 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFei Qin
A Hybrid Frame Structure Design of OTFS for Multi-tasks Communications
Nov 21, 2023
Orthogonal time frequency space (OTFS) is a promising waveform in high mobility scenarios for it fully exploits the time-frequency diversity using a discrete Fourier transform (DFT) based two dimensional spreading. However, it trades off the processing latency for performance and may not fulfill the stringent latency requirements in some services. This fact motivates us to design a hybrid frame structure where the OTFS and Orthogonal Frequency Division Multiplexing (OFDM) are orthogonally multiplexed in the time domain, which can adapt to both diversity-preferred and latency-preferred tasks. As we identify that this orthogonality is disrupted after channel coupling, we provide practical algorithms to mitigate the inter symbol interference between (ISI) the OTFS and OFDM, and the numerical results ensure the effectiveness of the hybrid frame structure.
Practical Issues and Challenges in CSI-based Integrated Sensing and Communication
Mar 18, 2022Next-generation mobile communication network (i.e., 6G) has been envisioned to go beyond classical communication functionality and provide integrated sensing and communication (ISAC) capability to enable more emerging applications, such as smart cities, connected vehicles, AIoT and health care/elder care. Among all the ISAC proposals, the most practical and promising approach is to empower existing wireless network (e.g., WiFi, 4G/5G) with the augmented ability to sense the surrounding human and environment, and evolve wireless communication networks into intelligent communication and sensing network (e.g., 6G). In this paper, based on our experience on CSI-based wireless sensing with WiFi/4G/5G signals, we intend to identify ten major practical and theoretical problems that hinder real deployment of ISAC applications, and provide possible solutions to those critical challenges. Hopefully, this work will inspire further research to evolve existing WiFi/4G/5G networks into next-generation intelligent wireless network (i.e., 6G).
Deep Learning Based OFDM Channel Estimation Using Frequency-Time Division and Attention Mechanism
Jul 30, 2021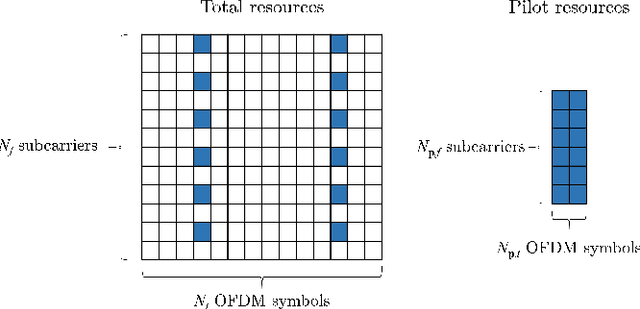
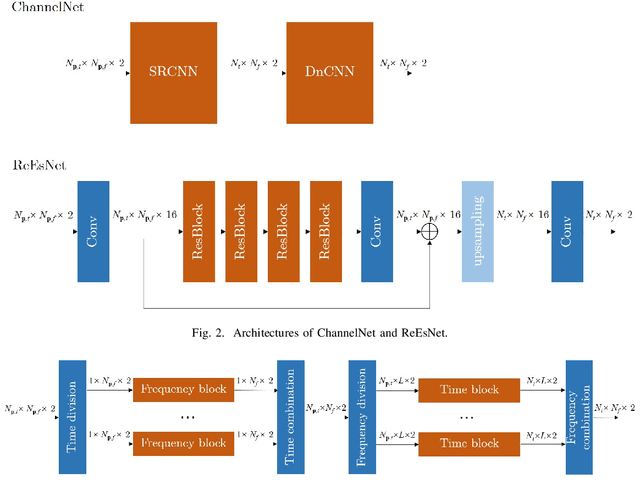
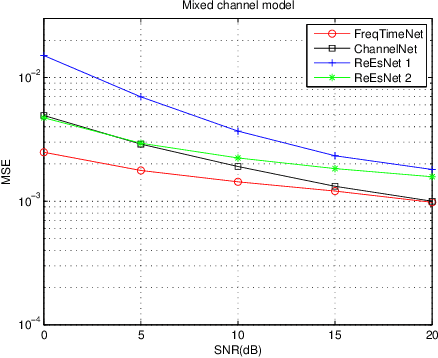
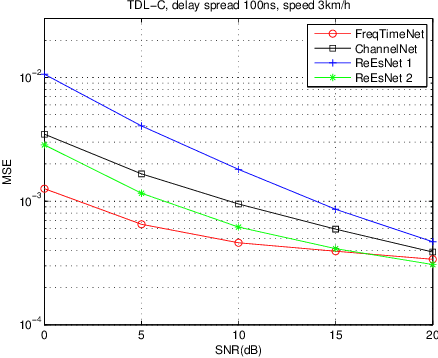
In this paper, we propose a frequency-time division network (FreqTimeNet) to improve the performance of deep learning (DL) based OFDM channel estimation. This FreqTimeNet is designed based on the orthogonality between the frequency domain and the time domain. In FreqTimeNet, the input is processed by parallel frequency blocks and parallel time blocks in sequential. Introducing the attention mechanism to use the SNR information, an attention based FreqTimeNet (AttenFreqTimeNet) is proposed. Using 3rd Generation Partnership Project (3GPP) channel models, the mean square error (MSE) performance of FreqTimeNet and AttenFreqTimeNet under different scenarios is evaluated. A method for constructing mixed training data is proposed, which could address the generalization problem in DL. It is observed that AttenFreqTimeNet outperforms FreqTimeNet, and FreqTimeNet outperforms other DL networks, with acceptable complexity.
