 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArmando Solar-Lezama
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Mar 12, 2024
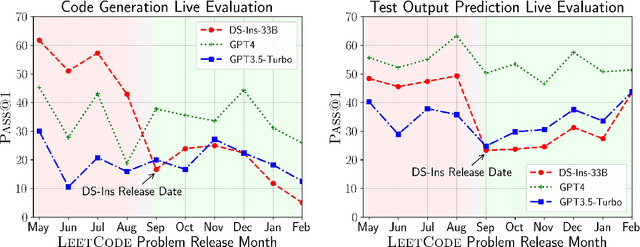
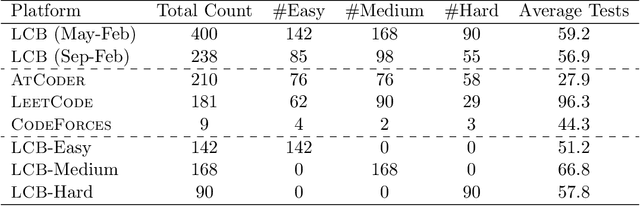
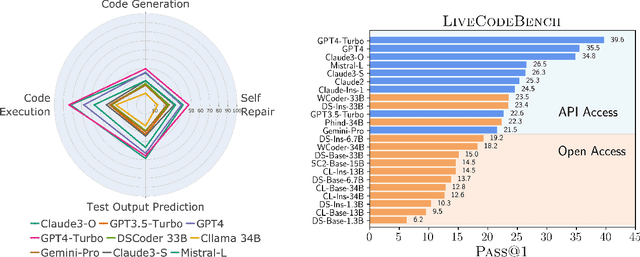
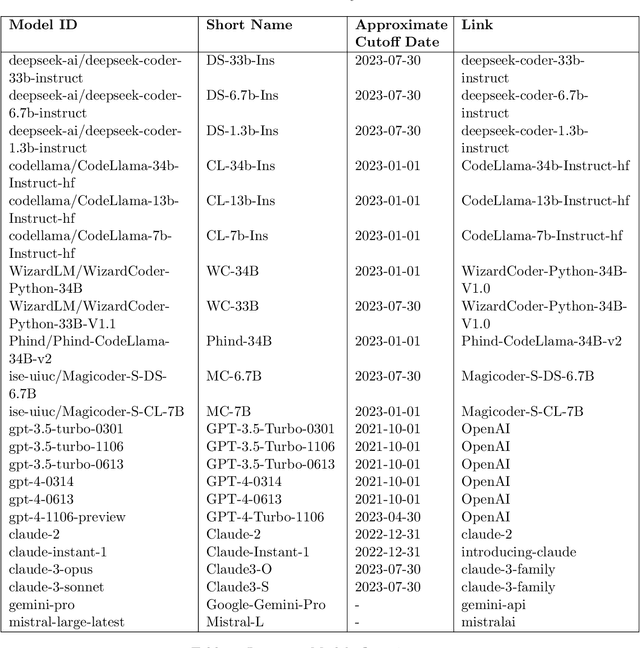
Large Language Models (LLMs) applied to code-related applications have emerged as a prominent field, attracting significant interest from both academia and industry. However, as new and improved LLMs are developed, existing evaluation benchmarks (e.g., HumanEval, MBPP) are no longer sufficient for assessing their capabilities. In this work, we propose LiveCodeBench, a comprehensive and contamination-free evaluation of LLMs for code, which continuously collects new problems over time from contests across three competition platforms, namely LeetCode, AtCoder, and CodeForces. Notably, our benchmark also focuses on a broader range of code related capabilities, such as self-repair, code execution, and test output prediction, beyond just code generation. Currently, LiveCodeBench hosts four hundred high-quality coding problems that were published between May 2023 and February 2024. We have evaluated 9 base LLMs and 20 instruction-tuned LLMs on LiveCodeBench. We present empirical findings on contamination, holistic performance comparisons, potential overfitting in existing benchmarks as well as individual model comparisons. We will release all prompts and model completions for further community analysis, along with a general toolkit for adding new scenarios and model
The Counterfeit Conundrum: Can Code Language Models Grasp the Nuances of Their Incorrect Generations?
