 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsaf Shabtai
CodeCloak: A Method for Evaluating and Mitigating Code Leakage by LLM Code Assistants
Apr 13, 2024
LLM-based code assistants are becoming increasingly popular among developers. These tools help developers improve their coding efficiency and reduce errors by providing real-time suggestions based on the developer's codebase. While beneficial, these tools might inadvertently expose the developer's proprietary code to the code assistant service provider during the development process. In this work, we propose two complementary methods to mitigate the risk of code leakage when using LLM-based code assistants. The first is a technique for reconstructing a developer's original codebase from code segments sent to the code assistant service (i.e., prompts) during the development process, enabling assessment and evaluation of the extent of code leakage to third parties (or adversaries). The second is CodeCloak, a novel deep reinforcement learning agent that manipulates the prompts before sending them to the code assistant service. CodeCloak aims to achieve the following two contradictory goals: (i) minimizing code leakage, while (ii) preserving relevant and useful suggestions for the developer. Our evaluation, employing GitHub Copilot, StarCoder, and CodeLlama LLM-based code assistants models, demonstrates the effectiveness of our CodeCloak approach on a diverse set of code repositories of varying sizes, as well as its transferability across different models. In addition, we generate a realistic simulated coding environment to thoroughly analyze code leakage risks and evaluate the effectiveness of our proposed mitigation techniques under practical development scenarios.
Prompted Contextual Vectors for Spear-Phishing Detection
Feb 14, 2024Spear-phishing attacks present a significant security challenge, with large language models (LLMs) escalating the threat by generating convincing emails and facilitating target reconnaissance. To address this, we propose a detection approach based on a novel document vectorization method that utilizes an ensemble of LLMs to create representation vectors. By prompting LLMs to reason and respond to human-crafted questions, we quantify the presence of common persuasion principles in the email's content, producing prompted contextual document vectors for a downstream supervised machine learning model. We evaluate our method using a unique dataset generated by a proprietary system that automates target reconnaissance and spear-phishing email creation. Our method achieves a 91% F1 score in identifying LLM-generated spear-phishing emails, with the training set comprising only traditional phishing and benign emails. Key contributions include an innovative document vectorization method utilizing LLM reasoning, a publicly available dataset of high-quality spear-phishing emails, and the demonstrated effectiveness of our method in detecting such emails. This methodology can be utilized for various document classification tasks, particularly in adversarial problem domains.
DeSparsify: Adversarial Attack Against Token Sparsification Mechanisms in Vision Transformers
Feb 04, 2024Vision transformers have contributed greatly to advancements in the computer vision domain, demonstrating state-of-the-art performance in diverse tasks (e.g., image classification, object detection). However, their high computational requirements grow quadratically with the number of tokens used. Token sparsification techniques have been proposed to address this issue. These techniques employ an input-dependent strategy, in which uninformative tokens are discarded from the computation pipeline, improving the model's efficiency. However, their dynamism and average-case assumption makes them vulnerable to a new threat vector - carefully crafted adversarial examples capable of fooling the sparsification mechanism, resulting in worst-case performance. In this paper, we present DeSparsify, an attack targeting the availability of vision transformers that use token sparsification mechanisms. The attack aims to exhaust the operating system's resources, while maintaining its stealthiness. Our evaluation demonstrates the attack's effectiveness on three token sparsification techniques and examines the attack's transferability between them and its effect on the GPU resources. To mitigate the impact of the attack, we propose various countermeasures.
GPT in Sheep's Clothing: The Risk of Customized GPTs
Jan 17, 2024In November 2023, OpenAI introduced a new service allowing users to create custom versions of ChatGPT (GPTs) by using specific instructions and knowledge to guide the model's behavior. We aim to raise awareness of the fact that GPTs can be used maliciously, posing privacy and security risks to their users.
