 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSihong Xie
Incorporating Domain Differential Equations into Graph Convolutional Networks to Lower Generalization Discrepancy
Apr 01, 2024
Ensuring both accuracy and robustness in time series prediction is critical to many applications, ranging from urban planning to pandemic management. With sufficient training data where all spatiotemporal patterns are well-represented, existing deep-learning models can make reasonably accurate predictions. However, existing methods fail when the training data are drawn from different circumstances (e.g., traffic patterns on regular days) compared to test data (e.g., traffic patterns after a natural disaster). Such challenges are usually classified under domain generalization. In this work, we show that one way to address this challenge in the context of spatiotemporal prediction is by incorporating domain differential equations into Graph Convolutional Networks (GCNs). We theoretically derive conditions where GCNs incorporating such domain differential equations are robust to mismatched training and testing data compared to baseline domain agnostic models. To support our theory, we propose two domain-differential-equation-informed networks called Reaction-Diffusion Graph Convolutional Network (RDGCN), which incorporates differential equations for traffic speed evolution, and Susceptible-Infectious-Recovered Graph Convolutional Network (SIRGCN), which incorporates a disease propagation model. Both RDGCN and SIRGCN are based on reliable and interpretable domain differential equations that allow the models to generalize to unseen patterns. We experimentally show that RDGCN and SIRGCN are more robust with mismatched testing data than the state-of-the-art deep learning methods.
Robust Conformal Prediction under Distribution Shift via Physics-Informed Structural Causal Model
Mar 22, 2024Uncertainty is critical to reliable decision-making with machine learning. Conformal prediction (CP) handles uncertainty by predicting a set on a test input, hoping the set to cover the true label with at least $(1-\alpha)$ confidence. This coverage can be guaranteed on test data even if the marginal distributions $P_X$ differ between calibration and test datasets. However, as it is common in practice, when the conditional distribution $P_{Y|X}$ is different on calibration and test data, the coverage is not guaranteed and it is essential to measure and minimize the coverage loss under distributional shift at \textit{all} possible confidence levels. To address these issues, we upper bound the coverage difference at all levels using the cumulative density functions of calibration and test conformal scores and Wasserstein distance. Inspired by the invariance of physics across data distributions, we propose a physics-informed structural causal model (PI-SCM) to reduce the upper bound. We validated that PI-SCM can improve coverage robustness along confidence level and test domain on a traffic speed prediction task and an epidemic spread task with multiple real-world datasets.
A Differential Geometric View and Explainability of GNN on Evolving Graphs
Mar 11, 2024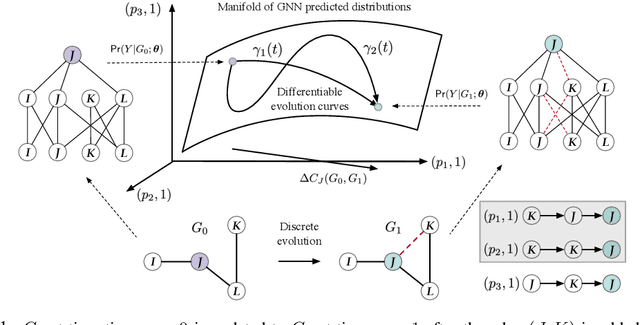
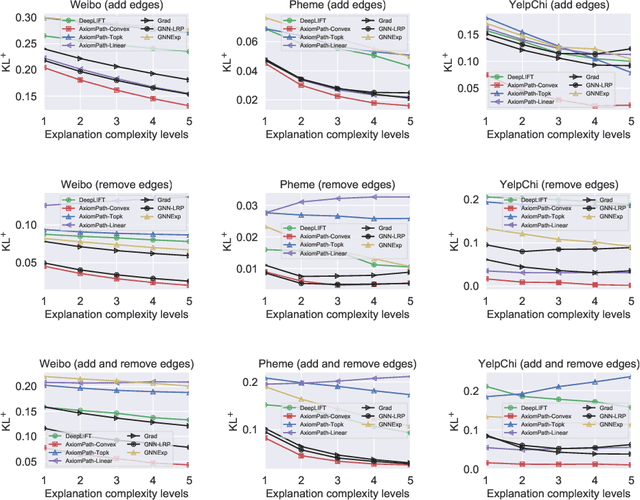
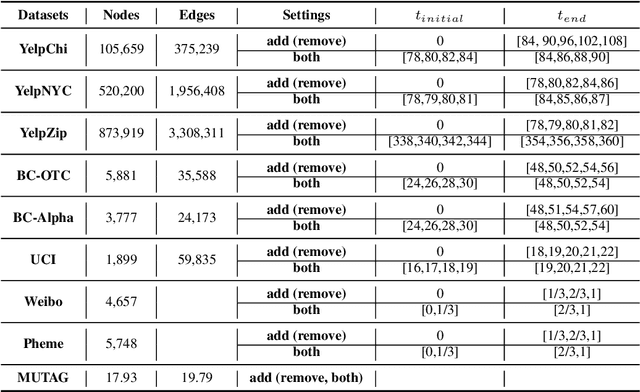
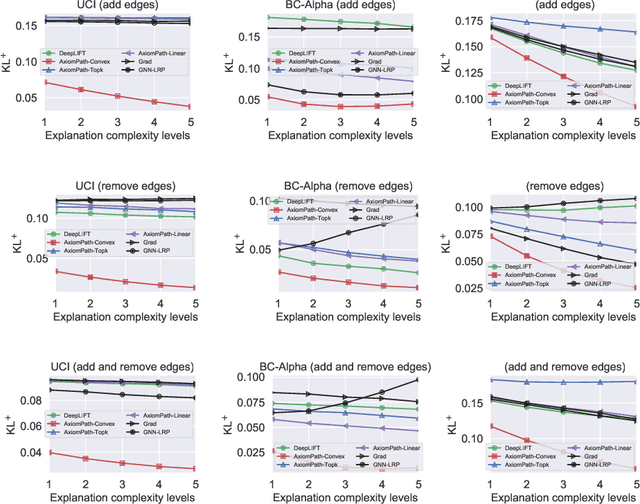
