 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArushi Jain
Towards Painless Policy Optimization for Constrained MDPs
Apr 11, 2022
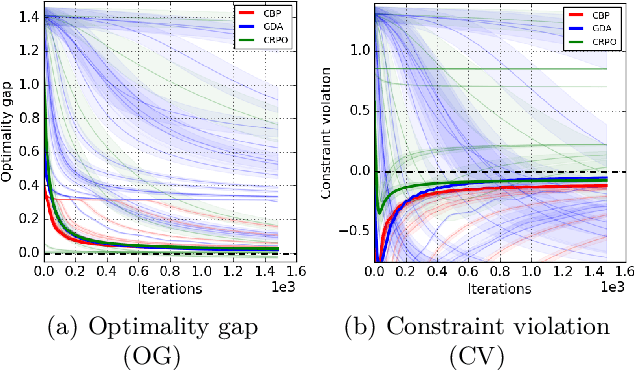

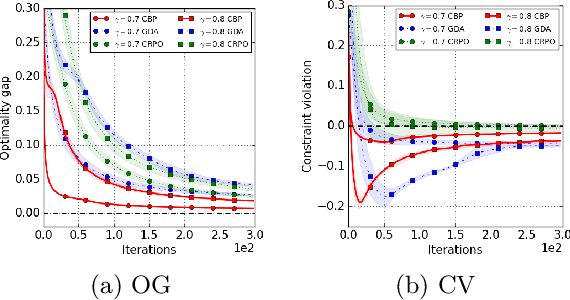
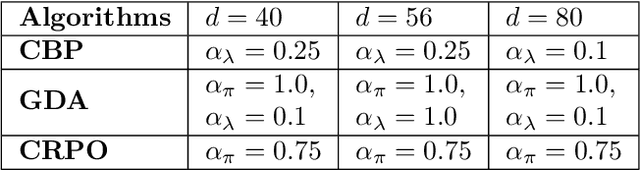
We study policy optimization in an infinite horizon, $\gamma$-discounted constrained Markov decision process (CMDP). Our objective is to return a policy that achieves large expected reward with a small constraint violation. We consider the online setting with linear function approximation and assume global access to the corresponding features. We propose a generic primal-dual framework that allows us to bound the reward sub-optimality and constraint violation for arbitrary algorithms in terms of their primal and dual regret on online linear optimization problems. We instantiate this framework to use coin-betting algorithms and propose the Coin Betting Politex (CBP) algorithm. Assuming that the action-value functions are $\varepsilon_b$-close to the span of the $d$-dimensional state-action features and no sampling errors, we prove that $T$ iterations of CBP result in an $O\left(\frac{1}{(1 - \gamma)^3 \sqrt{T}} + \frac{\varepsilon_b\sqrt{d}}{(1 - \gamma)^2} \right)$ reward sub-optimality and an $O\left(\frac{1}{(1 - \gamma)^2 \sqrt{T}} + \frac{\varepsilon_b \sqrt{d}}{1 - \gamma} \right)$ constraint violation. Importantly, unlike gradient descent-ascent and other recent methods, CBP does not require extensive hyperparameter tuning. Via experiments on synthetic and Cartpole environments, we demonstrate the effectiveness and robustness of CBP.