QuantAttack: Exploiting Dynamic Quantization to Attack Vision Transformers
Dec 03, 2023In recent years, there has been a significant trend in deep neural networks (DNNs), particularly transformer-based models, of developing ever-larger and more capable models. While they demonstrate state-of-the-art performance, their growing scale requires increased computational resources (e.g., GPUs with greater memory capacity). To address this problem, quantization techniques (i.e., low-bit-precision representation and matrix multiplication) have been proposed. Most quantization techniques employ a static strategy in which the model parameters are quantized, either during training or inference, without considering the test-time sample. In contrast, dynamic quantization techniques, which have become increasingly popular, adapt during inference based on the input provided, while maintaining full-precision performance. However, their dynamic behavior and average-case performance assumption makes them vulnerable to a novel threat vector -- adversarial attacks that target the model's efficiency and availability. In this paper, we present QuantAttack, a novel attack that targets the availability of quantized models, slowing down the inference, and increasing memory usage and energy consumption. We show that carefully crafted adversarial examples, which are designed to exhaust the resources of the operating system, can trigger worst-case performance. In our experiments, we demonstrate the effectiveness of our attack on vision transformers on a wide range of tasks, both uni-modal and multi-modal. We also examine the effect of different attack variants (e.g., a universal perturbation) and the transferability between different models.
Detecting Anomalous Network Communication Patterns Using Graph Convolutional Networks
Nov 30, 2023
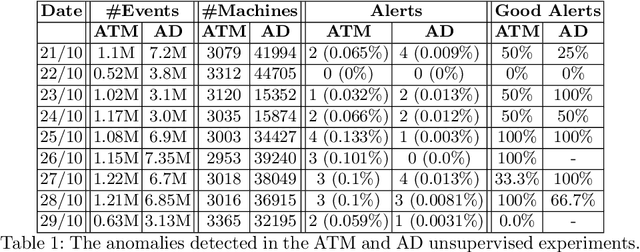

To protect an organizations' endpoints from sophisticated cyberattacks, advanced detection methods are required. In this research, we present GCNetOmaly: a graph convolutional network (GCN)-based variational autoencoder (VAE) anomaly detector trained on data that include connection events among internal and external machines. As input, the proposed GCN-based VAE model receives two matrices: (i) the normalized adjacency matrix, which represents the connections among the machines, and (ii) the feature matrix, which includes various features (demographic, statistical, process-related, and Node2vec structural features) that are used to profile the individual nodes/machines. After training the model on data collected for a predefined time window, the model is applied on the same data; the reconstruction score obtained by the model for a given machine then serves as the machine's anomaly score. GCNetOmaly was evaluated on real, large-scale data logged by Carbon Black EDR from a large financial organization's automated teller machines (ATMs) as well as communication with Active Directory (AD) servers in two setups: unsupervised and supervised. The results of our evaluation demonstrate GCNetOmaly's effectiveness in detecting anomalous behavior of machines on unsupervised data.
