 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmir M. Rahmani
Integrating Wearable Sensor Data and Self-reported Diaries for Personalized Affect Forecasting
Mar 23, 2024
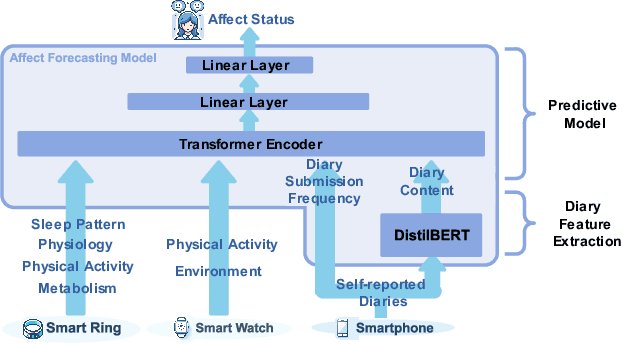
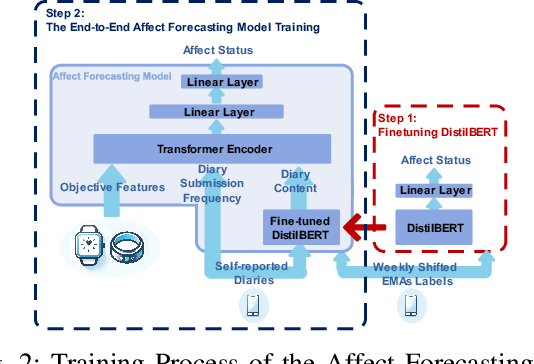
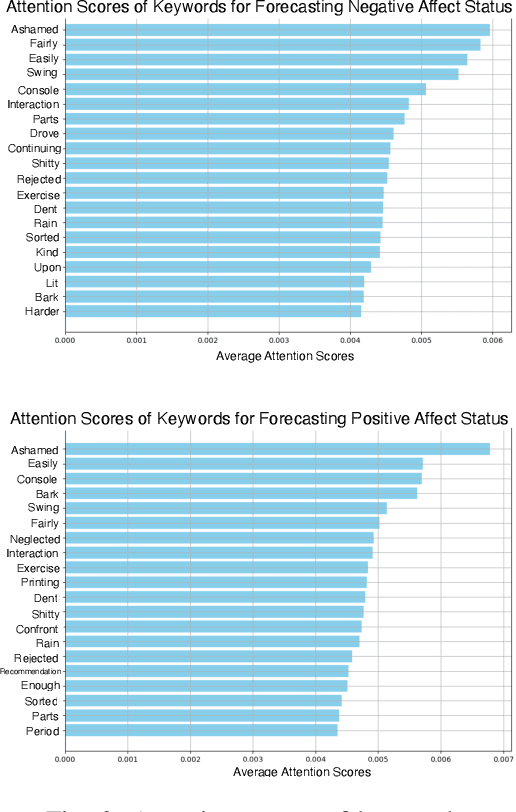
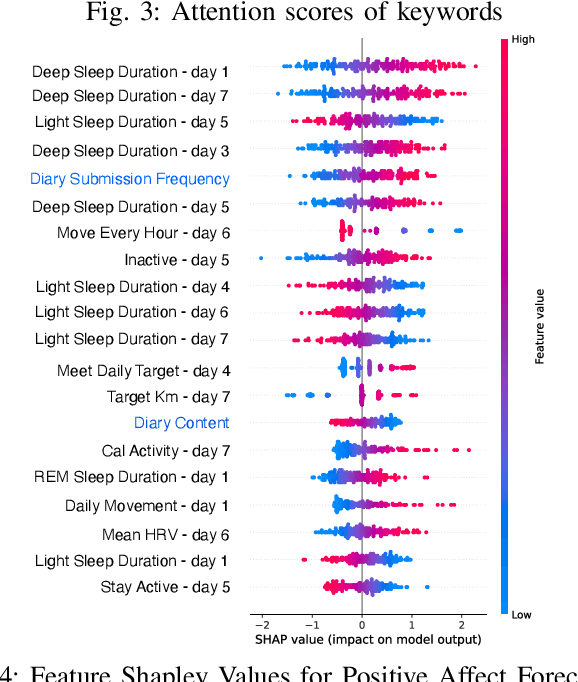
Emotional states, as indicators of affect, are pivotal to overall health, making their accurate prediction before onset crucial. Current studies are primarily centered on immediate short-term affect detection using data from wearable and mobile devices. These studies typically focus on objective sensory measures, often neglecting other forms of self-reported information like diaries and notes. In this paper, we propose a multimodal deep learning model for affect status forecasting. This model combines a transformer encoder with a pre-trained language model, facilitating the integrated analysis of objective metrics and self-reported diaries. To validate our model, we conduct a longitudinal study, enrolling college students and monitoring them over a year, to collect an extensive dataset including physiological, environmental, sleep, metabolic, and physical activity parameters, alongside open-ended textual diaries provided by the participants. Our results demonstrate that the proposed model achieves predictive accuracy of 82.50% for positive affect and 82.76% for negative affect, a full week in advance. The effectiveness of our model is further elevated by its explainability.
