 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnindya Sarkar
Attacks on Node Attributes in Graph Neural Networks
Feb 19, 2024
Graphs are commonly used to model complex networks prevalent in modern social media and literacy applications. Our research investigates the vulnerability of these graphs through the application of feature based adversarial attacks, focusing on both decision-time attacks and poisoning attacks. In contrast to state-of-the-art models like Net Attack and Meta Attack, which target node attributes and graph structure, our study specifically targets node attributes. For our analysis, we utilized the text dataset Hellaswag and graph datasets Cora and CiteSeer, providing a diverse basis for evaluation. Our findings indicate that decision-time attacks using Projected Gradient Descent (PGD) are more potent compared to poisoning attacks that employ Mean Node Embeddings and Graph Contrastive Learning strategies. This provides insights for graph data security, pinpointing where graph-based models are most vulnerable and thereby informing the development of stronger defense mechanisms against such attacks.
A Partially Supervised Reinforcement Learning Framework for Visual Active Search
Oct 15, 2023



Visual active search (VAS) has been proposed as a modeling framework in which visual cues are used to guide exploration, with the goal of identifying regions of interest in a large geospatial area. Its potential applications include identifying hot spots of rare wildlife poaching activity, search-and-rescue scenarios, identifying illegal trafficking of weapons, drugs, or people, and many others. State of the art approaches to VAS include applications of deep reinforcement learning (DRL), which yield end-to-end search policies, and traditional active search, which combines predictions with custom algorithmic approaches. While the DRL framework has been shown to greatly outperform traditional active search in such domains, its end-to-end nature does not make full use of supervised information attained either during training, or during actual search, a significant limitation if search tasks differ significantly from those in the training distribution. We propose an approach that combines the strength of both DRL and conventional active search by decomposing the search policy into a prediction module, which produces a geospatial distribution of regions of interest based on task embedding and search history, and a search module, which takes the predictions and search history as input and outputs the search distribution. We develop a novel meta-learning approach for jointly learning the resulting combined policy that can make effective use of supervised information obtained both at training and decision time. Our extensive experiments demonstrate that the proposed representation and meta-learning frameworks significantly outperform state of the art in visual active search on several problem domains.
