 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAparna Garimella
IndiBias: A Benchmark Dataset to Measure Social Biases in Language Models for Indian Context
Apr 03, 2024




The pervasive influence of social biases in language data has sparked the need for benchmark datasets that capture and evaluate these biases in Large Language Models (LLMs). Existing efforts predominantly focus on English language and the Western context, leaving a void for a reliable dataset that encapsulates India's unique socio-cultural nuances. To bridge this gap, we introduce IndiBias, a comprehensive benchmarking dataset designed specifically for evaluating social biases in the Indian context. We filter and translate the existing CrowS-Pairs dataset to create a benchmark dataset suited to the Indian context in Hindi language. Additionally, we leverage LLMs including ChatGPT and InstructGPT to augment our dataset with diverse societal biases and stereotypes prevalent in India. The included bias dimensions encompass gender, religion, caste, age, region, physical appearance, and occupation. We also build a resource to address intersectional biases along three intersectional dimensions. Our dataset contains 800 sentence pairs and 300 tuples for bias measurement across different demographics. The dataset is available in English and Hindi, providing a size comparable to existing benchmark datasets. Furthermore, using IndiBias we compare ten different language models on multiple bias measurement metrics. We observed that the language models exhibit more bias across a majority of the intersectional groups.
FABLES: Evaluating faithfulness and content selection in book-length summarization
Apr 01, 2024While long-context large language models (LLMs) can technically summarize book-length documents (>100K tokens), the length and complexity of the documents have so far prohibited evaluations of input-dependent aspects like faithfulness. In this paper, we conduct the first large-scale human evaluation of faithfulness and content selection on LLM-generated summaries of fictional books. Our study mitigates the issue of data contamination by focusing on summaries of books published in 2023 or 2024, and we hire annotators who have fully read each book prior to the annotation task to minimize cost and cognitive burden. We collect FABLES, a dataset of annotations on 3,158 claims made in LLM-generated summaries of 26 books, at a cost of $5.2K USD, which allows us to rank LLM summarizers based on faithfulness: Claude-3-Opus significantly outperforms all closed-source LLMs, while the open-source Mixtral is on par with GPT-3.5-Turbo. An analysis of the annotations reveals that most unfaithful claims relate to events and character states, and