 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVasudeva Varma
MetaCheckGPT -- A Multi-task Hallucination Detector Using LLM Uncertainty and Meta-models
Apr 11, 2024
Hallucinations in large language models (LLMs) have recently become a significant problem. A recent effort in this direction is a shared task at Semeval 2024 Task 6, SHROOM, a Shared-task on Hallucinations and Related Observable Overgeneration Mistakes. This paper describes our winning solution ranked 1st and 2nd in the 2 sub-tasks of model agnostic and model aware tracks respectively. We propose a meta-regressor framework of LLMs for model evaluation and integration that achieves the highest scores on the leaderboard. We also experiment with various transformer-based models and black box methods like ChatGPT, Vectara, and others. In addition, we perform an error analysis comparing GPT4 against our best model which shows the limitations of the former.
Can LLMs Generate Architectural Design Decisions? -An Exploratory Empirical study
Mar 04, 2024



Architectural Knowledge Management (AKM) involves the organized handling of information related to architectural decisions and design within a project or organization. An essential artifact of AKM is the Architecture Decision Records (ADR), which documents key design decisions. ADRs are documents that capture decision context, decision made and various aspects related to a design decision, thereby promoting transparency, collaboration, and understanding. Despite their benefits, ADR adoption in software development has been slow due to challenges like time constraints and inconsistent uptake. Recent advancements in Large Language Models (LLMs) may help bridge this adoption gap by facilitating ADR generation. However, the effectiveness of LLM for ADR generation or understanding is something that has not been explored. To this end, in this work, we perform an exploratory study that aims to investigate the feasibility of using LLM for the generation of ADRs given the decision context. In our exploratory study, we utilize GPT and T5-based models with 0-shot, few-shot, and fine-tuning approaches to generate the Decision of an ADR given its Context. Our results indicate that in a 0-shot setting, state-of-the-art models such as GPT-4 generate relevant and accurate Design Decisions, although they fall short of human-level performance. Additionally, we observe that more cost-effective models like GPT-3.5 can achieve similar outcomes in a few-shot setting, and smaller models such as Flan-T5 can yield comparable results after fine-tuning. To conclude, this exploratory study suggests that LLM can generate Design Decisions, but further research is required to attain human-level generation and establish standardized widespread adoption.
Multilingual Bias Detection and Mitigation for Indian Languages
Dec 23, 2023Lack of diverse perspectives causes neutrality bias in Wikipedia content leading to millions of worldwide readers getting exposed by potentially inaccurate information. Hence, neutrality bias detection and mitigation is a critical problem. Although previous studies have proposed effective solutions for English, no work exists for Indian languages. First, we contribute two large datasets, mWikiBias and mWNC, covering 8 languages, for the bias detection and mitigation tasks respectively. Next, we investigate the effectiveness of popular multilingual Transformer-based models for the two tasks by modeling detection as a binary classification problem and mitigation as a style transfer problem. We make the code and data publicly available.
Neural models for Factual Inconsistency Classification with Explanations
Jun 15, 2023
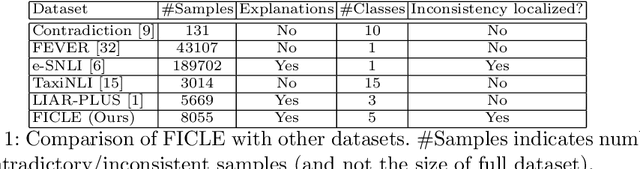