TSR-DSAW: Table Structure Recognition via Deep Spatial Association of Words
Mar 14, 2022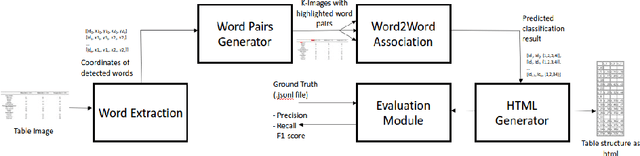
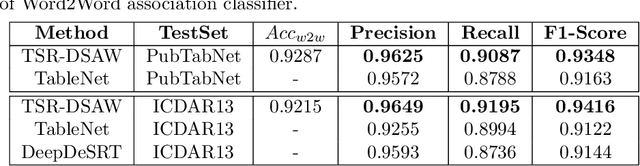
Existing methods for Table Structure Recognition (TSR) from camera-captured or scanned documents perform poorly on complex tables consisting of nested rows / columns, multi-line texts and missing cell data. This is because current data-driven methods work by simply training deep models on large volumes of data and fail to generalize when an unseen table structure is encountered. In this paper, we propose to train a deep network to capture the spatial associations between different word pairs present in the table image for unravelling the table structure. We present an end-to-end pipeline, named TSR-DSAW: TSR via Deep Spatial Association of Words, which outputs a digital representation of a table image in a structured format such as HTML. Given a table image as input, the proposed method begins with the detection of all the words present in the image using a text-detection network like CRAFT which is followed by the generation of word-pairs using dynamic programming. These word-pairs are highlighted in individual images and subsequently, fed into a DenseNet-121 classifier trained to capture spatial associations such as same-row, same-column, same-cell or none. Finally, we perform post-processing on the classifier output to generate the table structure in HTML format. We evaluate our TSR-DSAW pipeline on two public table-image datasets -- PubTabNet and ICDAR 2013, and demonstrate improvement over previous methods such as TableNet and DeepDeSRT.
* 6 pages, 1 figure, 1 table, ESANN 2021 proceedings, European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning. Online event, 6-8 October 2021, i6doc.com publ., ISBN 978287587082-7
Digitize-PID: Automatic Digitization of Piping and Instrumentation Diagrams
Sep 08, 2021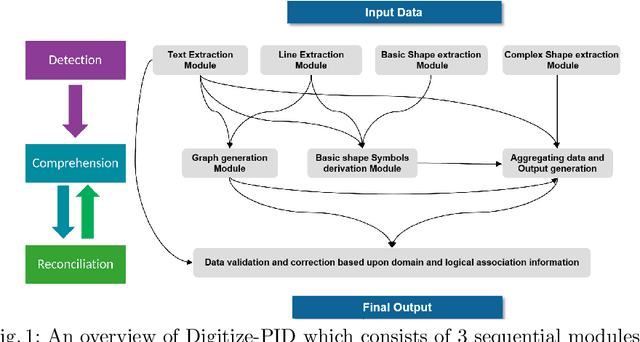
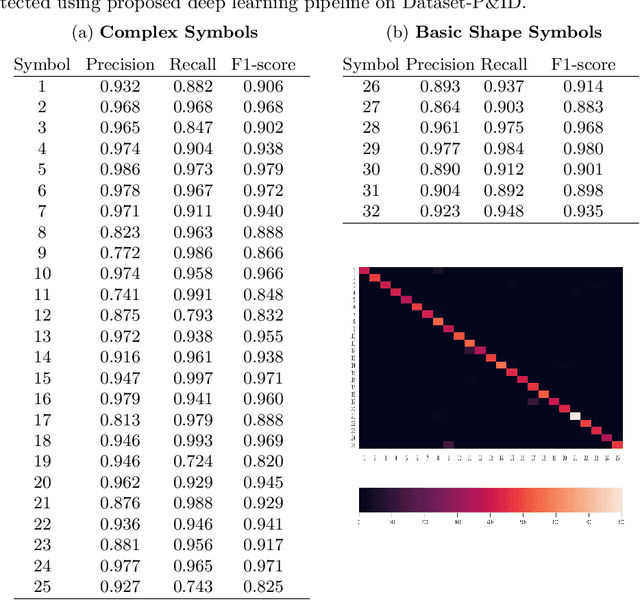
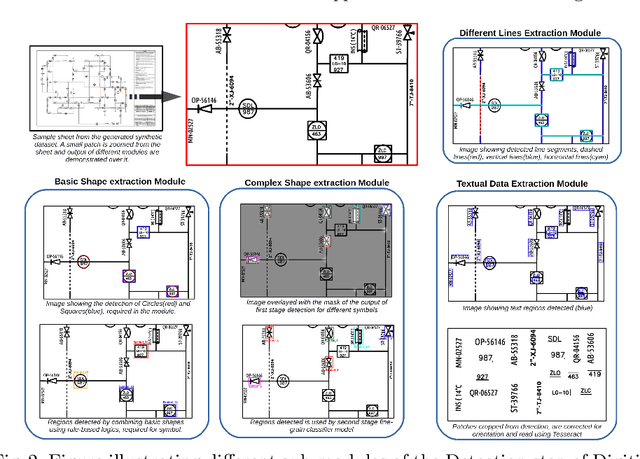
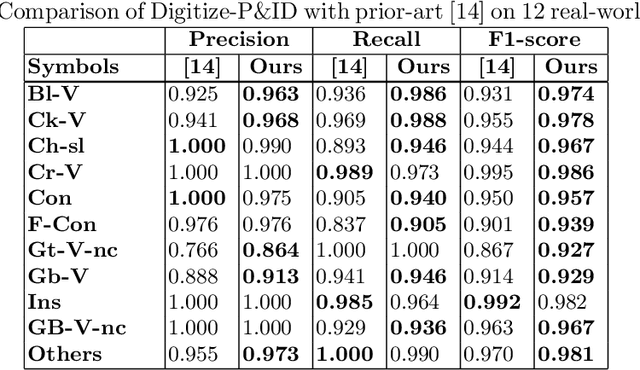
Digitization of scanned Piping and Instrumentation diagrams(P&ID), widely used in manufacturing or mechanical industries such as oil and gas over several decades, has become a critical bottleneck in dynamic inventory management and creation of smart P&IDs that are compatible with the latest CAD tools. Historically, P&ID sheets have been manually generated at the design stage, before being scanned and stored as PDFs. Current digitization initiatives involve manual processing and are consequently very time consuming, labour intensive and error-prone.Thanks