Feb 29, 2024While language models are increasingly more proficient at code generation, they still frequently generate incorrect programs. Many of these programs are obviously wrong, but others are more subtle and pass weaker correctness checks such as being able to compile. In this work, we focus on these counterfeit samples: programs sampled from a language model that 1) have a high enough log-probability to be generated at a moderate temperature and 2) pass weak correctness checks. Overall, we discover that most models have a very shallow understanding of counterfeits through three clear failure modes. First, models mistakenly classify them as correct. Second, models are worse at reasoning about the execution behaviour of counterfeits and often predict their execution results as if they were correct. Third, when asking models to fix counterfeits, the likelihood of a model successfully repairing a counterfeit is often even lower than that of sampling a correct program from scratch. Counterfeits also have very unexpected properties: first, counterfeit programs for problems that are easier for a model to solve are not necessarily easier to detect and only slightly easier to execute and repair. Second, counterfeits from a given model are just as confusing to the model itself as they are to other models. Finally, both strong and weak models are able to generate counterfeit samples that equally challenge all models. In light of our findings, we recommend that care and caution be taken when relying on models to understand their own samples, especially when no external feedback is incorporated.
CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution
Jan 05, 2024We present CRUXEval (Code Reasoning, Understanding, and eXecution Evaluation), a benchmark consisting of 800 Python functions (3-13 lines). Each function comes with an input-output pair, leading to two natural tasks: input prediction and output prediction. First, we propose a generic recipe for generating our execution benchmark which can be used to create future variation of the benchmark. Second, we evaluate twenty code models on our benchmark and discover that many recent high-scoring models on HumanEval do not show the same improvements on our benchmark. Third, we show that simple CoT and fine-tuning schemes can improve performance on our benchmark but remain far from solving it. The best setup, GPT-4 with chain of thought (CoT), achieves a pass@1 of 75% and 81% on input and output prediction, respectively. In contrast, Code Llama 34B achieves a pass@1 of 50% and 46% on input and output prediction, highlighting the gap between open and closed source models. As no model is close to acing CRUXEval, we provide examples of consistent GPT-4 failures on simple programs as a lens into its code reasoning capabilities and areas for improvement.
LINC: A Neurosymbolic Approach for Logical Reasoning by Combining Language Models with First-Order Logic Provers
Oct 23, 2023Logical reasoning, i.e., deductively inferring the truth value of a conclusion from a set of premises, is an important task for artificial intelligence with wide potential impacts on science, mathematics, and society. While many prompting-based strategies have been proposed to enable Large Language Models (LLMs) to do such reasoning more effectively, they still appear unsatisfactory, often failing in subtle and unpredictable ways. In this work, we investigate the validity of instead reformulating such tasks as modular neurosymbolic programming, which we call LINC: Logical Inference via Neurosymbolic Computation. In LINC, the LLM acts as a semantic parser, translating premises and conclusions from natural language to expressions in first-order logic. These expressions are then offloaded to an external theorem prover, which symbolically performs deductive inference. Leveraging this approach, we observe significant performance gains on FOLIO and a balanced subset of ProofWriter for three different models in nearly all experimental conditions we evaluate. On ProofWriter, augmenting the comparatively small open-source StarCoder+ (15.5B parameters) with LINC even outperforms GPT-3.5 and GPT-4 with Chain-of-Thought (CoT) prompting by an absolute 38% and 10%, respectively. When used with GPT-4, LINC scores 26% higher than CoT on ProofWriter while performing comparatively on FOLIO. Further analysis reveals that although both methods on average succeed roughly equally often on this dataset, they exhibit distinct and complementary failure modes. We thus provide promising evidence for how logical reasoning over natural language can be tackled through jointly leveraging LLMs alongside symbolic provers. All corresponding code is publicly available at https://github.com/benlipkin/linc
Learning a Hierarchical Planner from Humans in Multiple Generations
Oct 17, 2023A typical way in which a machine acquires knowledge from humans is by programming. Compared to learning from demonstrations or experiences, programmatic learning allows the machine to acquire a novel skill as soon as the program is written, and, by building a library of programs, a machine can quickly learn how to perform complex tasks. However, as programs often take their execution contexts for granted, they are brittle when the contexts change, making it difficult to adapt complex programs to new contexts. We present natural programming, a library learning system that combines programmatic learning with a hierarchical planner. Natural programming maintains a library of decompositions, consisting of a goal, a linguistic description of how this goal decompose into sub-goals, and a concrete instance of its decomposition into sub-goals. A user teaches the system via curriculum building, by identifying a challenging yet not impossible goal along with linguistic hints on how this goal may be decomposed into sub-goals. The system solves for the goal via hierarchical planning, using the linguistic hints to guide its probability distribution in proposing the right plans. The system learns from this interaction by adding newly found decompositions in the successful search into its library. Simulated studies and a human experiment (n=360) on a controlled environment demonstrate that natural programming can robustly compose programs learned from different users and contexts, adapting faster and solving more complex tasks when compared to programmatic baselines.