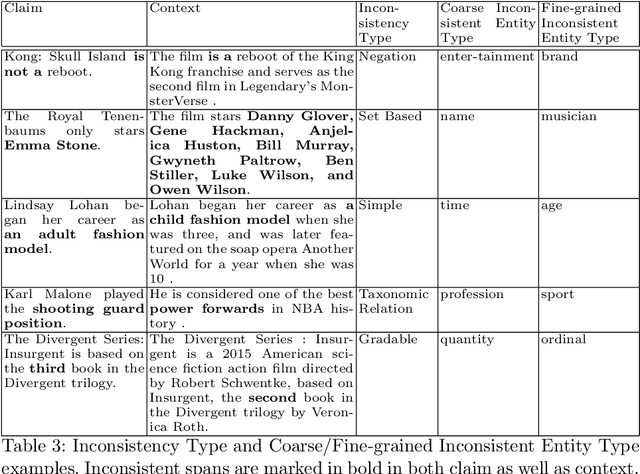
Factual consistency is one of the most important requirements when editing high quality documents. It is extremely important for automatic text generation systems like summarization, question answering, dialog modeling, and language modeling. Still, automated factual inconsistency detection is rather under-studied. Existing work has focused on (a) finding fake news keeping a knowledge base in context, or (b) detecting broad contradiction (as part of natural language inference literature). However, there has been no work on detecting and explaining types of factual inconsistencies in text, without any knowledge base in context. In this paper, we leverage existing work in linguistics to formally define five types of factual inconsistencies. Based on this categorization, we contribute a novel dataset, FICLE (Factual Inconsistency CLassification with Explanation), with ~8K samples where each sample consists of two sentences (claim and context) annotated with type and span of inconsistency. When the inconsistency relates to an entity type, it is labeled as well at two levels (coarse and fine-grained). Further, we leverage this dataset to train a pipeline of four neural models to predict inconsistency type with explanations, given a (claim, context) sentence pair. Explanations include inconsistent claim fact triple, inconsistent context span, inconsistent claim component, coarse and fine-grained inconsistent entity types. The proposed system first predicts inconsistent spans from claim and context; and then uses them to predict inconsistency types and inconsistent entity types (when inconsistency is due to entities). We experiment with multiple Transformer-based natural language classification as well as generative models, and find that DeBERTa performs the best. Our proposed methods provide a weighted F1 of ~87% for inconsistency type classification across the five classes.
LLM-RM at SemEval-2023 Task 2: Multilingual Complex NER using XLM-RoBERTa
May 05, 2023



Named Entity Recognition(NER) is a task of recognizing entities at a token level in a sentence. This paper focuses on solving NER tasks in a multilingual setting for complex named entities. Our team, LLM-RM participated in the recently organized SemEval 2023 task, Task 2: MultiCoNER II,Multilingual Complex Named Entity Recognition. We approach the problem by leveraging cross-lingual representation provided by fine-tuning XLM-Roberta base model on datasets of all of the 12 languages provided -- Bangla, Chinese, English, Farsi, French, German, Hindi, Italian, Portuguese, Spanish, Swedish and Ukrainian
Summarizing Indian Languages using Multilingual Transformers based Models
Mar 29, 2023



With the advent of multilingual models like mBART, mT5, IndicBART etc., summarization in low resource Indian languages is getting a lot of attention now a days. But still the number of datasets is low in number. In this work, we (Team HakunaMatata) study how these multilingual models perform on the datasets which have Indian languages as source and target text while performing summarization. We experimented with IndicBART and mT5 models to perform the experiments and report the ROUGE-1, ROUGE-2, ROUGE-3 and ROUGE-4 scores as a performance metric.
XWikiGen: Cross-lingual Summarization for Encyclopedic Text Generation in Low Resource Languages
Mar 22, 2023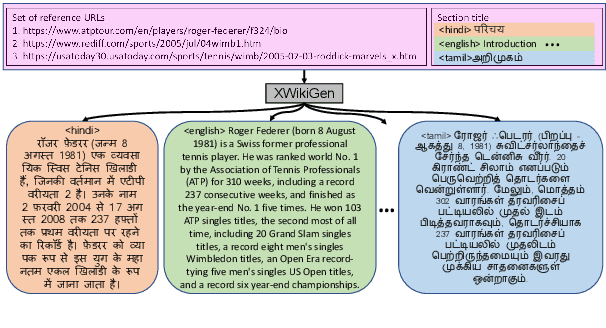
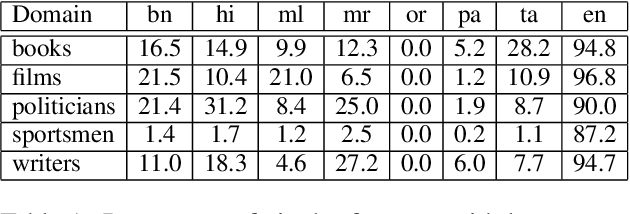
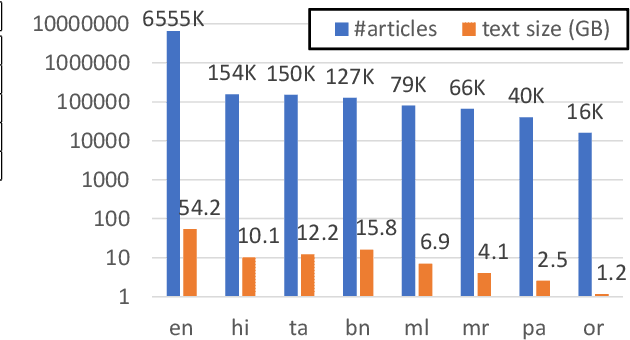