to advances in image processing, machine and deep learning techniques there are emerging works on P&ID digitization. However, existing solutions face several challenges owing to the variation in the scale, size and noise in the P&IDs, sheer complexity and crowdedness within drawings, domain knowledge required to interpret the drawings. This motivates our current solution called Digitize-PID which comprises of an end-to-end pipeline for detection of core components from P&IDs like pipes, symbols and textual information, followed by their association with each other and eventually, the validation and correction of output data based on inherent domain knowledge. A novel and efficient kernel-based line detection and a two-step method for detection of complex symbols based on a fine-grained deep recognition technique is presented in the paper. In addition, we have created an annotated synthetic dataset, Dataset-P&ID, of 500 P&IDs by incorporating different types of noise and complex symbols which is made available for public use (currently there exists no public P&ID dataset). We evaluate our proposed method on this synthetic dataset and a real-world anonymized private dataset of 12 P&ID sheets. Results show that Digitize-PID outperforms the existing state-of-the-art for P&ID digitization.
* 13 pages
Variance Penalized On-Policy and Off-Policy Actor-Critic
Feb 03, 2021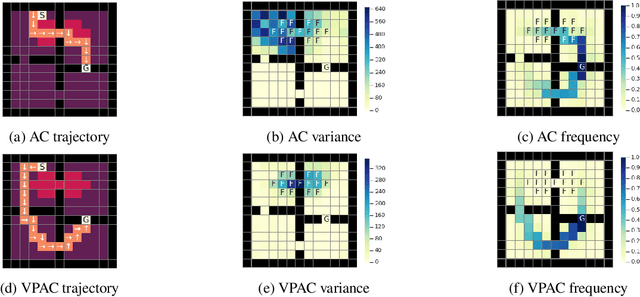
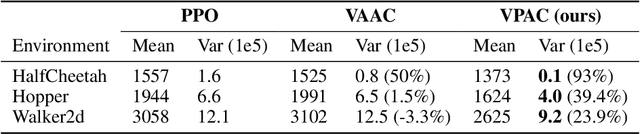
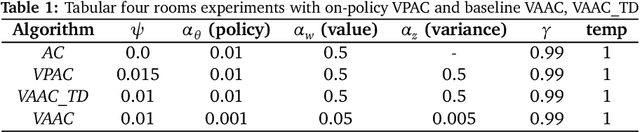
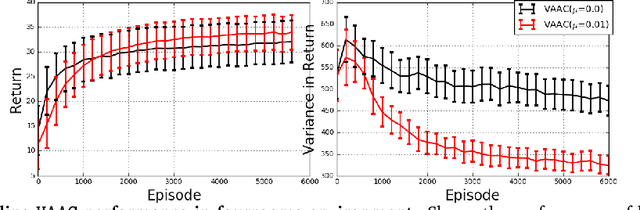
Reinforcement learning algorithms are typically geared towards optimizing the expected return of an agent. However, in many practical applications, low variance in the return is desired to ensure the reliability of an algorithm. In this paper, we propose on-policy and off-policy actor-critic algorithms that optimize a performance criterion involving both mean and variance in the return. Previous work uses the second moment of return to estimate the variance indirectly. Instead, we use a much simpler recently proposed direct variance estimator which updates the estimates incrementally using temporal difference methods. Using the variance-penalized criterion, we guarantee the convergence of our algorithm to locally optimal policies for finite state action Markov decision processes. We demonstrate the utility of our algorithm in tabular and continuous MuJoCo domains. Our approach not only performs on par with actor-critic and prior variance-penalization baselines in terms of expected return, but also generates trajectories which have lower variance in the return.
