 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMahyar Abbasian
Knowledge-Infused LLM-Powered Conversational Health Agent: A Case Study for Diabetes Patients
Feb 28, 2024
Effective diabetes management is crucial for maintaining health in diabetic patients. Large Language Models (LLMs) have opened new avenues for diabetes management, facilitating their efficacy. However, current LLM-based approaches are limited by their dependence on general sources and lack of integration with domain-specific knowledge, leading to inaccurate responses. In this paper, we propose a knowledge-infused LLM-powered conversational health agent (CHA) for diabetic patients. We customize and leverage the open-source openCHA framework, enhancing our CHA with external knowledge and analytical capabilities. This integration involves two key components: 1) incorporating the American Diabetes Association dietary guidelines and the Nutritionix information and 2) deploying analytical tools that enable nutritional intake calculation and comparison with the guidelines. We compare the proposed CHA with GPT4. Our evaluation includes 100 diabetes-related questions on daily meal choices and assessing the potential risks associated with the suggested diet. Our findings show that the proposed agent demonstrates superior performance in generating responses to manage essential nutrients.
Conversational Health Agents: A Personalized LLM-Powered Agent Framework
Oct 03, 2023Conversational Health Agents (CHAs) are interactive systems designed to enhance personal healthcare services by engaging in empathetic conversations and processing multimodal data. While current CHAs, especially those utilizing Large Language Models (LLMs), primarily focus on conversation, they often lack comprehensive agent capabilities. This includes the ability to access personal user health data from wearables, 24/7 data collection sources, and electronic health records, as well as integrating the latest published health insights and connecting with established multimodal data analysis tools. We are developing a framework to empower CHAs by equipping them with critical thinking, knowledge acquisition, and problem-solving abilities. Our CHA platform, powered by LLMs, seamlessly integrates healthcare tools, enables multilingual and multimodal conversations, and interfaces with a variety of user data analysis tools. We illustrate its proficiency in handling complex healthcare tasks, such as stress level estimation, showcasing the agent's cognitive and operational capabilities.
Foundation Metrics: Quantifying Effectiveness of Healthcare Conversations powered by Generative AI
Sep 21, 2023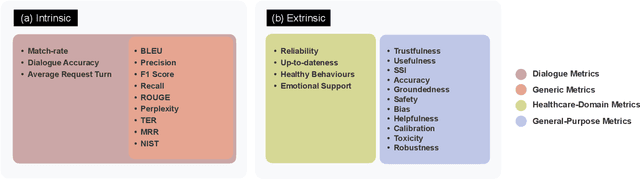