X-Detect: Explainable Adversarial Patch Detection for Object Detectors in Retail
Jul 02, 2023
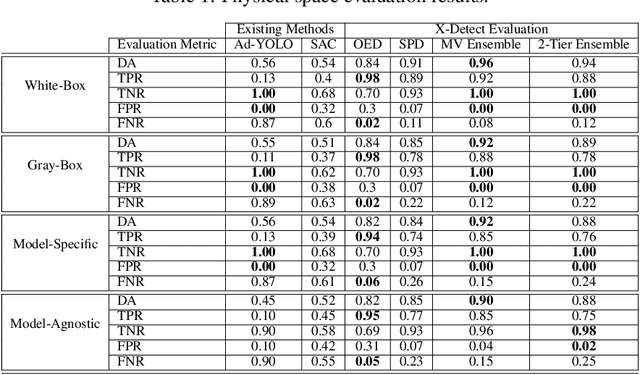
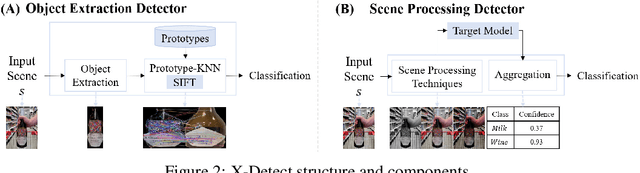
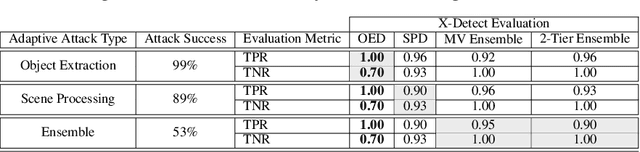
Object detection models, which are widely used in various domains (such as retail), have been shown to be vulnerable to adversarial attacks. Existing methods for detecting adversarial attacks on object detectors have had difficulty detecting new real-life attacks. We present X-Detect, a novel adversarial patch detector that can: i) detect adversarial samples in real time, allowing the defender to take preventive action; ii) provide explanations for the alerts raised to support the defender's decision-making process, and iii) handle unfamiliar threats in the form of new attacks. Given a new scene, X-Detect uses an ensemble of explainable-by-design detectors that utilize object extraction, scene manipulation, and feature transformation techniques to determine whether an alert needs to be raised. X-Detect was evaluated in both the physical and digital space using five different attack scenarios (including adaptive attacks) and the COCO dataset and our new Superstore dataset. The physical evaluation was performed using a smart shopping cart setup in real-world settings and included 17 adversarial patch attacks recorded in 1,700 adversarial videos. The results showed that X-Detect outperforms the state-of-the-art methods in distinguishing between benign and adversarial scenes for all attack scenarios while maintaining a 0% FPR (no false alarms) and providing actionable explanations for the alerts raised. A demo is available.
ReMark: Receptive Field based Spatial WaterMark Embedding Optimization using Deep Network
May 11, 2023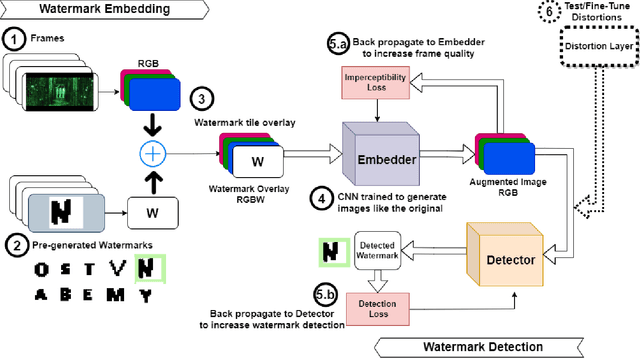
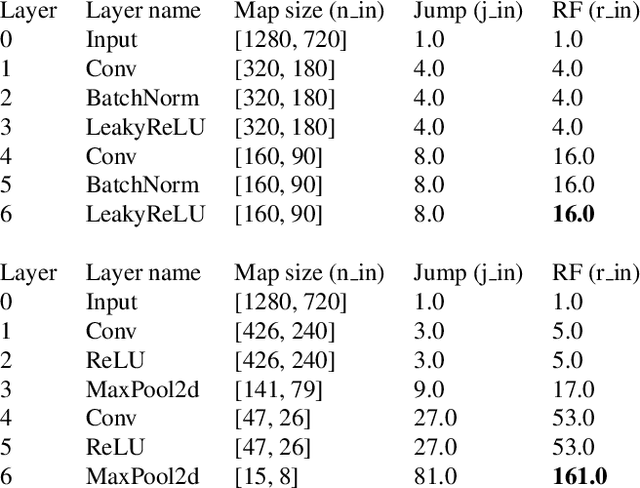
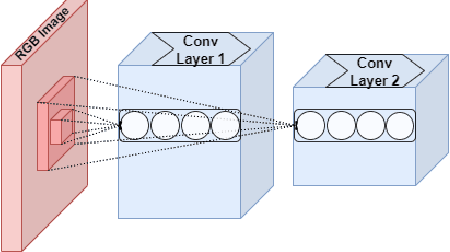

Watermarking is one of the most important copyright protection tools for digital media. The most challenging type of watermarking is the imperceptible one, which embeds identifying information in the data while retaining the latter's original quality. To fulfill its purpose, watermarks need to withstand various distortions whose goal is to damage their integrity. In this study, we investigate a novel deep learning-based architecture for embedding imperceptible watermarks. The key insight guiding our architecture design is the need to correlate the dimensions of our watermarks with the sizes of receptive fields (RF) of modules of our architecture. This adaptation makes our watermarks more robust, while also enabling us to generate them in a way that better maintains image quality. Extensive evaluations on a wide variety of distortions show that the proposed method is robust against most common distortions on watermarks including collusive distortion.