Audrey: A Personalized Open-Domain Conversational Bot
Nov 11, 2020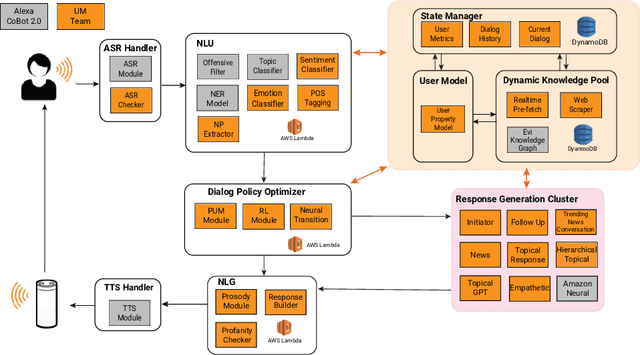


Conversational Intelligence requires that a person engage on informational, personal and relational levels. Advances in Natural Language Understanding have helped recent chatbots succeed at dialog on the informational level. However, current techniques still lag for conversing with humans on a personal level and fully relating to them. The University of Michigan's submission to the Alexa Prize Grand Challenge 3, Audrey, is an open-domain conversational chat-bot that aims to engage customers on these levels through interest driven conversations guided by customers' personalities and emotions. Audrey is built from socially-aware models such as Emotion Detection and a Personal Understanding Module to grasp a deeper understanding of users' interests and desires. Our architecture interacts with customers using a hybrid approach balanced between knowledge-driven response generators and context-driven neural response generators to cater to all three levels of conversations. During the semi-finals period, we achieved an average cumulative rating of 3.25 on a 1-5 Likert scale.
Safe Option-Critic: Learning Safety in the Option-Critic Architecture
Jul 21, 2018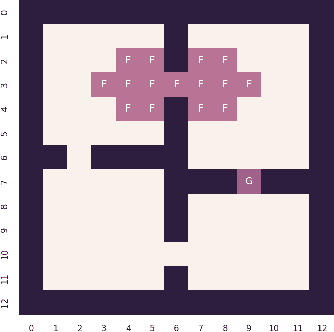
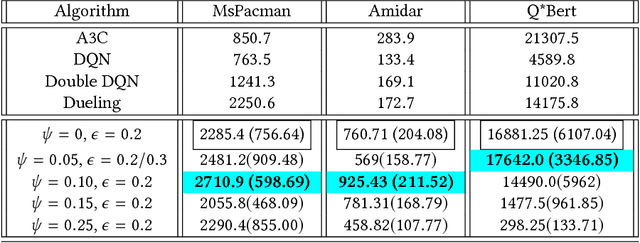
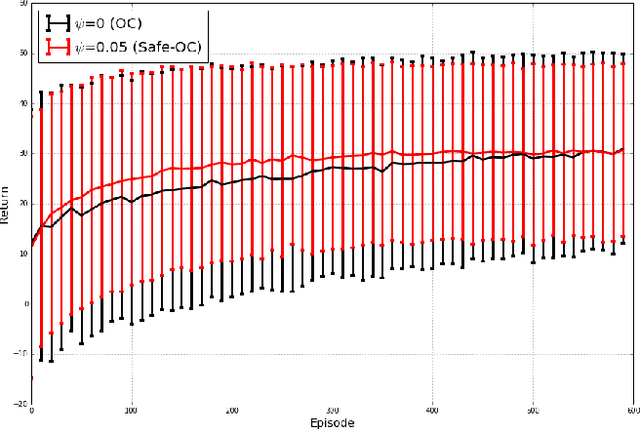
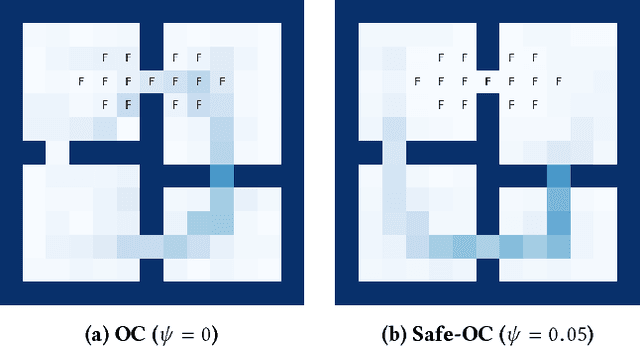
Designing hierarchical reinforcement learning algorithms that induce a notion of safety is not only vital for safety-critical applications, but also, brings better understanding of an artificially intelligent agent's decisions. While learning end-to-end options automatically has been fully realized recently, we propose a solution to learning safe options. We introduce the idea of controllability of states based on