Exploring the MIT Mathematics and EECS Curriculum Using Large Language Models
Jun 24, 2023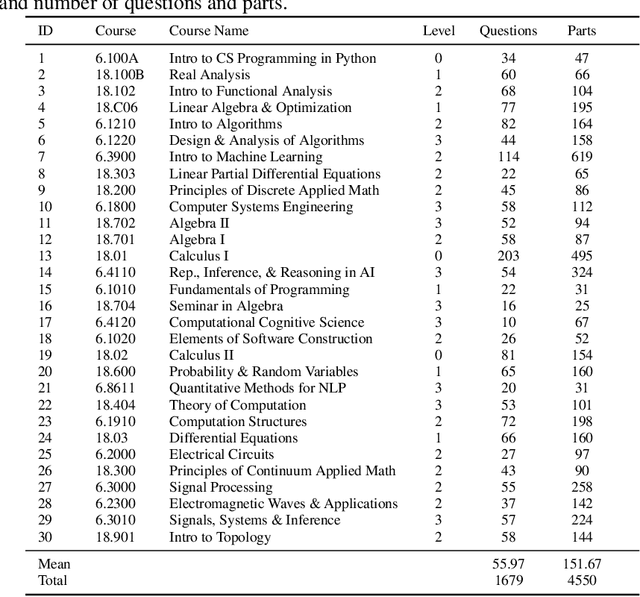
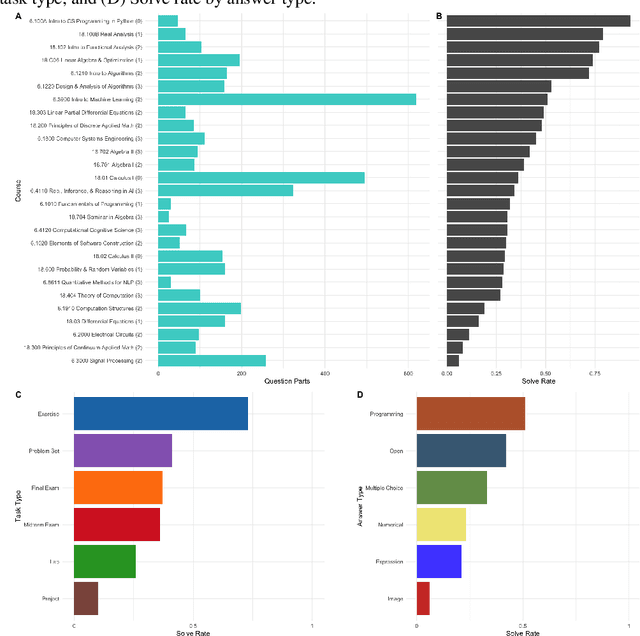

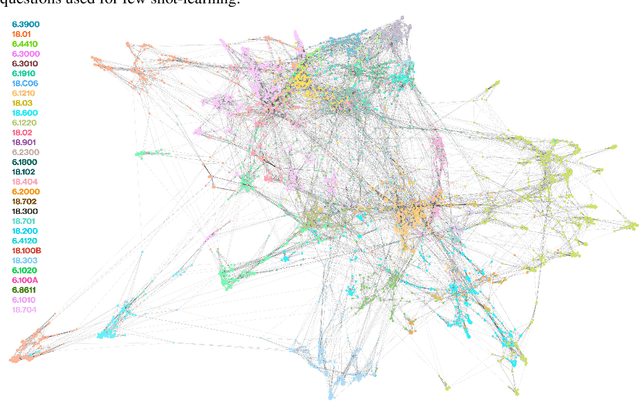
We curate a comprehensive dataset of 4,550 questions and solutions from problem sets, midterm exams, and final exams across all MIT Mathematics and Electrical Engineering and Computer Science (EECS) courses required for obtaining a degree. We evaluate the ability of large language models to fulfill the graduation requirements for any MIT major in Mathematics and EECS. Our results demonstrate that GPT-3.5 successfully solves a third of the entire MIT curriculum, while GPT-4, with prompt engineering, achieves a perfect solve rate on a test set excluding questions based on images. We fine-tune an open-source large language model on this dataset. We employ GPT-4 to automatically grade model responses, providing a detailed performance breakdown by course, question, and answer type. By embedding questions in a low-dimensional space, we explore the relationships between questions, topics, and classes and discover which questions and classes are required for solving other questions and classes through few-shot learning. Our analysis offers valuable insights into course prerequisites and curriculum design, highlighting language models' potential for learning and improving Mathematics and EECS education.