Frequency-Time Division based Deep Learning for OFDM Channel Estimation
Jul 15, 2021In this paper, we propose a frequency-time division network (FreqTimeNet) to improve the performance of deep learning (DL) based OFDM channel estimation. This FreqTimeNet is designed based on the orthogonality between the frequency domain and the time domain. In FreqTimeNet, the input signals are processed by parallel frequency blocks first and then go through parallel time blocks. Using 3rd Generation Partnership Project (3GPP) channel models, the mean square error (MSE) performance of FreqTimeNet under different scenarios is evaluated. A method for constructing mixed training data is proposed, which could address the generalization problem in DL. It is observed that FreqTimeNet outperforms other DL networks, with acceptable complexity.
Linear Span Network for Object Skeleton Detection
Jul 25, 2018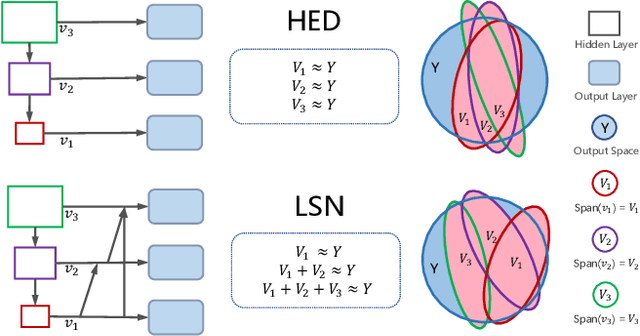

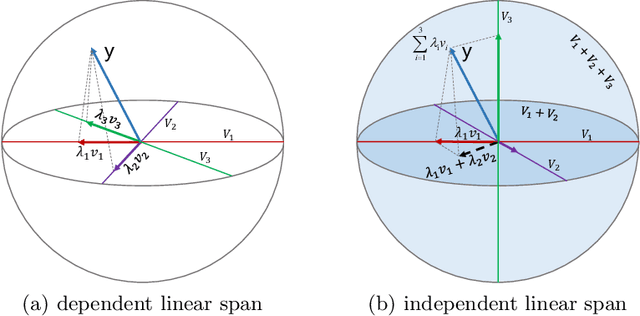

Robust object skeleton detection requires to explore rich representative visual features and effective feature fusion strategies. In this paper, we first re-visit the implementation of HED, the essential principle of which can be ideally described with a linear reconstruction model. Hinted by this, we formalize a Linear Span framework, and propose Linear Span Network (LSN) modified by Linear Span Units (LSUs), which minimize the reconstruction error of convolutional network. LSN further utilizes subspace linear span beside the feature linear span to increase the independence of convolutional features and the efficiency of feature integration, which enlarges the capability of fitting complex ground-truth. As a result, LSN can effectively suppress the cluttered backgrounds and reconstruct object skeletons. Experimental results validate the state-of-the-art performance of the proposed LSN.
A scalable convolutional neural network for task-specified scenarios via knowledge distillation
Jan 06, 2017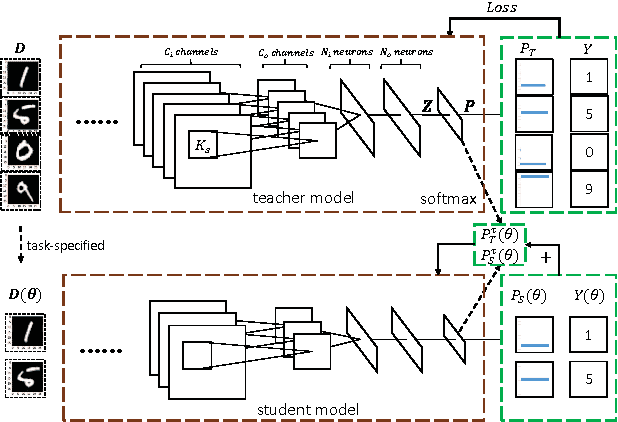
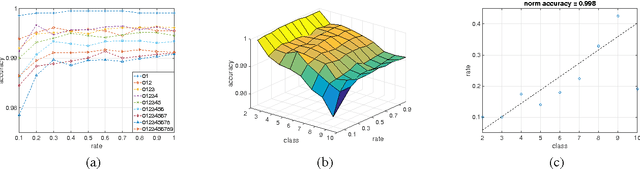
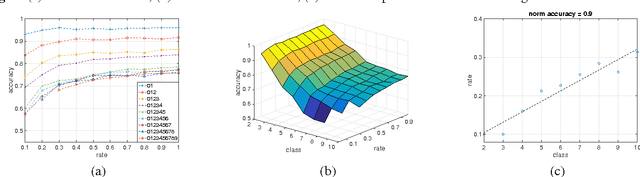
In this paper, we explore the redundancy in convolutional neural network, which scales with the complexity of vision tasks. Considering that many front-end visual systems are interested in only a limited range of visual targets, the removing of task-specified network redundancy can promote a wide range of potential applications. We propose a task-specified knowledge distillation algorithm to derive a simplified model with pre-set computation cost and minimized accuracy loss, which suits the resource constraint front-end systems well. Experiments on the MNIST and CIFAR10 datasets demonstrate the feasibility of the proposed approach as well as the existence of task-specified redundancy.