 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDudu Mimran
CodeCloak: A Method for Evaluating and Mitigating Code Leakage by LLM Code Assistants
Apr 13, 2024
LLM-based code assistants are becoming increasingly popular among developers. These tools help developers improve their coding efficiency and reduce errors by providing real-time suggestions based on the developer's codebase. While beneficial, these tools might inadvertently expose the developer's proprietary code to the code assistant service provider during the development process. In this work, we propose two complementary methods to mitigate the risk of code leakage when using LLM-based code assistants. The first is a technique for reconstructing a developer's original codebase from code segments sent to the code assistant service (i.e., prompts) during the development process, enabling assessment and evaluation of the extent of code leakage to third parties (or adversaries). The second is CodeCloak, a novel deep reinforcement learning agent that manipulates the prompts before sending them to the code assistant service. CodeCloak aims to achieve the following two contradictory goals: (i) minimizing code leakage, while (ii) preserving relevant and useful suggestions for the developer. Our evaluation, employing GitHub Copilot, StarCoder, and CodeLlama LLM-based code assistants models, demonstrates the effectiveness of our CodeCloak approach on a diverse set of code repositories of varying sizes, as well as its transferability across different models. In addition, we generate a realistic simulated coding environment to thoroughly analyze code leakage risks and evaluate the effectiveness of our proposed mitigation techniques under practical development scenarios.
Adversarial Machine Learning Threat Analysis in Open Radio Access Networks
Jan 16, 2022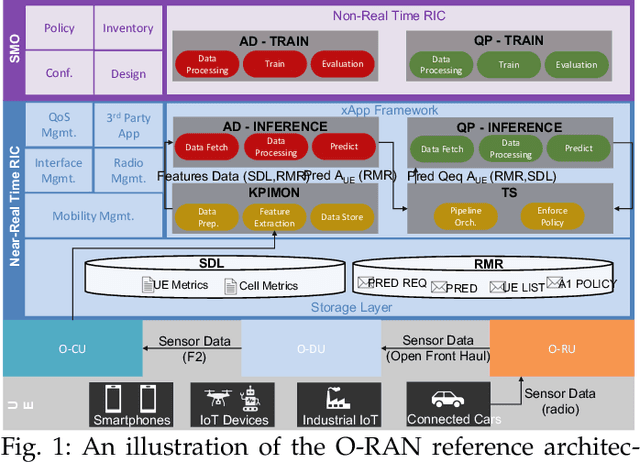
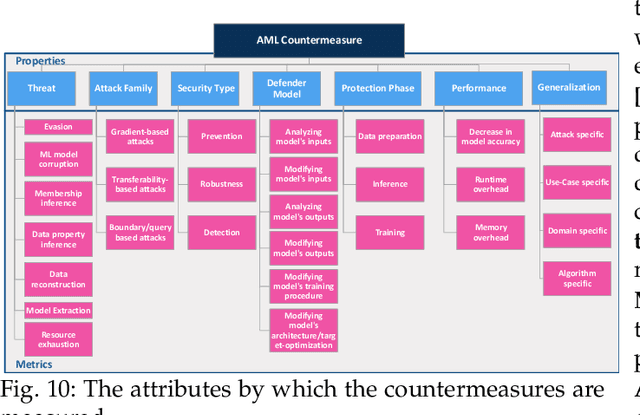

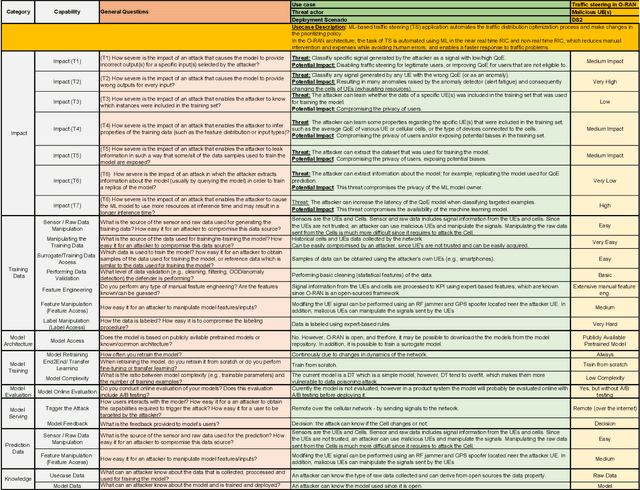
The Open Radio Access Network (O-RAN) is a new, open, adaptive, and intelligent RAN architecture. Motivated by the success of artificial intelligence in other domains, O-RAN strives to leverage machine learning (ML) to automatically and efficiently manage network resources in diverse use cases such as traffic steering, quality of experience prediction, and anomaly detection. Unfortunately, ML-based systems are not free of vulnerabilities; specifically, they suffer from a special type of logical vulnerabilities that stem from the inherent limitations of the learning algorithms. To exploit these vulnerabilities, an adversary can utilize an attack technique referred to as adversarial machine learning (AML). These special type of attacks has already been demonstrated in recent researches. In this paper, we present a systematic AML threat analysis for the O-RAN. We start by reviewing relevant ML use cases and analyzing the different ML workflow deployment scenarios in O-RAN. Then, we define the threat model, identifying potential adversaries, enumerating their adversarial capabilities, and analyzing their main goals. Finally, we explore the various AML threats in the O-RAN and review a large number of attacks that can be performed to materialize these threats and demonstrate an AML attack on a traffic steering model.