Graphs are ubiquitous in social networks and biochemistry, where Graph Neural Networks (GNN) are the state-of-the-art models for prediction. Graphs can be evolving and it is vital to formally model and understand how a trained GNN responds to graph evolution. We propose a smooth parameterization of the GNN predicted distributions using axiomatic attribution, where the distributions are on a low-dimensional manifold within a high-dimensional embedding space. We exploit the differential geometric viewpoint to model distributional evolution as smooth curves on the manifold. We reparameterize families of curves on the manifold and design a convex optimization problem to find a unique curve that concisely approximates the distributional evolution for human interpretation. Extensive experiments on node classification, link prediction, and graph classification tasks with evolving graphs demonstrate the better sparsity, faithfulness, and intuitiveness of the proposed method over the state-of-the-art methods.
Implementing Recycling Methods for Linear Systems in Python with an Application to Multiple Objective Optimization
Feb 25, 2024Sequences of linear systems arise in the predictor-corrector method when computing the Pareto front for multi-objective optimization. Rather than discarding information generated when solving one system, it may be advantageous to recycle information for subsequent systems. To accomplish this, we seek to reduce the overall cost of computation when solving linear systems using common recycling methods. In this work, we assessed the performance of recycling minimum residual (RMINRES) method along with a map between coefficient matrices. For these methods to be fully integrated into the software used in Enouen et al. (2022), there must be working version of each in both Python and PyTorch. Herein, we discuss the challenges we encountered and solutions undertaken (and some ongoing) when computing efficient Python implementations of these recycling strategies. The goal of this project was to implement RMINRES in Python and PyTorch and add it to the established Pareto front code to reduce computational cost. Additionally, we wanted to implement the sparse approximate maps code in Python and PyTorch, so that it can be parallelized in future work.
DetectGPT-SC: Improving Detection of Text Generated by Large Language Models through Self-Consistency with Masked Predictions
Oct 23, 2023General large language models (LLMs) such as ChatGPT have shown remarkable success, but it has also raised concerns among people about the misuse of AI-generated texts. Therefore, an important question is how to detect whether the texts are generated by ChatGPT or by humans. Existing detectors are built on the assumption that there is a distribution gap between human-generated and AI-generated texts. These gaps are typically identified using statistical information or classifiers. In contrast to prior research methods, we find that large language models such as ChatGPT exhibit strong self-consistency in text generation and continuation. Self-consistency capitalizes on the intuition that AI-generated texts can still be reasoned with by large language models using the same logical reasoning when portions of the texts are masked, which differs from human-generated texts. Using this observation, we subsequently proposed a new method for AI-generated texts detection based on self-consistency with masked predictions to determine whether a text is generated by LLMs. This method, which we call DetectGPT-SC. We conducted a series of experiments to evaluate the performance of DetectGPT-SC. In these experiments, we employed various mask scheme, zero-shot, and simple prompt for completing masked texts and self-consistency predictions. The results indicate that DetectGPT-SC outperforms the current state-of-the-art across different tasks.