CADeSH: Collaborative Anomaly Detection for Smart Homes
Mar 02, 2023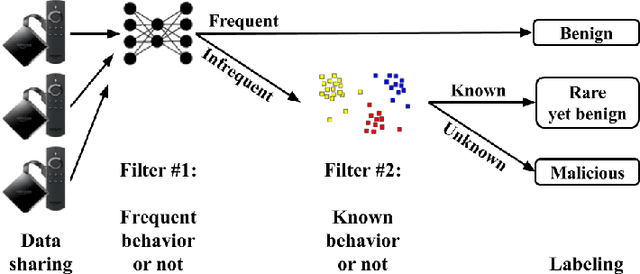
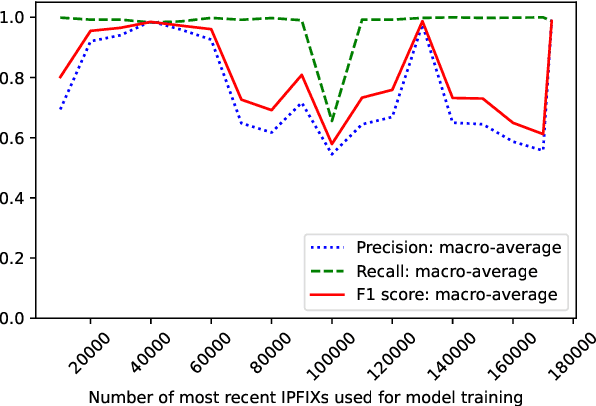

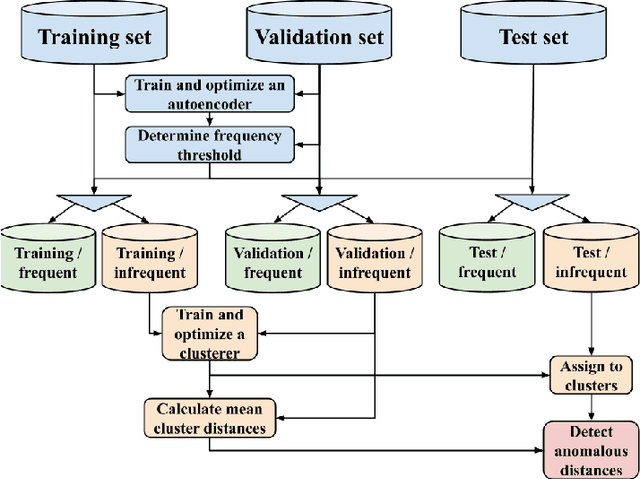
Although home IoT (Internet of Things) devices are typically plain and task oriented, the context of their daily use may affect their traffic patterns. For this reason, anomaly-based intrusion detection systems tend to suffer from a high false positive rate (FPR). To overcome this, we propose a two-step collaborative anomaly detection method which first uses an autoencoder to differentiate frequent (`benign') and infrequent (possibly `malicious') traffic flows. Clustering is then used to analyze only the infrequent flows and classify them as either known ('rare yet benign') or unknown (`malicious'). Our method is collaborative, in that (1) normal behaviors are characterized more robustly, as they take into account a variety of user interactions and network topologies, and (2) several features are computed based on a pool of identical devices rather than just the inspected device. We evaluated our method empirically, using 21 days of real-world traffic data that emanated from eight identical IoT devices deployed on various networks, one of which was located in our controlled lab where we implemented two popular IoT-related cyber-attacks. Our collaborative anomaly detection method achieved a macro-average area under the precision-recall curve of 0.841, an F1 score of 0.929, and an FPR of only 0.014. These promising results were obtained by using labeled traffic data from our lab as the test set, while training the models on the traffic of devices deployed outside the lab, and thus demonstrate a high level of generalizability. In addition to its high generalizability and promising performance, our proposed method also offers benefits such as privacy preservation, resource savings, and model poisoning mitigation. On top of that, as a contribution to the scientific community, our novel dataset is available online.
