 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtsushi Hashimoto
Exo2EgoDVC: Dense Video Captioning of Egocentric Procedural Activities Using Web Instructional Videos
Nov 29, 2023
We propose a novel benchmark for cross-view knowledge transfer of dense video captioning, adapting models from web instructional videos with exocentric views to an egocentric view. While dense video captioning (predicting time segments and their captions) is primarily studied with exocentric videos (e.g., YouCook2), benchmarks with egocentric videos are restricted due to data scarcity. To overcome the limited video availability, transferring knowledge from abundant exocentric web videos is demanded as a practical approach. However, learning the correspondence between exocentric and egocentric views is difficult due to their dynamic view changes. The web videos contain mixed views focusing on either human body actions or close-up hand-object interactions, while the egocentric view is constantly shifting as the camera wearer moves. This necessitates the in-depth study of cross-view transfer under complex view changes. In this work, we first create a real-life egocentric dataset (EgoYC2) whose captions are shared with YouCook2, enabling transfer learning between these datasets assuming their ground-truth is accessible. To bridge the view gaps, we propose a view-invariant learning method using adversarial training in both the pre-training and fine-tuning stages. While the pre-training is designed to learn invariant features against the mixed views in the web videos, the view-invariant fine-tuning further mitigates the view gaps between both datasets. We validate our proposed method by studying how effectively it overcomes the view change problem and efficiently transfers the knowledge to the egocentric domain. Our benchmark pushes the study of the cross-view transfer into a new task domain of dense video captioning and will envision methodologies to describe egocentric videos in natural language.
Vision-Language Interpreter for Robot Task Planning
Nov 02, 2023Large language models (LLMs) are accelerating the development of language-guided robot planners. Meanwhile, symbolic planners offer the advantage of interpretability. This paper proposes a new task that bridges these two trends, namely, multimodal planning problem specification. The aim is to generate a problem description (PD), a machine-readable file used by the planners to find a plan. By generating PDs from language instruction and scene observation, we can drive symbolic planners in a language-guided framework. We propose a Vision-Language Interpreter (ViLaIn), a new framework that generates PDs using state-of-the-art LLM and vision-language models. ViLaIn can refine generated PDs via error message feedback from the symbolic planner. Our aim is to answer the question: How accurately can ViLaIn and the symbolic planner generate valid robot plans? To evaluate ViLaIn, we introduce a novel dataset called the problem description generation (ProDG) dataset. The framework is evaluated with four new evaluation metrics. Experimental results show that ViLaIn can generate syntactically correct problems with more than 99% accuracy and valid plans with more than 58% accuracy.
WeaveNet for Approximating Two-sided Matching Problems
Oct 19, 2023Matching, a task to optimally assign limited resources under constraints, is a fundamental technology for society. The task potentially has various objectives, conditions, and constraints; however, the efficient neural network architecture for matching is underexplored. This paper proposes a novel graph neural network (GNN), \textit{WeaveNet}, designed for bipartite graphs. Since a bipartite graph is generally dense, general GNN architectures lose node-wise information by over-smoothing when deeply stacked. Such a phenomenon is undesirable for solving matching problems. WeaveNet avoids it by preserving edge-wise information while passing messages densely to reach a better solution. To evaluate the model, we approximated one of the \textit{strongly NP-hard} problems, \textit{fair stable matching}. Despite its inherent difficulties and the network's general purpose design, our model reached a comparative performance with state-of-the-art algorithms specially designed for stable matching for small numbers of agents.
A Critical Look at the Current Usage of Foundation Model for Dense Recognition Task
Aug 01, 2023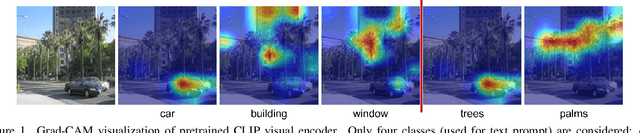
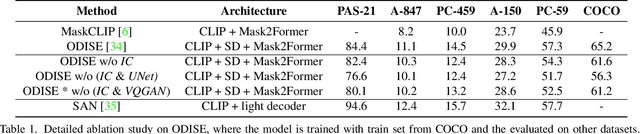


