 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArielle Carr
Implementing Recycling Methods for Linear Systems in Python with an Application to Multiple Objective Optimization
Feb 25, 2024
Sequences of linear systems arise in the predictor-corrector method when computing the Pareto front for multi-objective optimization. Rather than discarding information generated when solving one system, it may be advantageous to recycle information for subsequent systems. To accomplish this, we seek to reduce the overall cost of computation when solving linear systems using common recycling methods. In this work, we assessed the performance of recycling minimum residual (RMINRES) method along with a map between coefficient matrices. For these methods to be fully integrated into the software used in Enouen et al. (2022), there must be working version of each in both Python and PyTorch. Herein, we discuss the challenges we encountered and solutions undertaken (and some ongoing) when computing efficient Python implementations of these recycling strategies. The goal of this project was to implement RMINRES in Python and PyTorch and add it to the established Pareto front code to reduce computational cost. Additionally, we wanted to implement the sparse approximate maps code in Python and PyTorch, so that it can be parallelized in future work.
Efficient first-order predictor-corrector multiple objective optimization for fair misinformation detection
Sep 15, 2022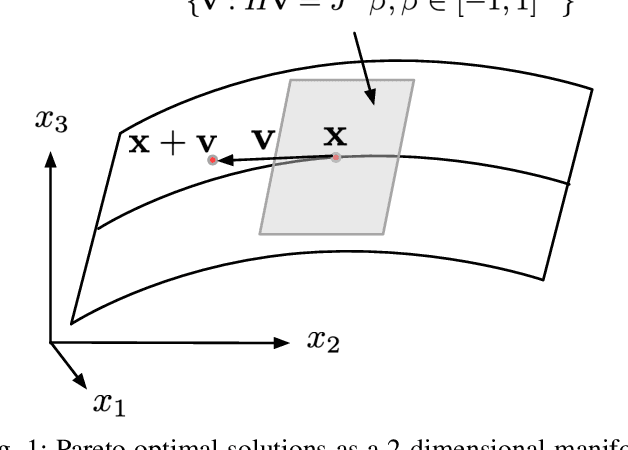
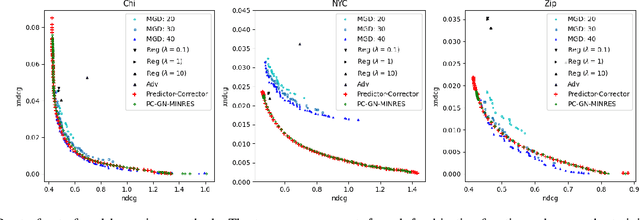
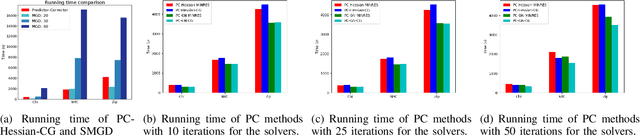
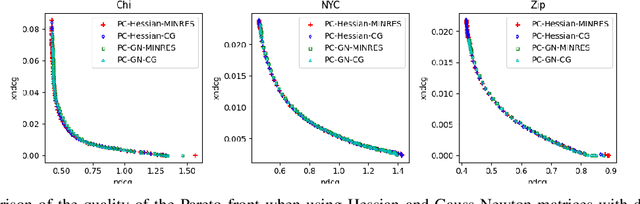
Multiple-objective optimization (MOO) aims to simultaneously optimize multiple conflicting objectives and has found important applications in machine learning, such as minimizing classification loss and discrepancy in treating different populations for fairness. At optimality, further optimizing one objective will necessarily harm at least another objective, and decision-makers need to comprehensively explore multiple optima (called Pareto front) to pinpoint one final solution. We address the efficiency of finding the Pareto front. First, finding the front from scratch using stochastic multi-gradient descent (SMGD) is expensive with large neural networks and datasets. We propose to explore the Pareto front as a manifold from a few initial optima, based on a predictor-corrector method. Second, for each exploration step, the predictor solves a large-scale linear system that scales quadratically in the number of model parameters and requires one backpropagation to evaluate a second-order Hessian-vector product per iteration of the solver. We propose a Gauss-Newton approximation that only scales linearly, and that requires only first-order inner-product per iteration. This also allows for a choice between the MINRES and conjugate gradient methods when approximately solving the linear system. The innovations make predictor-corrector possible for large networks. Experiments on multi-objective (fairness and accuracy) misinformation detection tasks show that 1) the predictor-corrector method can find Pareto fronts better than or similar to SMGD with less time; and 2) the proposed first-order method does not harm the quality of the Pareto front identified by the second-order method, while further reduce running time.