 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAng Yang
Deep Learning Based OFDM Channel Estimation Using Frequency-Time Division and Attention Mechanism
Jul 30, 2021
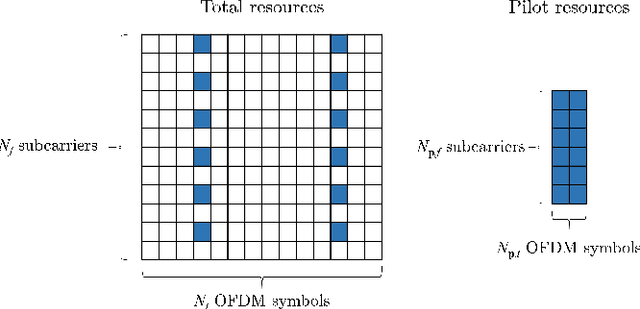
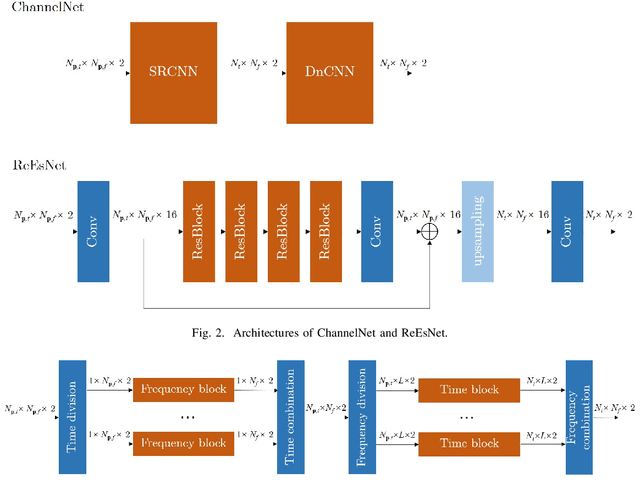
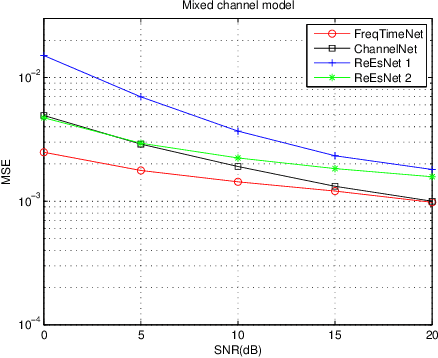
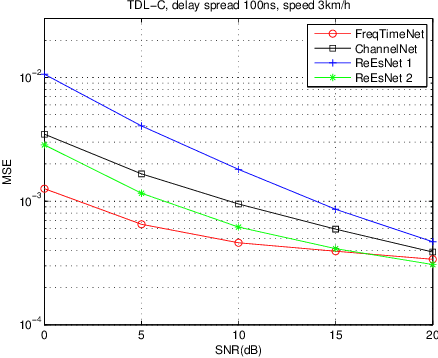
In this paper, we propose a frequency-time division network (FreqTimeNet) to improve the performance of deep learning (DL) based OFDM channel estimation. This FreqTimeNet is designed based on the orthogonality between the frequency domain and the time domain. In FreqTimeNet, the input is processed by parallel frequency blocks and parallel time blocks in sequential. Introducing the attention mechanism to use the SNR information, an attention based FreqTimeNet (AttenFreqTimeNet) is proposed. Using 3rd Generation Partnership Project (3GPP) channel models, the mean square error (MSE) performance of FreqTimeNet and AttenFreqTimeNet under different scenarios is evaluated. A method for constructing mixed training data is proposed, which could address the generalization problem in DL. It is observed that AttenFreqTimeNet outperforms FreqTimeNet, and FreqTimeNet outperforms other DL networks, with acceptable complexity.
Deep Learning-based Implicit CSI Feedback in Massive MIMO
May 21, 2021



Massive multiple-input multiple-output can obtain more performance gain by exploiting the downlink channel state information (CSI) at the base station (BS). Therefore, studying CSI feedback with limited communication resources in frequency-division duplexing systems is of great importance. Recently, deep learning (DL)-based CSI feedback has shown considerable potential. However, the existing DL-based explicit feedback schemes are difficult to deploy because current fifth-generation mobile communication protocols and systems are designed based on an implicit feedback mechanism. In this paper, we propose a DL-based implicit feedback architecture to inherit the low-overhead characteristic, which uses neural networks (NNs) to replace the precoding matrix indicator (PMI) encoding and decoding modules. By using environment information, the NNs can achieve a more refined mapping between the precoding matrix and the PMI compared with codebooks. The correlation between subbands is also used to further improve the feedback performance. Simulation results show that, for a single resource block (RB), the proposed architecture can save 25.0% and 40.0% of overhead compared with Type I codebook under two antenna configurations, respectively. For a wideband system with 52 RBs, overhead can be saved by 30.7% and 48.0% compared with Type II codebook when ignoring and considering extracting subband correlation, respectively.
Scalable Bayesian Optimization with Sparse Gaussian Process Models
Oct 26, 2020



This thesis focuses on Bayesian optimization with the improvements coming from two aspects:(i) the use of derivative information to accelerate the optimization convergence; and (ii) the consideration of scalable GPs for handling massive data.
Sparse Spectrum Gaussian Process for Bayesian Optimisation
Jun 21, 2019



We propose a novel sparse spectrum approximation of Gaussian process (GP) tailored for Bayesian optimisation. Whilst the current sparse spectrum methods provide good approximations for regression problems, it is observed that this particular form of sparse approximations generates an overconfident GP, i.e. it predicts less variance than the original GP. Since the balance between predictive mean and the predictive variance is a key determinant in the success of Bayesian optimisation, the current sparse spectrum methods are less suitable. We derive a regularised marginal likelihood for finding the optimal frequencies in optimisation problems. The regulariser trades the accuracy in the model fitting with the targeted increase in the variance of the resultant GP. We first consider the entropy of the distribution over the maxima as the regulariser that needs to be maximised. Later we show that the Expected Improvement acquisition function can also be used as a proxy for that, thus making the optimisation less computationally expensive. Experiments show an increase in the Bayesian optimisation convergence rate over the vanilla sparse spectrum method.