YolOOD: Utilizing Object Detection Concepts for Out-of-Distribution Detection
Dec 05, 2022
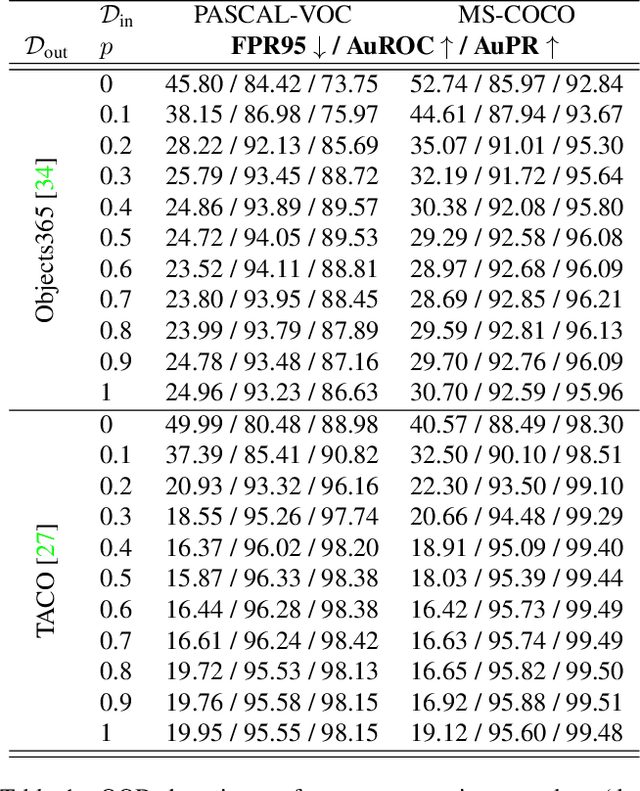
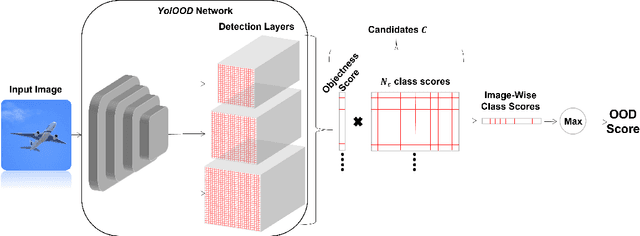
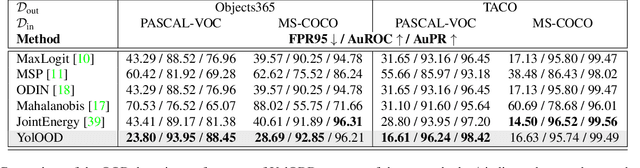
Out-of-distribution (OOD) detection has attracted a large amount of attention from the machine learning research community in recent years due to its importance in deployed systems. Most of the previous studies focused on the detection of OOD samples in the multi-class classification task. However, OOD detection in the multi-label classification task remains an underexplored domain. In this research, we propose YolOOD - a method that utilizes concepts from the object detection domain to perform OOD detection in the multi-label classification task. Object detection models have an inherent ability to distinguish between objects of interest (in-distribution) and irrelevant objects (e.g., OOD objects) on images that contain multiple objects from different categories. These abilities allow us to convert a regular object detection model into an image classifier with inherent OOD detection capabilities with just minor changes. We compare our approach to state-of-the-art OOD detection methods and demonstrate YolOOD's ability to outperform these methods on a comprehensive suite of in-distribution and OOD benchmark datasets.