 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnimesh Mukherjee
Antitrust, Amazon, and Algorithmic Auditing
Mar 27, 2024
In digital markets, antitrust law and special regulations aim to ensure that markets remain competitive despite the dominating role that digital platforms play today in everyone's life. Unlike traditional markets, market participant behavior is easily observable in these markets. We present a series of empirical investigations into the extent to which Amazon engages in practices that are typically described as self-preferencing. We discuss how the computer science tools used in this paper can be used in a regulatory environment that is based on algorithmic auditing and requires regulating digital markets at scale.
On Zero-Shot Counterspeech Generation by LLMs
Mar 22, 2024With the emergence of numerous Large Language Models (LLM), the usage of such models in various Natural Language Processing (NLP) applications is increasing extensively. Counterspeech generation is one such key task where efforts are made to develop generative models by fine-tuning LLMs with hatespeech - counterspeech pairs, but none of these attempts explores the intrinsic properties of large language models in zero-shot settings. In this work, we present a comprehensive analysis of the performances of four LLMs namely GPT-2, DialoGPT, ChatGPT and FlanT5 in zero-shot settings for counterspeech generation, which is the first of its kind. For GPT-2 and DialoGPT, we further investigate the deviation in performance with respect to the sizes (small, medium, large) of the models. On the other hand, we propose three different prompting strategies for generating different types of counterspeech and analyse the impact of such strategies on the performance of the models. Our analysis shows that there is an improvement in generation quality for two datasets (17%), however the toxicity increase (25%) with increase in model size. Considering type of model, GPT-2 and FlanT5 models are significantly better in terms of counterspeech quality but also have high toxicity as compared to DialoGPT. ChatGPT are much better at generating counter speech than other models across all metrics. In terms of prompting, we find that our proposed strategies help in improving counter speech generation across all the models.
DistALANER: Distantly Supervised Active Learning Augmented Named Entity Recognition in the Open Source Software Ecosystem
Mar 11, 2024With the AI revolution in place, the trend for building automated systems to support professionals in different domains such as the open source software systems, healthcare systems, banking systems, transportation systems and many others have become increasingly prominent. A crucial requirement in the automation of support tools for such systems is the early identification of named entities, which serves as a foundation for developing specialized functionalities. However, due to the specific nature of each domain, different technical terminologies and specialized languages, expert annotation of available data becomes expensive and challenging. In light of these challenges, this paper proposes a novel named entity recognition (NER) technique specifically tailored for the open-source software systems. Our approach aims to address the scarcity of annotated software data by employing a comprehensive two-step distantly supervised annotation process. This process strategically leverages language heuristics, unique lookup tables, external knowledge sources, and an active learning approach. By harnessing these powerful techniques, we not only enhance model performance but also effectively mitigate the limitations associated with cost and the scarcity of expert annotators. It is noteworthy that our model significantly outperforms the state-of-the-art LLMs by a substantial margin. We also show the effectiveness of NER in the downstream task of relation extraction.
InfFeed: Influence Functions as a Feedback to Improve the Performance of Subjective Tasks
Mar 09, 2024Recently, influence functions present an apparatus for achieving explainability for deep neural models by quantifying the perturbation of individual train instances that might impact a test prediction. Our objectives in this paper are twofold. First we incorporate influence functions as a feedback into the model to improve its performance. Second, in a dataset extension exercise, using influence functions to automatically identify data points that have been initially `silver' annotated by some existing method and need to be cross-checked (and corrected) by annotators to improve the model performance. To meet these objectives, in this paper, we introduce InfFeed, which uses influence functions to compute the influential instances for a target instance. Toward the first objective, we adjust the label of the target instance based on its influencer(s) label. In doing this, InfFeed outperforms the state-of-the-art baselines (including LLMs) by a maximum macro F1-score margin of almost 4% for hate speech classification, 3.5% for stance classification, and 3% for irony and 2% for sarcasm detection. Toward the second objective we show that manually re-annotating only those silver annotated data points in the extension set that have a negative influence can immensely improve the model performance bringing it very close to the scenario where all the data points in the extension set have gold labels. This allows for huge reduction of the number of data points that need to be manually annotated since out of the silver annotated extension dataset, the influence function scheme picks up ~1/1000 points that need manual correction.