Knowledge-Infused LLM-Powered Conversational Health Agent: A Case Study for Diabetes Patients
Feb 28, 2024Effective diabetes management is crucial for maintaining health in diabetic patients. Large Language Models (LLMs) have opened new avenues for diabetes management, facilitating their efficacy. However, current LLM-based approaches are limited by their dependence on general sources and lack of integration with domain-specific knowledge, leading to inaccurate responses. In this paper, we propose a knowledge-infused LLM-powered conversational health agent (CHA) for diabetic patients. We customize and leverage the open-source openCHA framework, enhancing our CHA with external knowledge and analytical capabilities. This integration involves two key components: 1) incorporating the American Diabetes Association dietary guidelines and the Nutritionix information and 2) deploying analytical tools that enable nutritional intake calculation and comparison with the guidelines. We compare the proposed CHA with GPT4. Our evaluation includes 100 diabetes-related questions on daily meal choices and assessing the potential risks associated with the suggested diet. Our findings show that the proposed agent demonstrates superior performance in generating responses to manage essential nutrients.
Impact of Physical Activity on Quality of Life During Pregnancy: A Causal ML Approach
Feb 25, 2024The concept of Quality of Life (QoL) refers to a holistic measurement of an individual's well-being, incorporating psychological and social aspects. Pregnant women, especially those with obesity and stress, often experience lower QoL. Physical activity (PA) has shown the potential to enhance the QoL. However, pregnant women who are overweight and obese rarely meet the recommended level of PA. Studies have investigated the relationship between PA and QoL during pregnancy using correlation-based approaches. These methods aim to discover spurious correlations between variables rather than causal relationships. Besides, the existing methods mainly rely on physical activity parameters and neglect the use of different factors such as maternal (medical) history and context data, leading to biased estimates. Furthermore, the estimations lack an understanding of mediators and counterfactual scenarios that might affect them. In this paper, we investigate the causal relationship between being physically active (treatment variable) and the QoL (outcome) during pregnancy and postpartum. To estimate the causal effect, we develop a Causal Machine Learning method, integrating causal discovery and causal inference components. The data for our investigation is derived from a long-term wearable-based health monitoring study focusing on overweight and obese pregnant women. The machine learning (meta-learner) estimation technique is used to estimate the causal effect. Our result shows that performing adequate physical activity during pregnancy and postpartum improves the QoL by units of 7.3 and 3.4 on average in physical health and psychological domains, respectively. In the final step, four refutation analysis techniques are employed to validate our estimation.
Differential Private Federated Transfer Learning for Mental Health Monitoring in Everyday Settings: A Case Study on Stress Detection
Feb 16, 2024Mental health conditions, prevalent across various demographics, necessitate efficient monitoring to mitigate their adverse impacts on life quality. The surge in data-driven methodologies for mental health monitoring has underscored the importance of privacy-preserving techniques in handling sensitive health data. Despite strides in federated learning for mental health monitoring, existing approaches struggle with vulnerabilities to certain cyber-attacks and data insufficiency in real-world applications. In this paper, we introduce a differential private federated transfer learning framework for mental health monitoring to enhance data privacy and enrich data sufficiency. To accomplish this, we integrate federated learning with two pivotal elements: (1) differential privacy, achieved by introducing noise into the updates, and (2) transfer learning, employing a pre-trained universal model to adeptly address issues of data imbalance and insufficiency. We evaluate the framework by a case study on stress detection, employing a dataset of physiological and contextual data from a longitudinal study. Our finding show that the proposed approach can attain a 10% boost in accuracy and a 21% enhancement in recall, while ensuring privacy protection.