Robust Ranking Explanations
Jul 08, 2023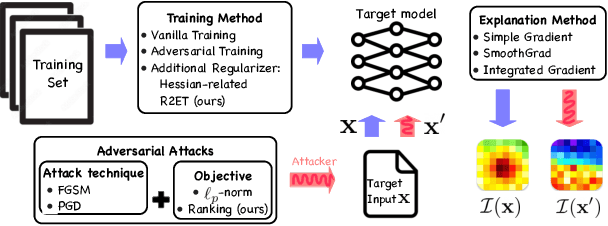
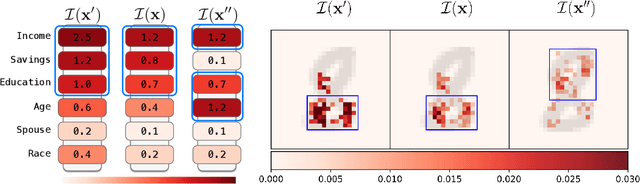
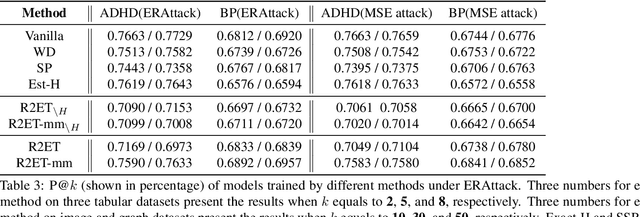
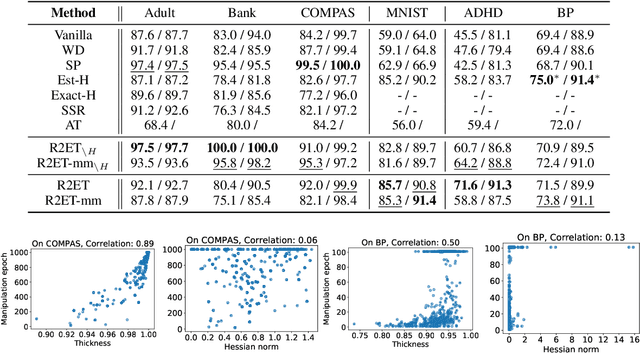
Robust explanations of machine learning models are critical to establish human trust in the models. Due to limited cognition capability, most humans can only interpret the top few salient features. It is critical to make top salient features robust to adversarial attacks, especially those against the more vulnerable gradient-based explanations. Existing defense measures robustness using $\ell_p$-norms, which have weaker protection power. We define explanation thickness for measuring salient features ranking stability, and derive tractable surrogate bounds of the thickness to design the \textit{R2ET} algorithm to efficiently maximize the thickness and anchor top salient features. Theoretically, we prove a connection between R2ET and adversarial training. Experiments with a wide spectrum of network architectures and data modalities, including brain networks, demonstrate that R2ET attains higher explanation robustness under stealthy attacks while retaining accuracy.
Inconsistent Matters: A Knowledge-guided Dual-consistency Network for Multi-modal Rumor Detection
Jun 19, 2023
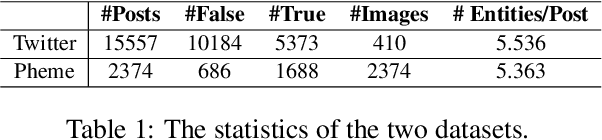
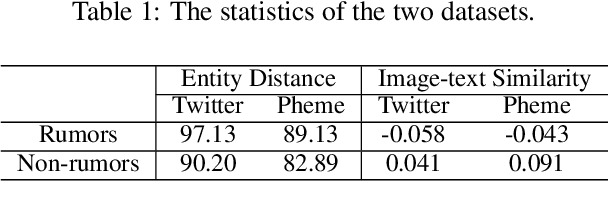
Rumor spreaders are increasingly utilizing multimedia content to attract the attention and trust of news consumers. Though quite a few rumor detection models have exploited the multi-modal data, they seldom consider the inconsistent semantics between images and texts, and rarely spot the inconsistency among the post contents and background knowledge. In addition, they commonly assume the completeness of multiple modalities and thus are incapable of handling handle missing modalities in real-life scenarios. Motivated by the intuition that rumors in social media are more likely to have inconsistent semantics, a novel Knowledge-guided Dual-consistency Network is proposed to detect rumors with multimedia contents. It uses two consistency detection subnetworks to capture the inconsistency at the cross-modal level and the content-knowledge level simultaneously. It also enables robust multi-modal representation learning under different missing visual modality conditions, using a special token to discriminate between posts with visual modality and posts without visual modality. Extensive experiments on three public real-world multimedia datasets demonstrate that our framework can outperform the state-of-the-art baselines under both complete and incomplete modality conditions. Our codes are available at https://github.com/MengzSun/KDCN.