A Visual Active Search Framework for Geospatial Exploration
Nov 28, 2022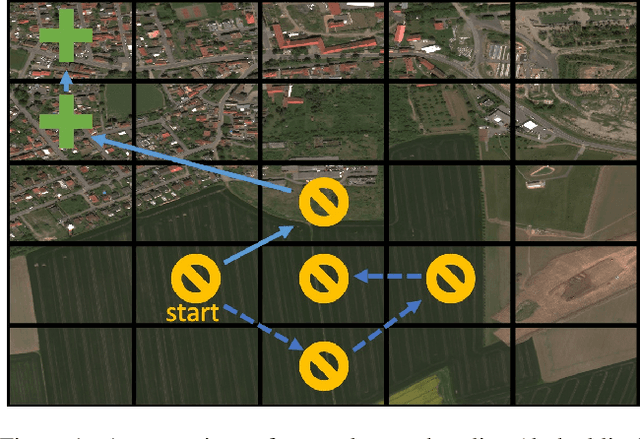
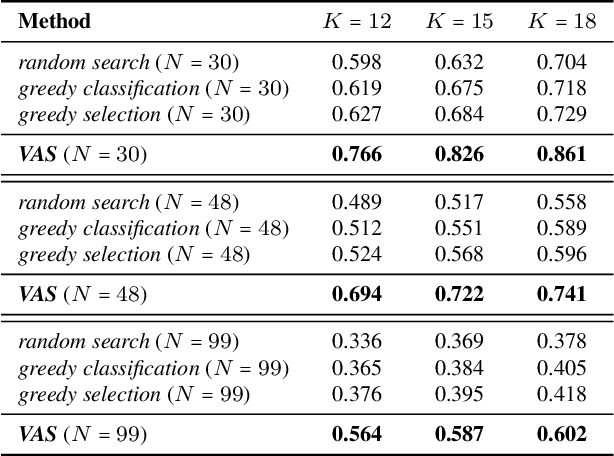
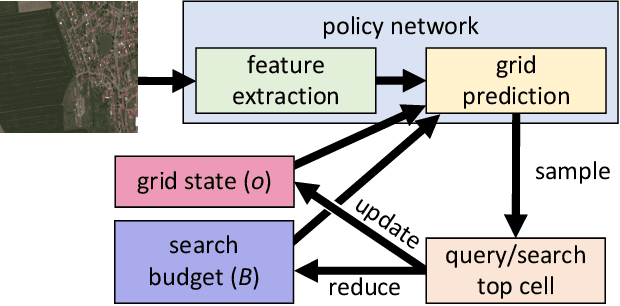
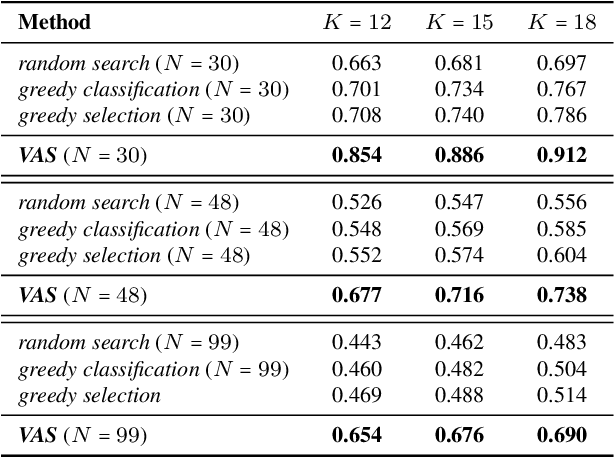
Many problems can be viewed as forms of geospatial search aided by aerial imagery, with examples ranging from detecting poaching activity to human trafficking. We model this class of problems in a visual active search (VAS) framework, which takes as input an image of a broad area, and aims to identify as many examples of a target object as possible. It does this through a limited sequence of queries, each of which verifies whether an example is present in a given region. We propose a reinforcement learning approach for VAS that leverages a collection of fully annotated search tasks as training data to learn a search policy, and combines features of the input image with a natural representation of active search state. Additionally, we propose domain adaptation techniques to improve the policy at decision time when training data is not fully reflective of the test-time distribution of VAS tasks. Through extensive experiments on several satellite imagery datasets, we show that the proposed approach significantly outperforms several strong baselines. Code and data will be made public.
Reward Delay Attacks on Deep Reinforcement Learning
Sep 08, 2022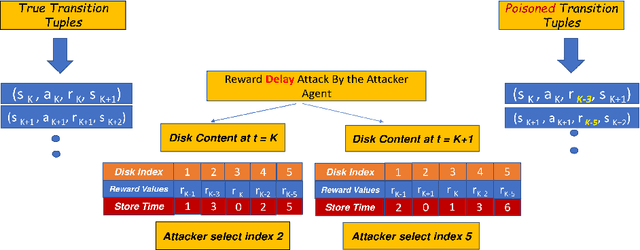
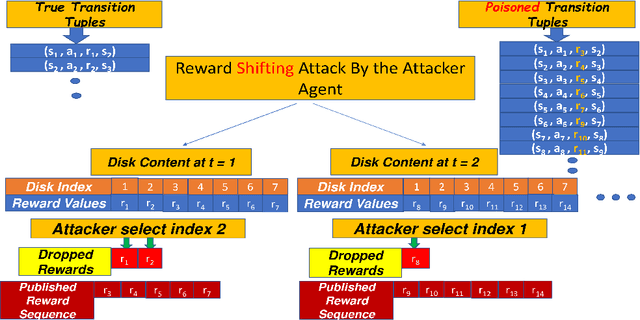
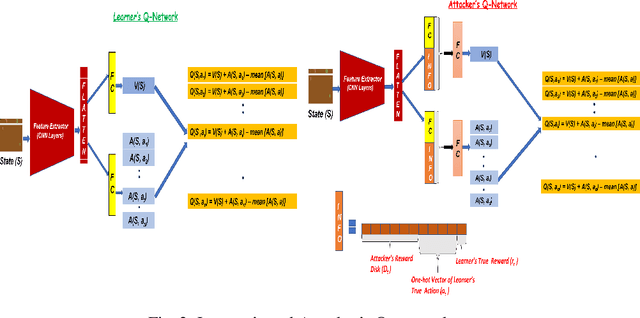
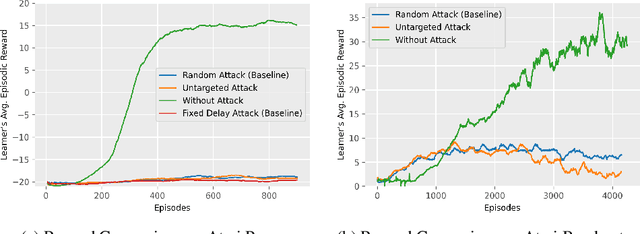
Most reinforcement learning algorithms implicitly assume strong synchrony. We present novel attacks targeting Q-learning that exploit a vulnerability entailed by this assumption by delaying the reward signal for a limited time period. We consider two types of attack goals: targeted attacks, which aim to cause a target policy to be learned, and untargeted attacks, which simply aim to induce a policy with a low reward. We evaluate the efficacy of the proposed attacks through a series of experiments. Our first observation is that reward-delay attacks are extremely effective when the goal is simply to minimize reward. Indeed, we find that even naive baseline reward-delay attacks are also highly successful in minimizing the reward. Targeted attacks, on the other hand, are more challenging, although we nevertheless demonstrate that the proposed approaches remain highly effective at achieving the attacker's targets. In addition, we introduce a second threat model that captures a minimal mitigation that ensures that rewards cannot be used out of sequence. We find that this mitigation remains insufficient to ensure robustness to attacks that delay, but preserve the order, of rewards.
How Powerful are K-hop Message Passing Graph Neural Networks
May 26, 2022