Demystifying GPT Self-Repair for Code Generation
Jun 22, 2023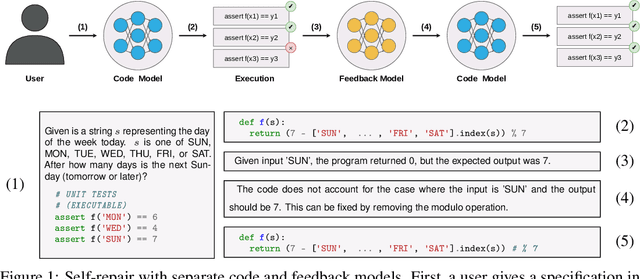
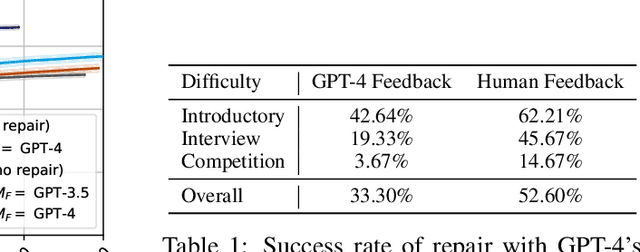


Large Language Models (LLMs) have shown remarkable aptitude in code generation but still struggle on challenging programming tasks. Self-repair -- in which the model debugs and fixes mistakes in its own code -- has recently become a popular way to boost performance in these settings. However, only very limited studies on how and when self-repair works effectively exist in the literature, and one might wonder to what extent a model is really capable of providing accurate feedback on why the code is wrong when that code was generated by the same model. In this paper, we analyze GPT-3.5 and GPT-4's ability to perform self-repair on APPS, a challenging dataset consisting of diverse coding challenges. To do so, we first establish a new evaluation strategy dubbed pass@t that measures the pass rate of the tasks against the total number of tokens sampled from the model, enabling a fair comparison to purely sampling-based approaches. With this evaluation strategy, we find that the effectiveness of self-repair is only seen in GPT-4. We also observe that self-repair is bottlenecked by the feedback stage; using GPT-4 to give feedback on the programs generated by GPT-3.5 and using expert human programmers to give feedback on the programs generated by GPT-4, we unlock significant performance gains.
SPARLING: Learning Latent Representations with Extremely Sparse Activations
Feb 03, 2023

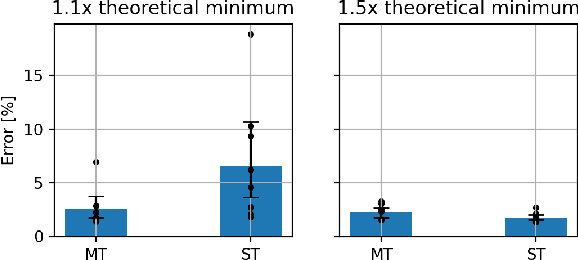
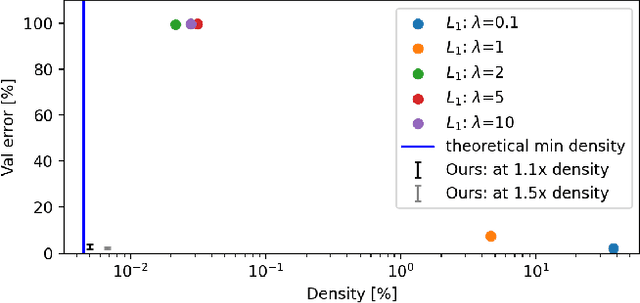
Real-world processes often contain intermediate state that can be modeled as an extremely sparse tensor. We introduce Sparling, a new kind of informational bottleneck that explicitly models this state by enforcing extreme activation sparsity. We additionally demonstrate that this technique can be used to learn the true intermediate representation with no additional supervision (i.e., from only end-to-end labeled examples), and thus improve the interpretability of the resulting models. On our DigitCircle domain, we are able to get an intermediate state prediction accuracy of 98.84%, even as we only train end-to-end.