In recent years large model trained on huge amount of cross-modality data, which is usually be termed as foundation model, achieves conspicuous accomplishment in many fields, such as image recognition and generation. Though achieving great success in their original application case, it is still unclear whether those foundation models can be applied to other different downstream tasks. In this paper, we conduct a short survey on the current methods for discriminative dense recognition tasks, which are built on the pretrained foundation model. And we also provide some preliminary experimental analysis of an existing open-vocabulary segmentation method based on Stable Diffusion, which indicates the current way of deploying diffusion model for segmentation is not optimal. This aims to provide insights for future research on adopting foundation model for downstream task.
Noisy Universal Domain Adaptation via Divergence Optimization for Visual Recognition
Apr 20, 2023



To transfer the knowledge learned from a labeled source domain to an unlabeled target domain, many studies have worked on universal domain adaptation (UniDA), where there is no constraint on the label sets of the source domain and target domain. However, the existing UniDA methods rely on source samples with correct annotations. Due to the limited resources in the real world, it is difficult to obtain a large amount of perfectly clean labeled data in a source domain in some applications. As a result, we propose a novel realistic scenario named Noisy UniDA, in which classifiers are trained using noisy labeled data from the source domain as well as unlabeled domain data from the target domain that has an uncertain class distribution. A multi-head convolutional neural network framework is proposed in this paper to address all of the challenges faced in the Noisy UniDA at once. Our network comprises a single common feature generator and multiple classifiers with various decision bounds. We can detect noisy samples in the source domain, identify unknown classes in the target domain, and align the distribution of the source and target domains by optimizing the divergence between the outputs of the various classifiers. The proposed method outperformed the existing methods in most of the settings after a thorough analysis of the various domain adaption scenarios. The source code is available at \url{https://github.com/YU1ut/Divergence-Optimization}.
Recipe Generation from Unsegmented Cooking Videos
Sep 21, 2022



This paper tackles recipe generation from unsegmented cooking videos, a task that requires agents to (1) extract key events in completing the dish and (2) generate sentences for the extracted events. Our task is similar to dense video captioning (DVC), which aims at detecting events thoroughly and generating sentences for them. However, unlike DVC, in recipe generation, recipe story awareness is crucial, and a model should output an appropriate number of key events in the correct order. We analyze the output of the DVC model and observe that although (1) several events are adoptable as a recipe story, (2) the generated sentences for such events are not grounded in the visual content. Based on this, we hypothesize that we can obtain correct recipes by selecting oracle events from the output events of the DVC model and re-generating sentences for them. To achieve this, we propose a novel transformer-based joint approach of training event selector and sentence generator for selecting oracle events from the outputs of the DVC model and generating grounded sentences for the events, respectively. In addition, we extend the model by including ingredients to generate more accurate recipes. The experimental results show that the proposed method outperforms state-of-the-art DVC models. We also confirm that, by modeling the recipe in a story-aware manner, the proposed model output the appropriate number of events in the correct order.
Visual Recipe Flow: A Dataset for Learning Visual State Changes of Objects with Recipe Flows
Sep 13, 2022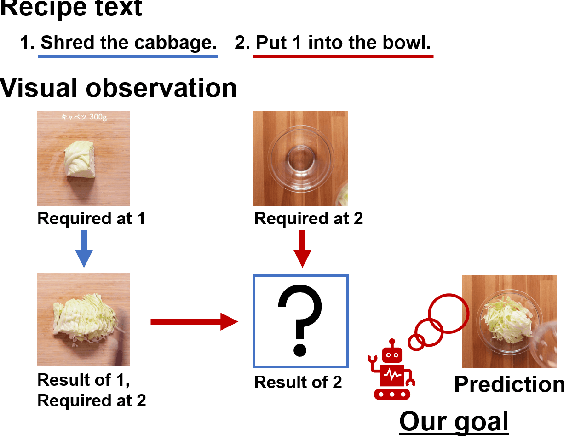