Optimizing Warfarin Dosing Using Contextual Bandit: An Offline Policy Learning and Evaluation Method
Feb 16, 2024Warfarin, an anticoagulant medication, is formulated to prevent and address conditions associated with abnormal blood clotting, making it one of the most prescribed drugs globally. However, determining the suitable dosage remains challenging due to individual response variations, and prescribing an incorrect dosage may lead to severe consequences. Contextual bandit and reinforcement learning have shown promise in addressing this issue. Given the wide availability of observational data and safety concerns of decision-making in healthcare, we focused on using exclusively observational data from historical policies as demonstrations to derive new policies; we utilized offline policy learning and evaluation in a contextual bandit setting to establish the optimal personalized dosage strategy. Our learned policies surpassed these baseline approaches without genotype inputs, even when given a suboptimal demonstration, showcasing promising application potential.
Food Recommendation as Language Processing (F-RLP): A Personalized and Contextual Paradigm
Feb 14, 2024State-of-the-art rule-based and classification-based food recommendation systems face significant challenges in becoming practical and useful. This difficulty arises primarily because most machine learning models struggle with problems characterized by an almost infinite number of classes and a limited number of samples within an unbalanced dataset. Conversely, the emergence of Large Language Models (LLMs) as recommendation engines offers a promising avenue. However, a general-purpose Recommendation as Language Processing (RLP) approach lacks the critical components necessary for effective food recommendations. To address this gap, we introduce Food Recommendation as Language Processing (F-RLP), a novel framework that offers a food-specific, tailored infrastructure. F-RLP leverages the capabilities of LLMs to maximize their potential, thereby paving the way for more accurate, personalized food recommendations.
Robust CNN-based Respiration Rate Estimation for Smartwatch PPG and IMU
Jan 10, 2024Respiratory rate (RR) serves as an indicator of various medical conditions, such as cardiovascular diseases and sleep disorders. These RR estimation methods were mostly designed for finger-based PPG collected from subjects in stationary situations (e.g., in hospitals). In contrast to finger-based PPG signals, wrist-based PPG are more susceptible to noise, particularly in their low frequency range, which includes respiratory information. Therefore, the existing methods struggle to accurately extract RR when PPG data are collected from wrist area under free-living conditions. The increasing popularity of smartwatches, equipped with various sensors including PPG, has prompted the need for a robust RR estimation method. In this paper, we propose a convolutional neural network-based approach to extract RR from PPG, accelerometer, and gyroscope signals captured via smartwatches. Our method, including a dilated residual inception module and 1D convolutions, extract the temporal information from the signals, enabling RR estimation. Our method is trained and tested using data collected from 36 subjects under free-living conditions for one day using Samsung Gear Sport watches. For evaluation, we compare the proposed method with four state-of-the-art RR estimation methods. The RR estimates are compared with RR references obtained from a chest-band device. The results show that our method outperforms the existing methods with the Mean-Absolute-Error and Root-Mean-Square-Error of 1.85 and 2.34, while the best results obtained by the other methods are 2.41 and 3.29, respectively. Moreover, compared to the other methods, the absolute error distribution of our method was narrow (with the lowest median), indicating a higher level of agreement between the estimated and reference RR values.
Conversational Health Agents: A Personalized LLM-Powered Agent Framework
Oct 03, 2023Conversational Health Agents (CHAs) are interactive systems designed to enhance personal healthcare services by engaging in empathetic conversations and processing multimodal data. While current CHAs, especially those utilizing Large Language Models (LLMs), primarily focus on conversation, they often lack comprehensive agent capabilities. This includes the ability to access personal user health data from wearables, 24/7 data collection sources, and electronic health records, as well as integrating the latest published health insights and connecting with established multimodal data analysis tools. We are developing a framework to empower CHAs by equipping them with critical thinking, knowledge acquisition, and problem-solving abilities. Our CHA platform, powered by LLMs, seamlessly integrates healthcare tools, enables multilingual and multimodal conversations, and interfaces with a variety of user data analysis tools. We illustrate its proficiency in handling complex healthcare tasks, such as stress level estimation, showcasing the agent's cognitive and operational capabilities.