they generally require indirect reasoning over the narrative to invalidate. While LLM-based auto-raters have proven reliable for factuality and coherence in other settings, we implement several LLM raters of faithfulness and find that none correlates strongly with human annotations, especially with regard to detecting unfaithful claims. Our experiments suggest that detecting unfaithful claims is an important future direction not only for summarization evaluation but also as a testbed for long-context understanding. Finally, we move beyond faithfulness by exploring content selection errors in book-length summarization: we develop a typology of omission errors related to crucial narrative elements and also identify a systematic over-emphasis on events occurring towards the end of the book.
"Kelly is a Warm Person, Joseph is a Role Model": Gender Biases in LLM-Generated Reference Letters
Oct 28, 2023
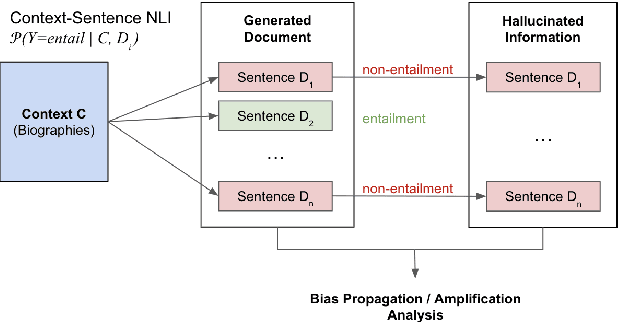
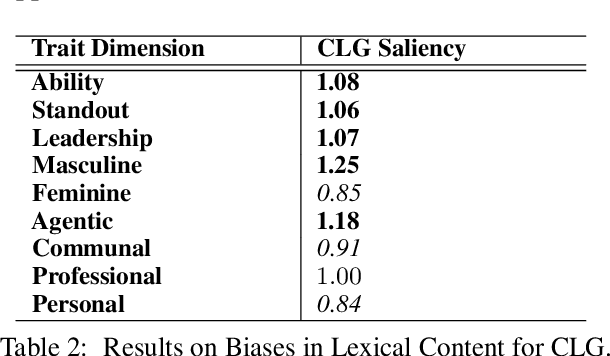
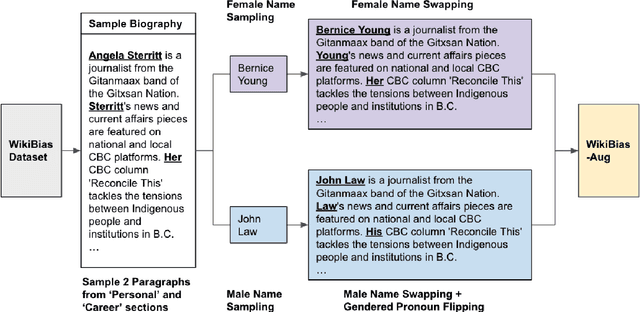
Large Language Models (LLMs) have recently emerged as an effective tool to assist individuals in writing various types of content, including professional documents such as recommendation letters. Though bringing convenience, this application also introduces unprecedented fairness concerns. Model-generated reference letters might be directly used by users in professional scenarios. If underlying biases exist in these model-constructed letters, using them without scrutinization could lead to direct societal harms, such as sabotaging application success rates for female applicants. In light of this pressing issue, it is imminent and necessary to comprehensively study fairness issues and associated harms in this real-world use case. In this paper, we critically examine gender biases in LLM-generated reference letters. Drawing inspiration from social science findings, we design evaluation methods to manifest biases through 2 dimensions: (1) biases in language style and (2) biases in lexical content. We further investigate the extent of bias propagation by analyzing the hallucination bias of models, a term that we define to be bias exacerbation in model-hallucinated contents. Through benchmarking evaluation on 2 popular LLMs- ChatGPT and Alpaca, we reveal significant gender biases in LLM-generated recommendation letters. Our findings not only warn against using LLMs for this application without scrutinization, but also illuminate the importance of thoroughly studying hidden biases and harms in LLM-generated professional documents.
KNN-LM Does Not Improve Open-ended Text Generation
May 24, 2023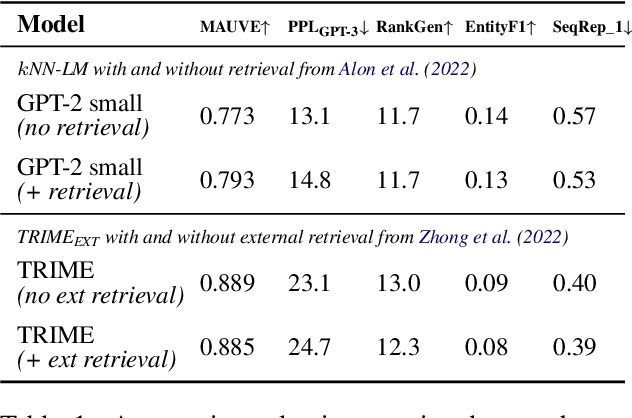
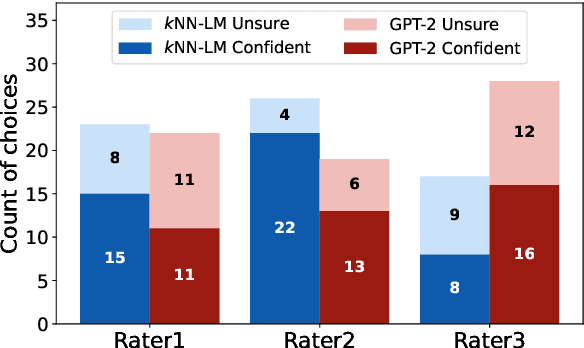
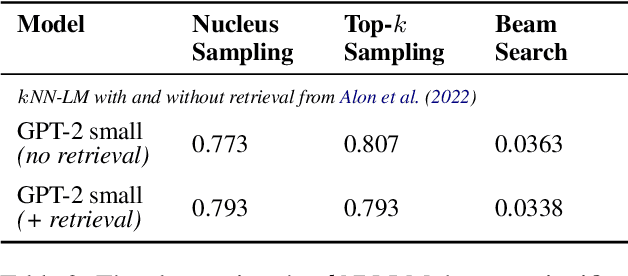