the temporal difference errors in the option-critic framework. We then derive the policy-gradient theorem with controllability and propose a novel framework called safe option-critic. We demonstrate the effectiveness of our approach in the four-rooms grid-world, cartpole, and three games in the Arcade Learning Environment (ALE): MsPacman, Amidar and Q*Bert. Learning of end-to-end options with the proposed notion of safety achieves reduction in the variance of return and boosts the performance in environments with intrinsic variability in the reward structure. More importantly, the proposed algorithm outperforms the vanilla options in all the environments and primitive actions in two out of three ALE games.
On Matching Skulls to Digital Face Images: A Preliminary Approach
Oct 08, 2017
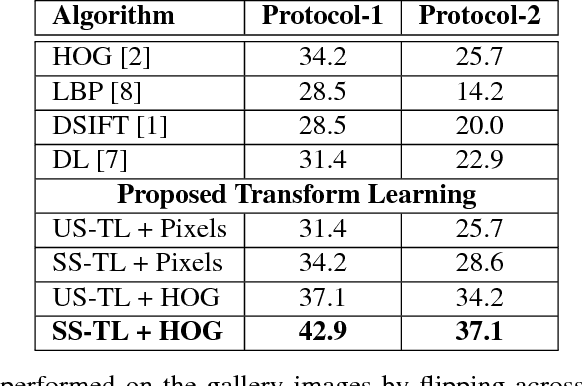
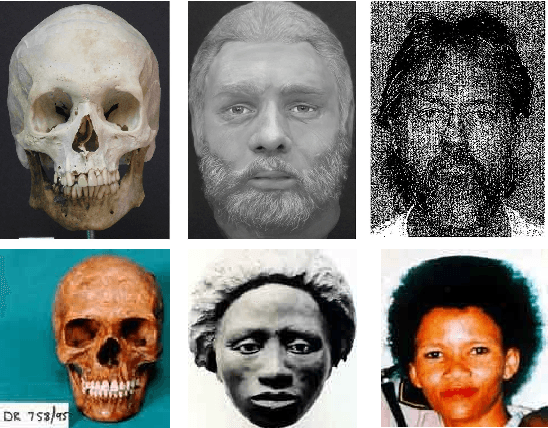

Forensic application of automatically matching skull with face images is an important research area linking biometrics with practical applications in forensics. It is an opportunity for biometrics and face recognition researchers to help the law enforcement and forensic experts in giving an identity to unidentified human skulls. It is an extremely challenging problem which is further exacerbated due to lack of any publicly available database related to this problem. This is the first research in this direction with a two-fold contribution: (i) introducing the first of its kind skull-face image pair database, IdentifyMe, and (ii) presenting a preliminary approach using the proposed semi-supervised formulation of transform learning. The experimental results and comparison with existing algorithms showcase the challenging nature of the problem. We assert that the availability of the database will inspire researchers to build sophisticated skull-to-face matching algorithms.