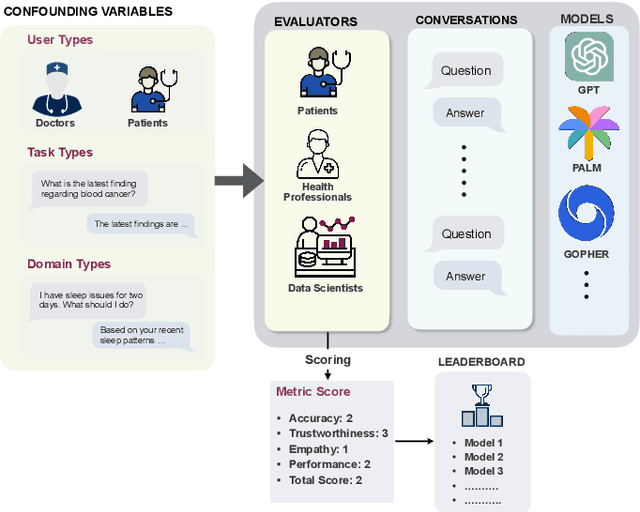

Generative Artificial Intelligence is set to revolutionize healthcare delivery by transforming traditional patient care into a more personalized, efficient, and proactive process. Chatbots, serving as interactive conversational models, will probably drive this patient-centered transformation in healthcare. Through the provision of various services, including diagnosis, personalized lifestyle recommendations, and mental health support, the objective is to substantially augment patient health outcomes, all the while mitigating the workload burden on healthcare providers. The life-critical nature of healthcare applications necessitates establishing a unified and comprehensive set of evaluation metrics for conversational models. Existing evaluation metrics proposed for various generic large language models (LLMs) demonstrate a lack of comprehension regarding medical and health concepts and their significance in promoting patients' well-being. Moreover, these metrics neglect pivotal user-centered aspects, including trust-building, ethics, personalization, empathy, user comprehension, and emotional support. The purpose of this paper is to explore state-of-the-art LLM-based evaluation metrics that are specifically applicable to the assessment of interactive conversational models in healthcare. Subsequently, we present an comprehensive set of evaluation metrics designed to thoroughly assess the performance of healthcare chatbots from an end-user perspective. These metrics encompass an evaluation of language processing abilities, impact on real-world clinical tasks, and effectiveness in user-interactive conversations. Finally, we engage in a discussion concerning the challenges associated with defining and implementing these metrics, with particular emphasis on confounding factors such as the target audience, evaluation methods, and prompt techniques involved in the evaluation process.
Controlling the Latent Space of GANs through Reinforcement Learning: A Case Study on Task-based Image-to-Image Translation
Jul 26, 2023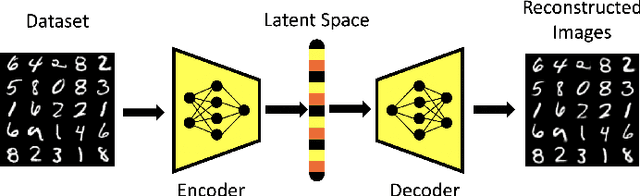
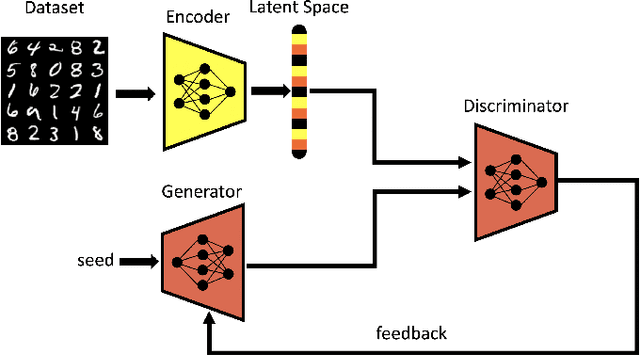
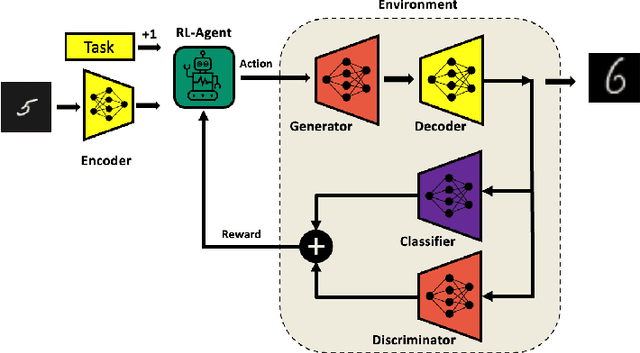

Generative Adversarial Networks (GAN) have emerged as a formidable AI tool to generate realistic outputs based on training datasets. However, the challenge of exerting control over the generation process of GANs remains a significant hurdle. In this paper, we propose a novel methodology to address this issue by integrating a reinforcement learning (RL) agent with a latent-space GAN (l-GAN), thereby facilitating the generation of desired outputs. More specifically, we have developed an actor-critic RL agent with a meticulously designed reward policy, enabling it to acquire proficiency in navigating the latent space of the l-GAN and generating outputs based on specified tasks. To substantiate the efficacy of our approach, we have conducted a series of experiments employing the MNIST dataset, including arithmetic addition as an illustrative task. The outcomes of these experiments serve to validate our methodology. Our pioneering integration of an RL agent with a GAN model represents a novel advancement, holding great potential for enhancing generative networks in the future.