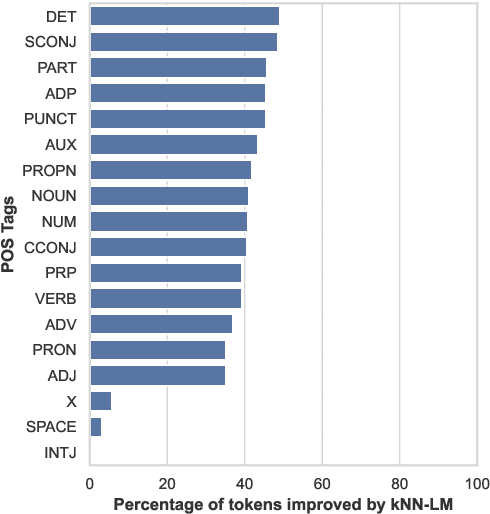
In this paper, we study the generation quality of interpolation-based retrieval-augmented language models (LMs). These methods, best exemplified by the KNN-LM, interpolate the LM's predicted distribution of the next word with a distribution formed from the most relevant retrievals for a given prefix. While the KNN-LM and related methods yield impressive decreases in perplexity, we discover that they do not exhibit corresponding improvements in open-ended generation quality, as measured by both automatic evaluation metrics (e.g., MAUVE) and human evaluations. Digging deeper, we find that interpolating with a retrieval distribution actually increases perplexity compared to a baseline Transformer LM for the majority of tokens in the WikiText-103 test set, even though the overall perplexity is lower due to a smaller number of tokens for which perplexity dramatically decreases after interpolation. However, when decoding a long sequence at inference time, significant improvements on this smaller subset of tokens are washed out by slightly worse predictions on most tokens. Furthermore, we discover that the entropy of the retrieval distribution increases faster than that of the base LM as the generated sequence becomes longer, which indicates that retrieval is less reliable when using model-generated text as queries (i.e., is subject to exposure bias). We hope that our analysis spurs future work on improved decoding algorithms and interpolation strategies for retrieval-augmented language models.
InteractiveIE: Towards Assessing the Strength of Human-AI Collaboration in Improving the Performance of Information Extraction
May 24, 2023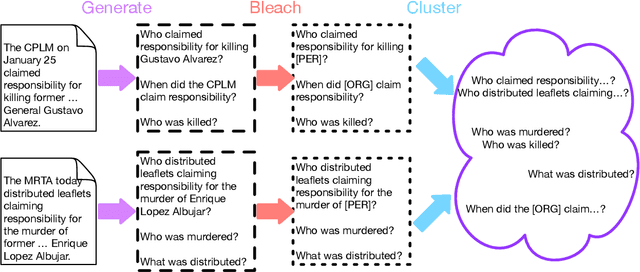

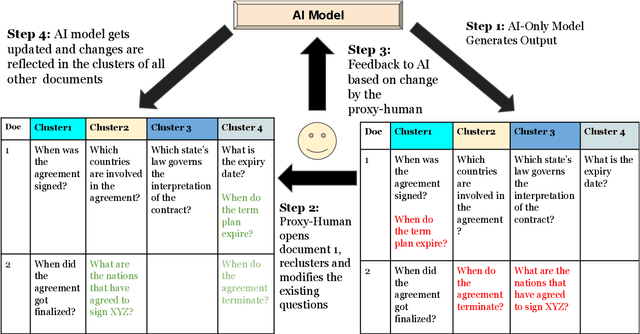
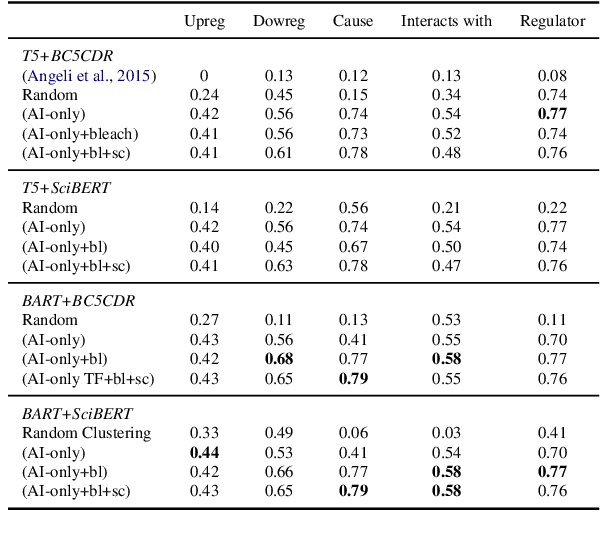
Learning template based information extraction from documents is a crucial yet difficult task. Prior template-based IE approaches assume foreknowledge of the domain templates; however, real-world IE do not have pre-defined schemas and it is a figure-out-as you go phenomena. To quickly bootstrap templates in a real-world setting, we need to induce template slots from documents with zero or minimal supervision. Since the purpose of question answering intersect with the goal of information extraction, we use automatic question generation to induce template slots from the documents and investigate how a tiny amount of a proxy human-supervision on-the-fly (termed as InteractiveIE) can further boost the performance. Extensive experiments on biomedical and legal documents, where obtaining training data is expensive, reveal encouraging trends of performance improvement using InteractiveIE over AI-only baseline.