The most popular design paradigm for Graph Neural Networks (GNNs) is 1-hop message passing -- aggregating features from 1-hop neighbors repeatedly. However, the expressive power of 1-hop message passing is bounded by the Weisfeiler-Lehman (1-WL) test. Recently, researchers extended 1-hop message passing to K-hop message passing by aggregating information from K-hop neighbors of nodes simultaneously. However, there is no work on analyzing the expressive power of K-hop message passing. In this work, we theoretically characterize the expressive power of K-hop message passing. Specifically, we first formally differentiate two kinds of kernels of K-hop message passing which are often misused in previous works. We then characterize the expressive power of K-hop message passing by showing that it is more powerful than 1-hop message passing. Despite the higher expressive power, we show that K-hop message passing still cannot distinguish some simple regular graphs. To further enhance its expressive power, we introduce a KP-GNN framework, which improves K-hop message passing by leveraging the peripheral subgraph information in each hop. We prove that KP-GNN can distinguish almost all regular graphs including some distance regular graphs which could not be distinguished by previous distance encoding methods. Experimental results verify the expressive power and effectiveness of KP-GNN. KP-GNN achieves competitive results across all benchmark datasets.
Get Fooled for the Right Reason: Improving Adversarial Robustness through a Teacher-guided Curriculum Learning Approach
Oct 30, 2021



