Recommendation System for Spectroscopic follow-up (RESSPECT) project aims to enable the construction of optimized training samples for the Rubin Observatory Legacy Survey of Space and Time (LSST), taking into account a realistic description of the astronomical data environment. In this work, we test the robustness of active learning techniques in a realistic simulated astronomical data scenario. Our experiment takes into account the evolution of training and pool samples, different costs per object, and two different sources of budget. Results show that traditional active learning strategies significantly outperform random sampling. Nevertheless, more complex batch strategies are not able to significantly overcome simple uncertainty sampling techniques. Our findings illustrate three important points: 1) active learning strategies are a powerful tool to optimize the label-acquisition task in astronomy, 2) for upcoming large surveys like LSST, such techniques allow us to tailor the construction of the training sample for the first day of the survey, and 3) the peculiar data environment related to the detection of astronomical transients is a fertile ground that calls for the development of tailored machine learning algorithms.
Learning Infinite RBMs with Frank-Wolfe
Oct 15, 2017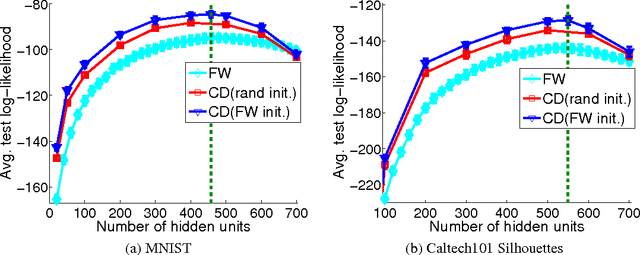
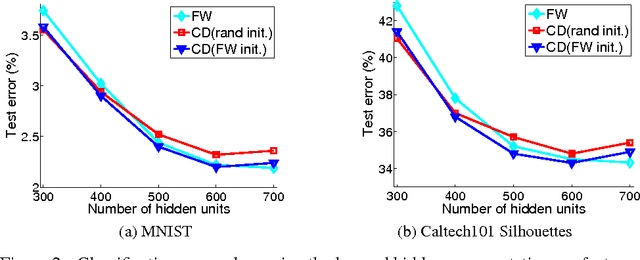
In this work, we propose an infinite restricted Boltzmann machine~(RBM), whose maximum likelihood estimation~(MLE) corresponds to a constrained convex optimization. We consider the Frank-Wolfe algorithm to solve the program, which provides a sparse solution that can be interpreted as inserting a hidden unit at each iteration, so that the optimization process takes the form of a sequence of finite models of increasing complexity. As a side benefit, this can be used to easily and efficiently identify an appropriate number of hidden units during the optimization. The resulting model can also be used as an initialization for typical state-of-the-art RBM training algorithms such as contrastive divergence, leading to models with consistently higher test likelihood than random initialization.
Multi-Person Pose Estimation via Column Generation
Sep 18, 2017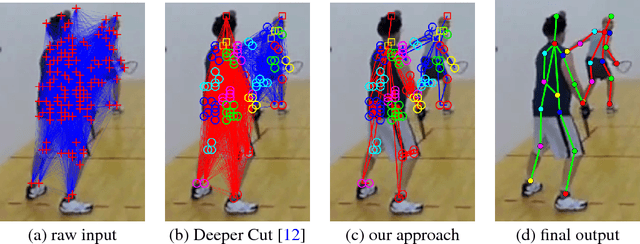
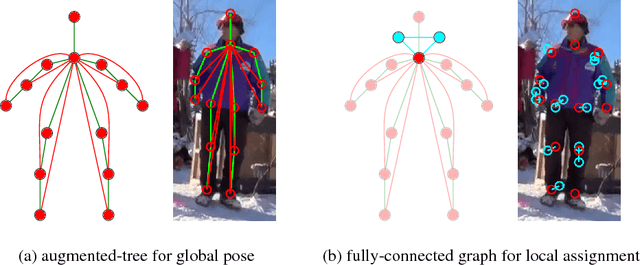

We study the problem of multi-person pose estimation in natural images. A pose estimate describes the spatial position and identity (head, foot, knee, etc.) of every non-occluded body part of a person. Pose estimation is difficult due to issues such as deformation and variation in body configurations and occlusion of parts, while multi-person settings add complications such as an unknown number of people, with unknown appearance and possible interactions in their poses and part locations. We give a novel integer program formulation of the multi-person pose estimation problem, in which variables correspond to assignments of parts in the image to poses in a two-tier, hierarchical way. This enables us to develop an efficient custom optimization procedure based on column generation, where columns are produced by exact optimization of very small scale integer programs. We demonstrate improved accuracy and speed for our method on the MPII multi-person pose estimation benchmark.