Top-Down Synthesis for Library Learning
Nov 29, 2022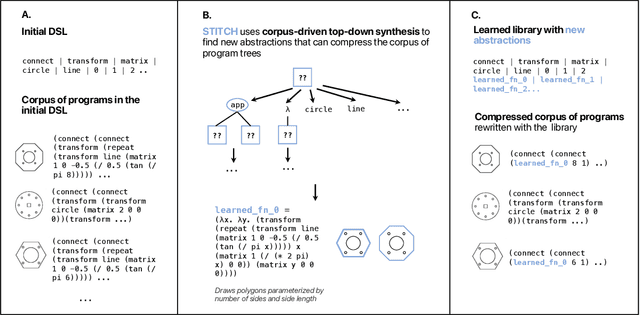
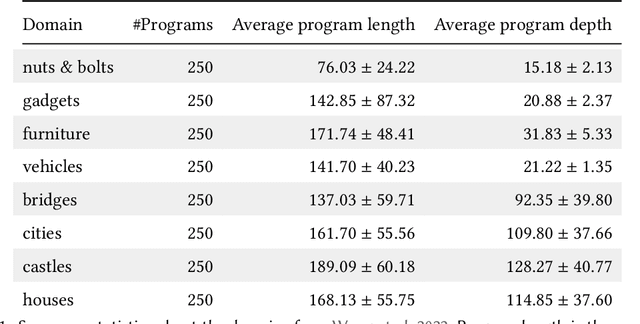
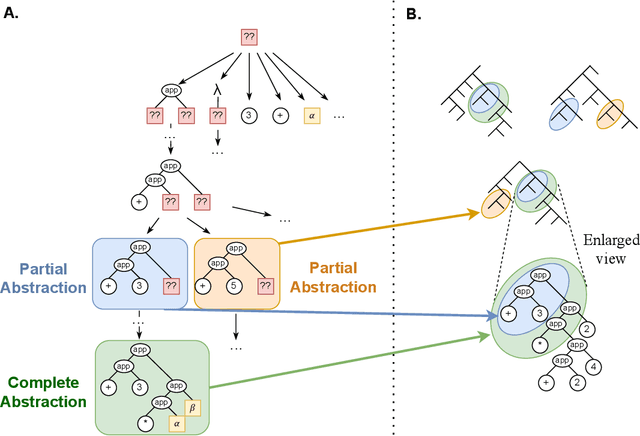
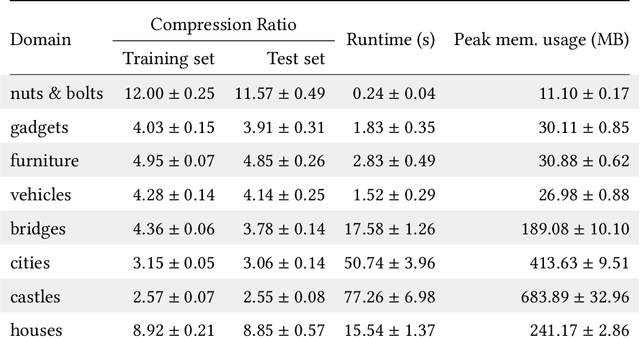
This paper introduces corpus-guided top-down synthesis as a mechanism for synthesizing library functions that capture common functionality from a corpus of programs in a domain specific language (DSL). The algorithm builds abstractions directly from initial DSL primitives, using syntactic pattern matching of intermediate abstractions to intelligently prune the search space and guide the algorithm towards abstractions that maximally capture shared structures in the corpus. We present an implementation of the approach in a tool called Stitch and evaluate it against the state-of-the-art deductive library learning algorithm from DreamCoder. Our evaluation shows that Stitch is 3-4 orders of magnitude faster and uses 2 orders of magnitude less memory while maintaining comparable or better library quality (as measured by compressivity). We also demonstrate Stitch's scalability on corpora containing hundreds of complex programs that are intractable with prior deductive approaches and show empirically that it is robust to terminating the search procedure early -- further allowing it to scale to challenging datasets by means of early stopping.
