 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexandre Saidi
Brenier approach for optimal transportation between a quasi-discrete measure and a discrete measure
Jan 17, 2018
Correctly estimating the discrepancy between two data distributions has always been an important task in Machine Learning. Recently, Cuturi proposed the Sinkhorn distance which makes use of an approximate Optimal Transport cost between two distributions as a distance to describe distribution discrepancy. Although it has been successfully adopted in various machine learning applications (e.g. in Natural Language Processing and Computer Vision) since then, the Sinkhorn distance also suffers from two unnegligible limitations. The first one is that the Sinkhorn distance only gives an approximation of the real Wasserstein distance, the second one is the `divide by zero' problem which often occurs during matrix scaling when setting the entropy regularization coefficient to a small value. In this paper, we introduce a new Brenier approach for calculating a more accurate Wasserstein distance between two discrete distributions, this approach successfully avoids the two limitations shown above for Sinkhorn distance and gives an alternative way for estimating distribution discrepancy.
Optimal Transport for Deep Joint Transfer Learning
Sep 09, 2017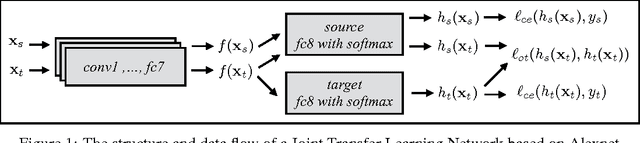

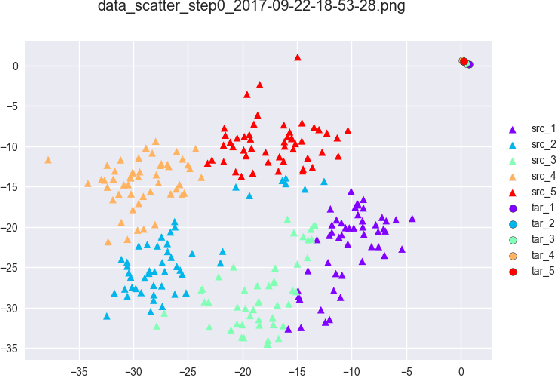
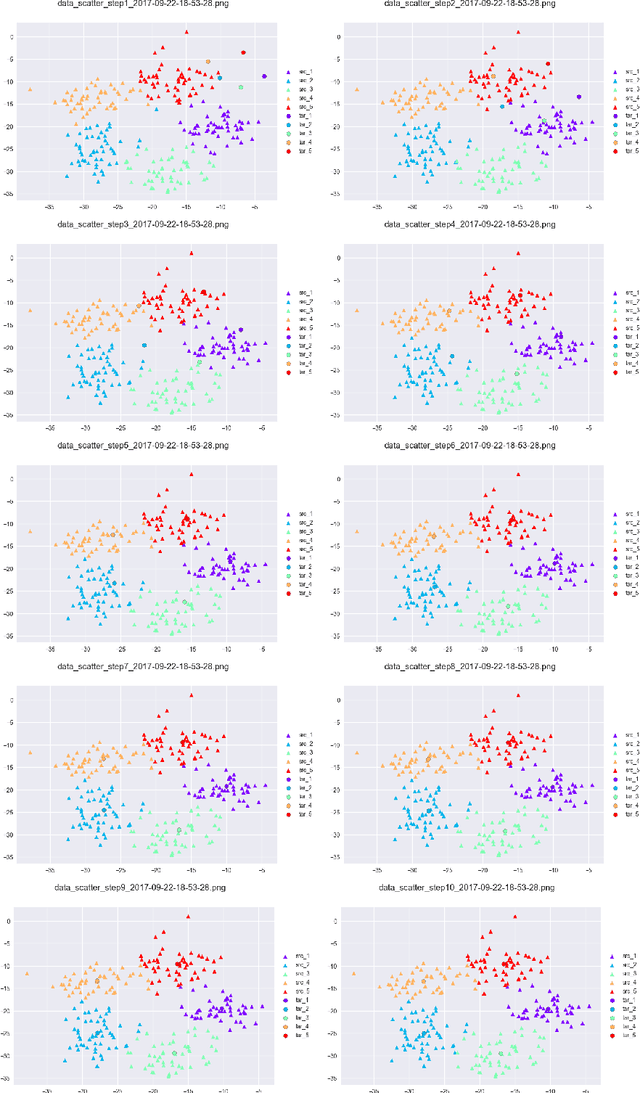
Training a Deep Neural Network (DNN) from scratch requires a large amount of labeled data. For a classification task where only small amount of training data is available, a common solution is to perform fine-tuning on a DNN which is pre-trained with related source data. This consecutive training process is time consuming and does not consider explicitly the relatedness between different source and target tasks. In this paper, we propose a novel method to jointly fine-tune a Deep Neural Network with source data and target data. By adding an Optimal Transport loss (OT loss) between source and target classifier predictions as a constraint on the source classifier, the proposed Joint Transfer Learning Network (JTLN) can effectively learn useful knowledge for target classification from source data. Furthermore, by using different kind of metric as cost matrix for the OT loss, JTLN can incorporate different prior knowledge about the relatedness between target categories and source categories. We carried out experiments with JTLN based on Alexnet on image classification datasets and the results verify the effectiveness of the proposed JTLN in comparison with standard consecutive fine-tuning. This Joint Transfer Learning with OT loss is general and can also be applied to other kind of Neural Networks.