Lack of encyclopedic text contributors, especially on Wikipedia, makes automated text generation for \emph{low resource (LR) languages} a critical problem. Existing work on Wikipedia text generation has focused on \emph{English only} where English reference articles are summarized to generate English Wikipedia pages. But, for low-resource languages, the scarcity of reference articles makes monolingual summarization ineffective in solving this problem. Hence, in this work, we propose \task{}, which is the task of cross-lingual multi-document summarization of text from multiple reference articles, written in various languages, to generate Wikipedia-style text. Accordingly, we contribute a benchmark dataset, \data{}, spanning $\sim$69K Wikipedia articles covering five domains and eight languages. We harness this dataset to train a two-stage system where the input is a set of citations and a section title and the output is a section-specific LR summary. The proposed system is based on a novel idea of neural unsupervised extractive summarization to coarsely identify salient information followed by a neural abstractive model to generate the section-specific text. Extensive experiments show that multi-domain training is better than the multi-lingual setup on average.
GrapeQA: GRaph Augmentation and Pruning to Enhance Question-Answering
Mar 22, 2023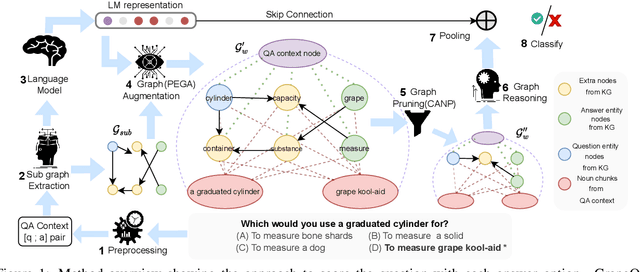
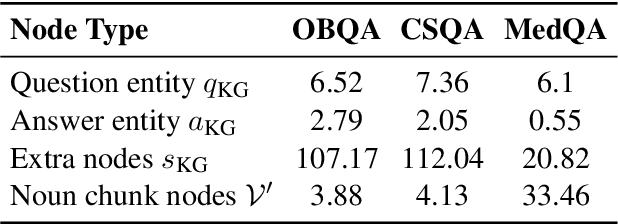
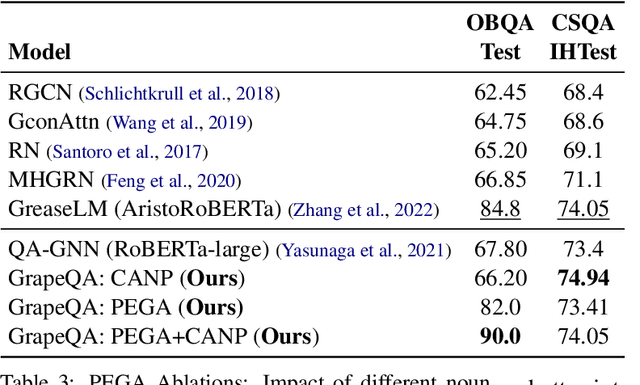

Commonsense question-answering (QA) methods combine the power of pre-trained Language Models (LM) with the reasoning provided by Knowledge Graphs (KG). A typical approach collects nodes relevant to the QA pair from a KG to form a Working Graph (WG) followed by reasoning using Graph Neural Networks(GNNs). This faces two major challenges: (i) it is difficult to capture all the information from the QA in the WG, and (ii) the WG contains some irrelevant nodes from the KG. To address these, we propose GrapeQA with two simple improvements on the WG: (i) Prominent Entities for Graph Augmentation identifies relevant text chunks from the QA pair and augments the WG with corresponding latent representations from the LM, and (ii) Context-Aware Node Pruning removes nodes that are less relevant to the QA pair. We evaluate our results on OpenBookQA, CommonsenseQA and MedQA-USMLE and see that GrapeQA shows consistent improvements over its LM + KG predecessor (QA-GNN in particular) and large improvements on OpenBookQA.
Massively Multilingual Language Models for Cross Lingual Fact Extraction from Low Resource Indian Languages
Feb 09, 2023