Investigating Strategies for Clause Recommendation
Jan 21, 2023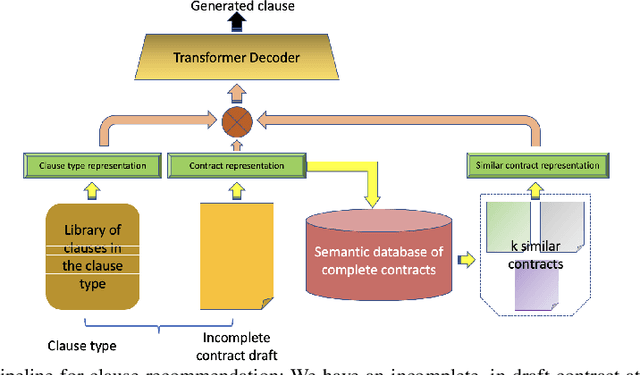
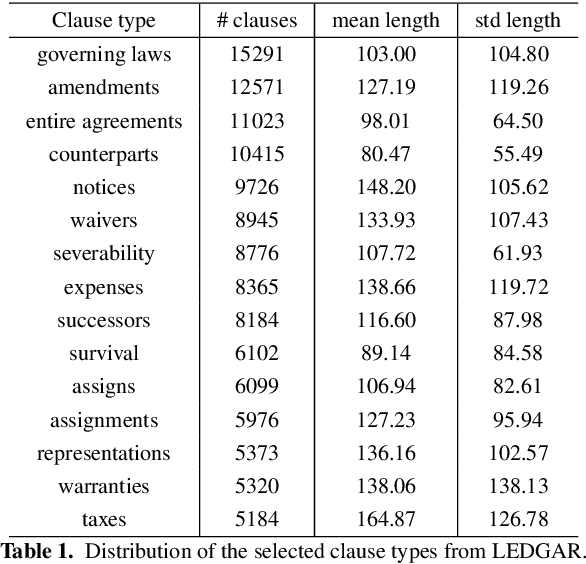
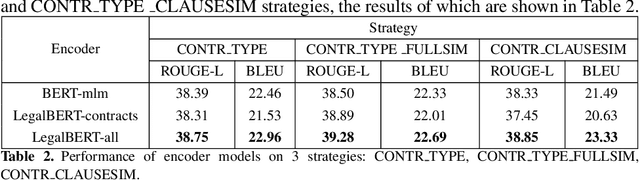

Clause recommendation is the problem of recommending a clause to a legal contract, given the context of the contract in question and the clause type to which the clause should belong. With not much prior work being done toward the generation of legal contracts, this problem was proposed as a first step toward the bigger problem of contract generation. As an open-ended text generation problem, the distinguishing characteristics of this problem lie in the nature of legal language as a sublanguage and the considerable similarity of textual content within the clauses of a specific type. This similarity aspect in legal clauses drives us to investigate the importance of similar contracts' representation for recommending clauses. In our work, we experiment with generating clauses for 15 commonly occurring clause types in contracts expanding upon the previous work on this problem and analyzing clause recommendations in varying settings using information derived from similar contracts.