Cost-Performance Optimization for Processing Low-Resource Language Tasks Using Commercial LLMs
Mar 08, 2024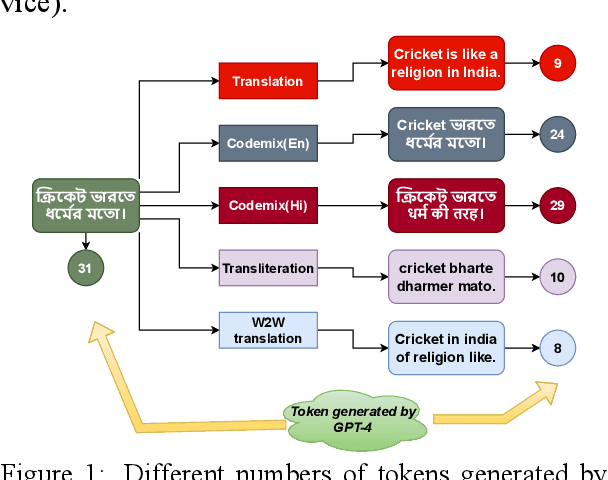
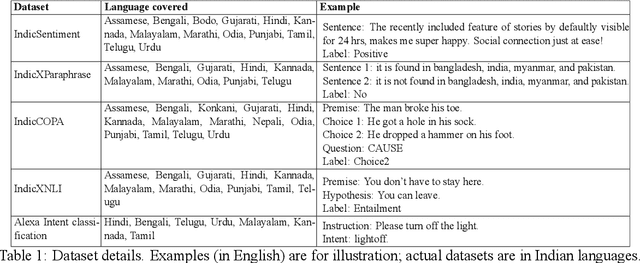
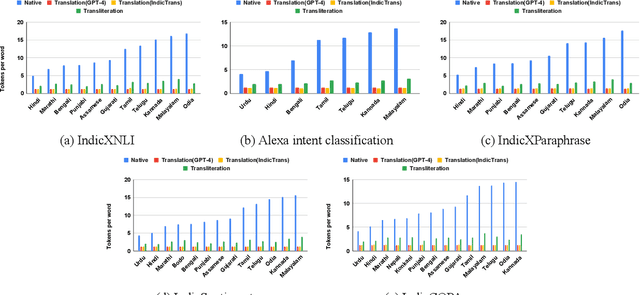
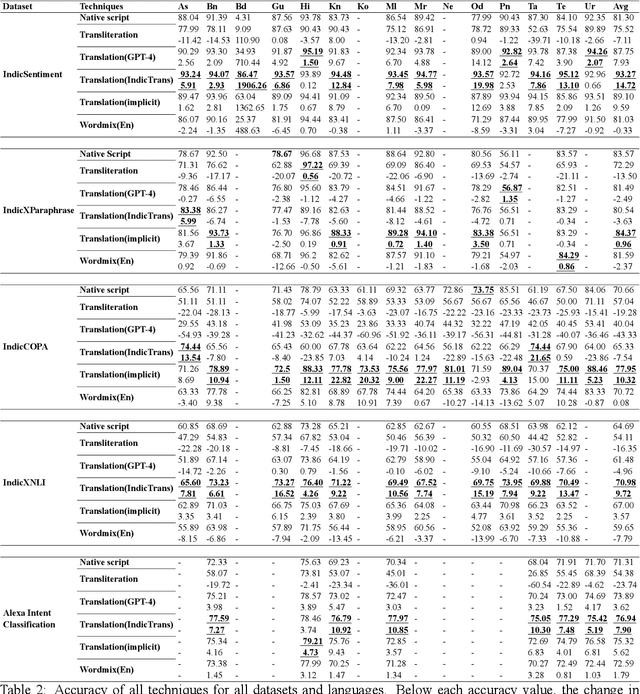
Large Language Models (LLMs) exhibit impressive zero/few-shot inference and generation quality for high-resource languages(HRLs). A few of them have been trained in low-resource languages (LRLs) and give decent performance. Owing to the prohibitive costs of training LLMs, they are usually used as a network service, with the client charged by the count of input and output tokens. The number of tokens strongly depends on the script and language, as well as the LLM's sub-word vocabulary. We show that LRLs are at a pricing disadvantage, because the well-known LLMs produce more tokens for LRLs than HRLs. This is because most currently popular LLMs are optimized for HRL vocabularies. Our objective is to level the playing field: reduce the cost of processing LRLs in contemporary LLMs while ensuring that predictive and generative qualities are not compromised. As means to reduce the number of tokens processed by the LLM, we consider code-mixing, translation, and transliteration of LRLs to HRLs. We perform an extensive study using the IndicXTREME dataset, covering 15 Indian languages, while using GPT-4 (one of the costliest LLM services released so far) as a commercial LLM. We observe and analyze interesting patterns involving token count, cost,and quality across a multitude of languages and tasks. We show that choosing the best policy to interact with the LLM can reduce cost by 90% while giving better or comparable performance, compared to communicating with the LLM in the original LRL.
How (un)ethical are instruction-centric responses of LLMs? Unveiling the vulnerabilities of safety guardrails to harmful queries
Mar 04, 2024In this study, we tackle a growing concern around the safety and ethical use of large language models (LLMs). Despite their potential, these models can be tricked into producing harmful or unethical content through various sophisticated methods, including 'jailbreaking' techniques and targeted manipulation. Our work zeroes in on a specific issue: to what extent LLMs can be led astray by asking them to generate responses that are instruction-centric such as a pseudocode, a program or a software snippet as opposed to vanilla text. To investigate this question, we introduce TechHazardQA, a dataset containing complex queries which should be answered in both text and instruction-centric formats (e.g., pseudocodes), aimed at identifying triggers for unethical responses. We query a series of LLMs -- Llama-2-13b, Llama-2-7b, Mistral-V2 and Mistral 8X7B -- and ask them to generate both text and instruction-centric responses. For evaluation we report the harmfulness score metric as well as judgements from GPT-4 and humans. Overall, we observe that asking LLMs to produce instruction-centric responses enhances the unethical response generation by ~2-38% across the models. As an additional objective, we investigate the impact of model editing using the ROME technique, which further increases the propensity for generating undesirable content. In particular, asking edited LLMs to generate instruction-centric responses further increases the unethical response generation by ~3-16% across the different models.