Current SOTA adversarially robust models are mostly based on adversarial training (AT) and differ only by some regularizers either at inner maximization or outer minimization steps. Being repetitive in nature during the inner maximization step, they take a huge time to train. We propose a non-iterative method that enforces the following ideas during training. Attribution maps are more aligned to the actual object in the image for adversarially robust models compared to naturally trained models. Also, the allowed set of pixels to perturb an image (that changes model decision) should be restricted to the object pixels only, which reduces the attack strength by limiting the attack space. Our method achieves significant performance gains with a little extra effort (10-20%) over existing AT models and outperforms all other methods in terms of adversarial as well as natural accuracy. We have performed extensive experimentation with CIFAR-10, CIFAR-100, and TinyImageNet datasets and reported results against many popular strong adversarial attacks to prove the effectiveness of our method.
Inducing Semantic Grouping of Latent Concepts for Explanations: An Ante-Hoc Approach
Aug 25, 2021



Self-explainable deep models are devised to represent the hidden concepts in the dataset without requiring any posthoc explanation generation technique. We worked with one of such models motivated by explicitly representing the classifier function as a linear function and showed that by exploiting probabilistic latent and properly modifying different parts of the model can result better explanation as well as provide superior predictive performance. Apart from standard visualization techniques, we proposed a new technique which can strengthen human understanding towards hidden concepts. We also proposed a technique of using two different self-supervision techniques to extract meaningful concepts related to the type of self-supervision considered and achieved significant performance boost. The most important aspect of our method is that it works nicely in a low data regime and reaches the desired accuracy in a few number of epochs. We reported exhaustive results with CIFAR10, CIFAR100, and AWA2 datasets to show effect of our method with moderate and relatively complex datasets.
Enhanced Regularizers for Attributional Robustness
Dec 28, 2020



Deep neural networks are the default choice of learning models for computer vision tasks. Extensive work has been carried out in recent years on explaining deep models for vision tasks such as classification. However, recent work has shown that it is possible for these models to produce substantially different attribution maps even when two very similar images are given to the network, raising serious questions about trustworthiness. To address this issue, we propose a robust attribution training strategy to improve attributional robustness of deep neural networks. Our method carefully analyzes the requirements for attributional robustness and introduces two new regularizers that preserve a model's attribution map during attacks. Our method surpasses state-of-the-art attributional robustness methods by a margin of approximately 3% to 9% in terms of attribution robustness measures on several datasets including MNIST, FMNIST, Flower and GTSRB.
Enforcing Linearity in DNN succours Robustness and Adversarial Image Generation
Oct 21, 2019



Recent studies on the adversarial vulnerability of neural networks have shown that models trained with the objective of minimizing an upper bound on the worst-case loss over all possible adversarial perturbations improve robustness against adversarial attacks. Beside exploiting adversarial training framework, we show that by enforcing a Deep Neural Network (DNN) to be linear in transformed input and feature space improves robustness significantly. We also demonstrate that by augmenting the objective function with Local Lipschitz regularizer boost robustness of the model further. Our method outperforms most sophisticated adversarial training methods and achieves state of the art adversarial accuracy on MNIST, CIFAR10 and SVHN dataset. In this paper, we also propose a novel adversarial image generation method by leveraging Inverse Representation Learning and Linearity aspect of an adversarially trained deep neural network classifier.
Improving Robustness of time series classifier with Neural ODE guided gradient based data augmentation
Oct 15, 2019



Exploring adversarial attack vectors and studying their effects on machine learning algorithms has been of interest to researchers. Deep neural networks working with time series data have received lesser interest compared to their image counterparts in this context. In a recent finding, it has been revealed that current state-of-the-art deep learning time series classifiers are vulnerable to adversarial attacks. In this paper, we introduce two local gradient based and one spectral density based time series data augmentation techniques. We show that a model trained with data obtained using our techniques obtains state-of-the-art classification accuracy on various time series benchmarks. In addition, it improves the robustness of the model against some of the most common corruption techniques,such as Fast Gradient Sign Method (FGSM) and Basic Iterative Method (BIM).