Efficient first-order predictor-corrector multiple objective optimization for fair misinformation detection
Sep 15, 2022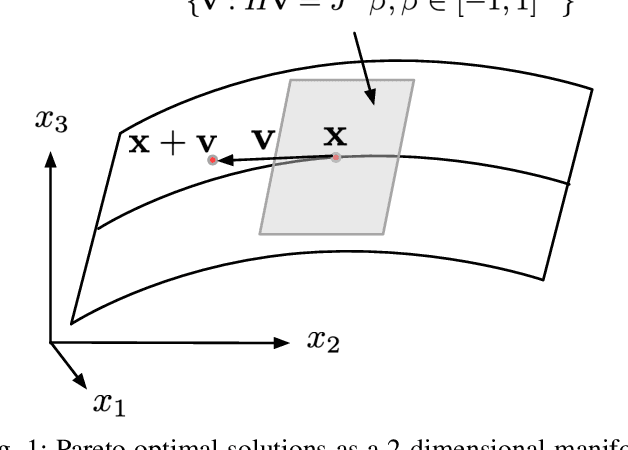
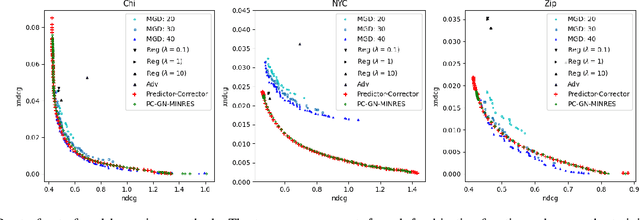
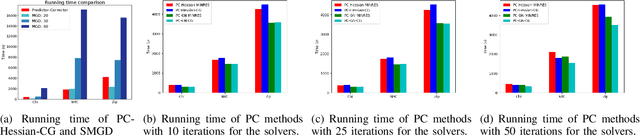
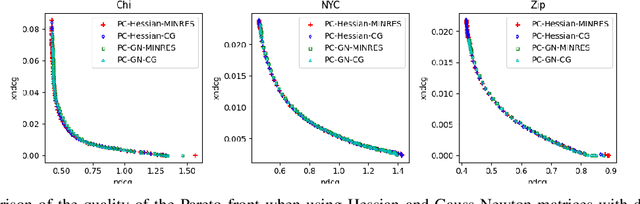
Multiple-objective optimization (MOO) aims to simultaneously optimize multiple conflicting objectives and has found important applications in machine learning, such as minimizing classification loss and discrepancy in treating different populations for fairness. At optimality, further optimizing one objective will necessarily harm at least another objective, and decision-makers need to comprehensively explore multiple optima (called Pareto front) to pinpoint one final solution. We address the efficiency of finding the Pareto front. First, finding the front from scratch using stochastic multi-gradient descent (SMGD) is expensive with large neural networks and datasets. We propose to explore the Pareto front as a manifold from a few initial optima, based on a predictor-corrector method. Second, for each exploration step, the predictor solves a large-scale linear system that scales quadratically in the number of model parameters and requires one backpropagation to evaluate a second-order Hessian-vector product per iteration of the solver. We propose a Gauss-Newton approximation that only scales linearly, and that requires only first-order inner-product per iteration. This also allows for a choice between the MINRES and conjugate gradient methods when approximately solving the linear system. The innovations make predictor-corrector possible for large networks. Experiments on multi-objective (fairness and accuracy) misinformation detection tasks show that 1) the predictor-corrector method can find Pareto fronts better than or similar to SMGD with less time; and 2) the proposed first-order method does not harm the quality of the Pareto front identified by the second-order method, while further reduce running time.