* Published in Legal Knowledge and Information Systems (JURIX) 2022. (10 pages, 4 figures)
Graph-based Keyword Planning for Legal Clause Generation from Topics
Jan 07, 2023

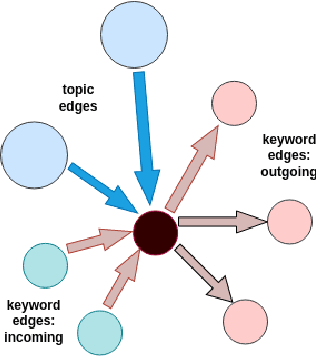
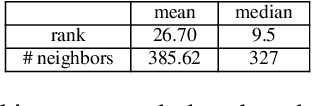
Generating domain-specific content such as legal clauses based on minimal user-provided information can be of significant benefit in automating legal contract generation. In this paper, we propose a controllable graph-based mechanism that can generate legal clauses using only the topic or type of the legal clauses. Our pipeline consists of two stages involving a graph-based planner followed by a clause generator. The planner outlines the content of a legal clause as a sequence of keywords in the order of generic to more specific clause information based on the input topic using a controllable graph-based mechanism. The generation stage takes in a given plan and generates a clause. The pipeline consists of a graph-based planner followed by text generation. We illustrate the effectiveness of our proposed two-stage approach on a broad set of clause topics in contracts.
What to Read in a Contract? Party-Specific Summarization of Important Obligations, Entitlements, and Prohibitions in Legal Documents
Dec 19, 2022



Legal contracts, such as employment or lease agreements, are important documents as they govern the obligations and entitlements of the various contracting parties. However, these documents are typically long and written in legalese resulting in lots of manual hours spent in understanding them. In this paper, we address the task of summarizing legal contracts for each of the contracting parties, to enable faster reviewing and improved understanding of them. Specifically, we collect a dataset consisting of pairwise importance comparison annotations by legal experts for ~293K sentence pairs from lease agreements. We propose a novel extractive summarization system to automatically produce a summary consisting of the most important obligations, entitlements, and prohibitions in a contract. It consists of two modules: (1) a content categorize to identify sentences containing each of the categories (i.e., obligation, entitlement, and prohibition) for a party, and (2) an importance ranker to compare the importance among sentences of each category for a party to obtain a ranked list. The final summary is produced by selecting the most important sentences of a category for each of the parties. We demonstrate the effectiveness of our proposed system by comparing it against several text ranking baselines via automatic and human evaluation.
Agent-Specific Deontic Modality Detection in Legal Language
Nov 23, 2022

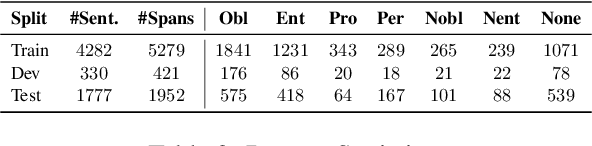

Legal documents are typically long and written in legalese, which makes it particularly difficult for laypeople to understand their rights and duties. While natural language understanding technologies can be valuable in supporting such understanding in the legal domain, the limited availability of datasets annotated for deontic modalities in the legal domain, due to the cost of hiring experts and privacy issues, is a bottleneck. To this end, we introduce, LEXDEMOD, a corpus of English contracts annotated with deontic modality expressed with respect to a contracting party or agent along with the modal triggers. We benchmark this dataset on two tasks: (i) agent-specific multi-label deontic modality classification, and (ii) agent-specific deontic modality and trigger span detection using Transformer-based (Vaswani et al., 2017) language models. Transfer learning experiments show that the linguistic diversity of modal expressions in LEXDEMOD generalizes reasonably from lease to employment and rental agreements. A small case study indicates that a model trained on LEXDEMOD can detect red flags with high recall. We believe our work offers a new research direction for deontic modality detection in the legal domain.
CLAUSEREC: A Clause Recommendation Framework for AI-aided Contract Authoring
Oct 26, 2021


Contracts are a common type of legal document that frequent in several day-to-day business workflows. However, there has been very limited NLP research in processing such documents, and even lesser in generating them. These contracts are made up of clauses, and the unique nature of these clauses calls for specific methods to understand and generate such documents. In this paper, we introduce the task of clause recommendation, asa first step to aid and accelerate the author-ing of contract documents. We propose a two-staged pipeline to first predict if a specific clause type is relevant to be added in a contract, and then recommend the top clauses for the given type based on the contract context. We pretrain BERT on an existing library of clauses with two additional tasks and use it for our prediction and recommendation. We experiment with classification methods and similarity-based heuristics for clause relevance prediction, and generation-based methods for clause recommendation, and evaluate the results from various methods on several clause types. We provide analyses on the results, and further outline the advantages and limitations of the various methods for this line of research.