Reducing Intraspecies and Interspecies Covariate Shift in Traumatic Brain Injury EEG of Humans and Mice Using Transfer Euclidean Alignment
Oct 03, 2023While analytics of sleep electroencephalography (EEG) holds certain advantages over other methods in clinical applications, high variability across subjects poses a significant challenge when it comes to deploying machine learning models for classification tasks in the real world. In such instances, machine learning models that exhibit exceptional performance on a specific dataset may not necessarily demonstrate similar proficiency when applied to a distinct dataset for the same task. The scarcity of high-quality biomedical data further compounds this challenge, making it difficult to evaluate the model's generality comprehensively. In this paper, we introduce Transfer Euclidean Alignment - a transfer learning technique to tackle the problem of the dearth of human biomedical data for training deep learning models. We tested the robustness of this transfer learning technique on various rule-based classical machine learning models as well as the EEGNet-based deep learning model by evaluating on different datasets, including human and mouse data in a binary classification task of detecting individuals with versus without traumatic brain injury (TBI). By demonstrating notable improvements with an average increase of 14.42% for intraspecies datasets and 5.53% for interspecies datasets, our findings underscore the importance of the use of transfer learning to improve the performance of machine learning and deep learning models when using diverse datasets for training.
Foundation Metrics: Quantifying Effectiveness of Healthcare Conversations powered by Generative AI
Sep 21, 2023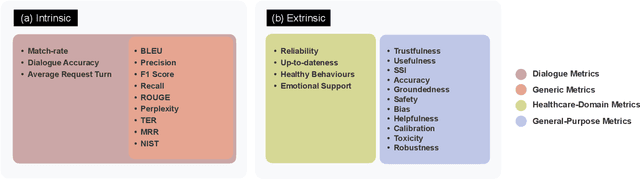

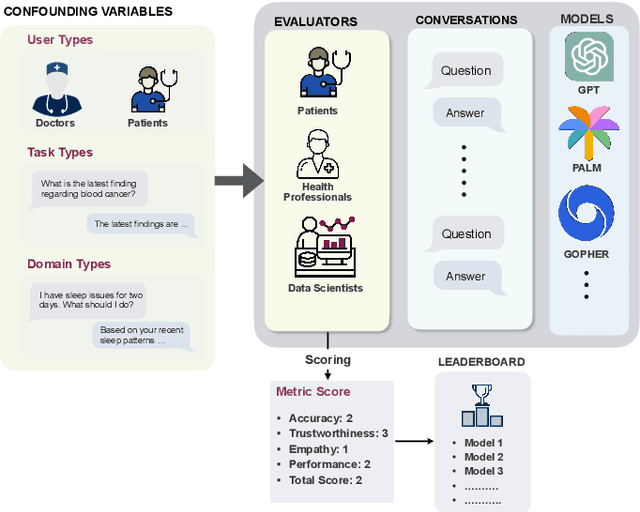

Generative Artificial Intelligence is set to revolutionize healthcare delivery by transforming traditional patient care into a more personalized, efficient, and proactive process. Chatbots, serving as interactive conversational models, will probably drive this patient-centered transformation in healthcare. Through the provision of various services, including diagnosis, personalized lifestyle recommendations, and mental health support, the objective is to substantially augment patient health outcomes, all the while mitigating the workload burden on healthcare providers. The life-critical nature of healthcare applications necessitates establishing a unified and comprehensive set of evaluation metrics for conversational models. Existing evaluation metrics proposed for various generic large language models (LLMs) demonstrate a lack of comprehension regarding medical and health concepts and their significance in promoting patients' well-being. Moreover, these metrics neglect pivotal user-centered aspects, including trust-building, ethics, personalization, empathy, user comprehension, and emotional support. The purpose of this paper is to explore state-of-the-art LLM-based evaluation metrics that are specifically applicable to the assessment of interactive conversational models in healthcare. Subsequently, we present an comprehensive set of evaluation metrics designed to thoroughly assess the performance of healthcare chatbots from an end-user perspective. These metrics encompass an evaluation of language processing abilities, impact on real-world clinical tasks, and effectiveness in user-interactive conversations. Finally, we engage in a discussion concerning the challenges associated with defining and implementing these metrics, with particular emphasis on confounding factors such as the target audience, evaluation methods, and prompt techniques involved in the evaluation process.