Massive knowledge graphs like Wikidata attempt to capture world knowledge about multiple entities. Recent approaches concentrate on automatically enriching these KGs from text. However a lot of information present in the form of natural text in low resource languages is often missed out. Cross Lingual Information Extraction aims at extracting factual information in the form of English triples from low resource Indian Language text. Despite its massive potential, progress made on this task is lagging when compared to Monolingual Information Extraction. In this paper, we propose the task of Cross Lingual Fact Extraction(CLFE) from text and devise an end-to-end generative approach for the same which achieves an overall F1 score of 77.46.
Investigating Strategies for Clause Recommendation
Jan 21, 2023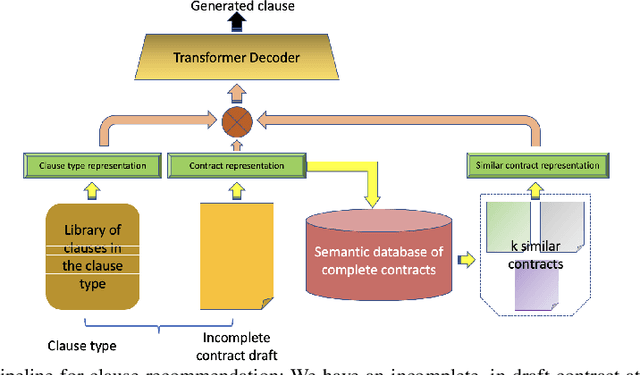
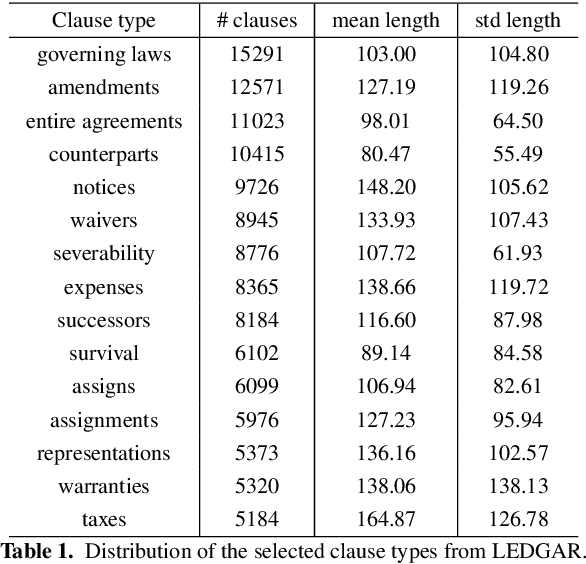
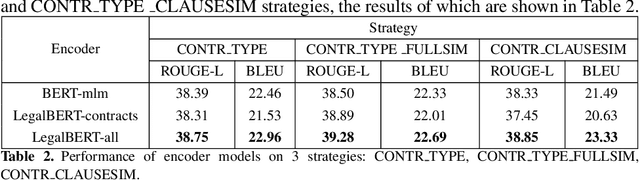

Clause recommendation is the problem of recommending a clause to a legal contract, given the context of the contract in question and the clause type to which the clause should belong. With not much prior work being done toward the generation of legal contracts, this problem was proposed as a first step toward the bigger problem of contract generation. As an open-ended text generation problem, the distinguishing characteristics of this problem lie in the nature of legal language as a sublanguage and the considerable similarity of textual content within the clauses of a specific type. This similarity aspect in legal clauses drives us to investigate the importance of similar contracts' representation for recommending clauses. In our work, we experiment with generating clauses for 15 commonly occurring clause types in contracts expanding upon the previous work on this problem and analyzing clause recommendations in varying settings using information derived from similar contracts.
* Published in Legal Knowledge and Information Systems (JURIX) 2022. (10 pages, 4 figures)