Human Evaluation of Text-to-Image Models on a Multi-Task Benchmark
Nov 22, 2022
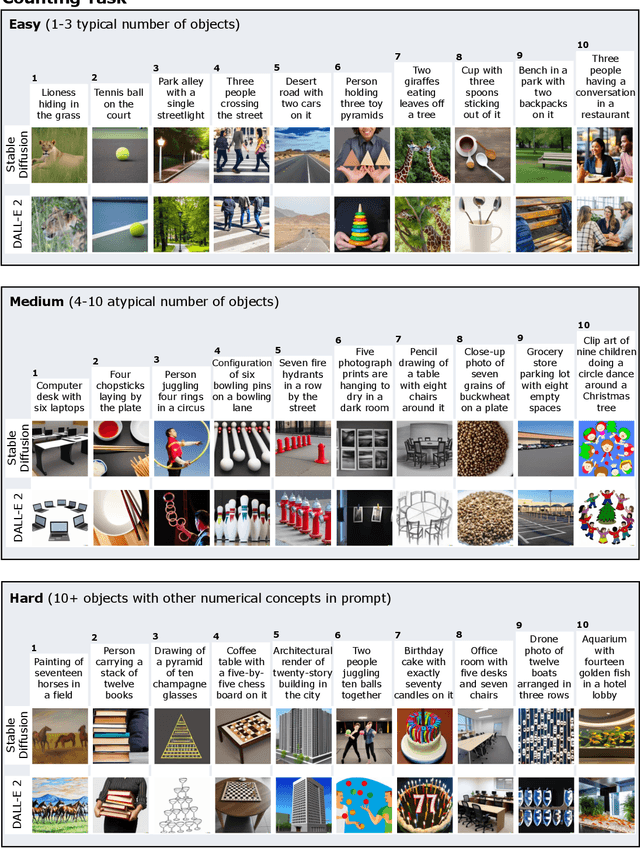

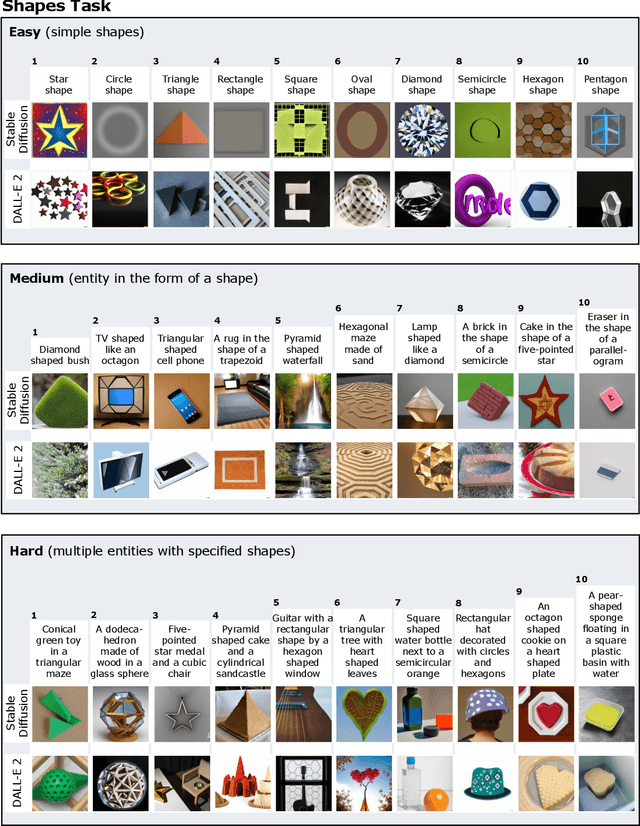
We provide a new multi-task benchmark for evaluating text-to-image models. We perform a human evaluation comparing the most common open-source (Stable Diffusion) and commercial (DALL-E 2) models. Twenty computer science AI graduate students evaluated the two models, on three tasks, at three difficulty levels, across ten prompts each, providing 3,600 ratings. Text-to-image generation has seen rapid progress to the point that many recent models have demonstrated their ability to create realistic high-resolution images for various prompts. However, current text-to-image methods and the broader body of research in vision-language understanding still struggle with intricate text prompts that contain many objects with multiple attributes and relationships. We introduce a new text-to-image benchmark that contains a suite of thirty-two tasks over multiple applications that capture a model's ability to handle different features of a text prompt. For example, asking a model to generate a varying number of the same object to measure its ability to count or providing a text prompt with several objects that each have a different attribute to identify its ability to match objects and attributes correctly. Rather than subjectively evaluating text-to-image results on a set of prompts, our new multi-task benchmark consists of challenge tasks at three difficulty levels (easy, medium, and hard) and human ratings for each generated image.