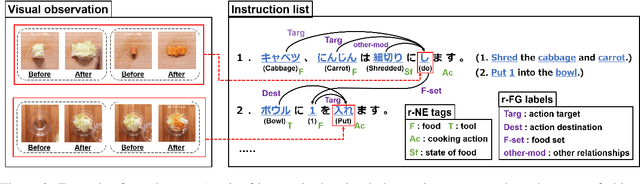
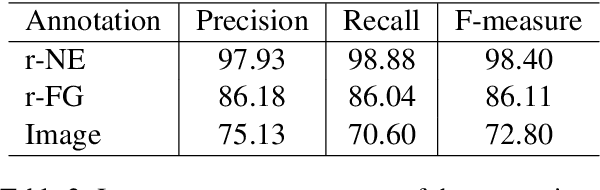
We present a new multimodal dataset called Visual Recipe Flow, which enables us to learn each cooking action result in a recipe text. The dataset consists of object state changes and the workflow of the recipe text. The state change is represented as an image pair, while the workflow is represented as a recipe flow graph (r-FG). The image pairs are grounded in the r-FG, which provides the cross-modal relation. With our dataset, one can try a range of applications, from multimodal commonsense reasoning and procedural text generation.
Edge-Selective Feature Weaving for Point Cloud Matching
Feb 08, 2022



This paper tackles the problem of accurately matching the points of two 3D point clouds. Most conventional methods improve their performance by extracting representative features from each point via deep-learning-based algorithms. On the other hand, the correspondence calculation between the extracted features has not been examined in depth, and non-trainable algorithms (e.g. the Sinkhorn algorithm) are frequently applied. As a result, the extracted features may be forcibly fitted to a non-trainable algorithm. Furthermore, the extracted features frequently contain stochastically unavoidable errors, which degrades the matching accuracy. In this paper, instead of using a non-trainable algorithm, we propose a differentiable matching network that can be jointly optimized with the feature extraction procedure. Our network first constructs graphs with edges connecting the points of each point cloud and then extracts discriminative edge features by using two main components: a shared set-encoder and an edge-selective cross-concatenation. These components enable us to symmetrically consider two point clouds and to extract discriminative edge features, respectively. By using the extracted discriminative edge features, our network can accurately calculate the correspondence between points. Our experimental results show that the proposed network can significantly improve the performance of point cloud matching. Our code is available at https://github.com/yanarin/ESFW
Foreground-Aware Stylization and Consensus Pseudo-Labeling for Domain Adaptation of First-Person Hand Segmentation
Jul 11, 2021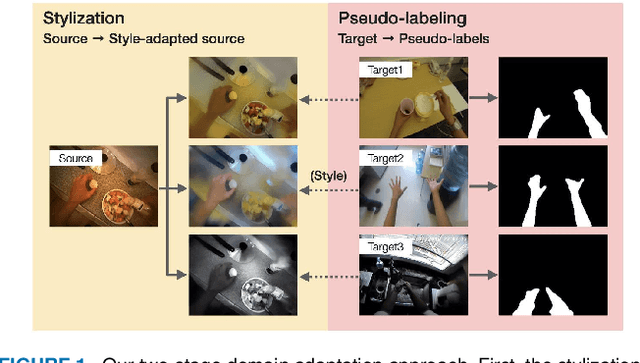
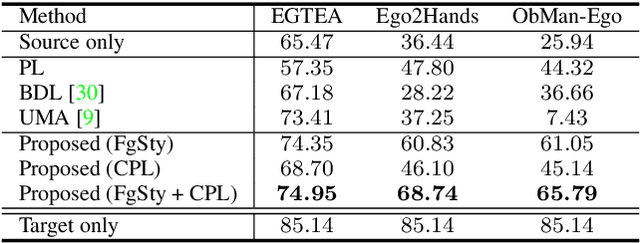


Hand segmentation is a crucial task in first-person vision. Since first-person images exhibit strong bias in appearance among different environments, adapting a pre-trained segmentation model to a new domain is required in hand segmentation. Here, we focus on appearance gaps for hand regions and backgrounds separately. We propose (i) foreground-aware image stylization and (ii) consensus pseudo-labeling for domain adaptation of hand segmentation. We stylize source images independently for the foreground and background using target images as style. To resolve the domain shift that the stylization has not addressed, we apply careful pseudo-labeling by taking a consensus between the models trained on the source and stylized source images. We validated our method on domain adaptation of hand segmentation from real and simulation images. Our method achieved state-of-the-art performance in both settings. We also demonstrated promising results in challenging multi-target domain adaptation and domain generalization settings. Code is available at https://github.com/ut-vision/FgSty-CPL.
Removing Word-Level Spurious Alignment between Images and Pseudo-Captions in Unsupervised Image Captioning
Apr 28, 2021



Unsupervised image captioning is a challenging task that aims at generating captions without the supervision of image-sentence pairs, but only with images and sentences drawn from different sources and object labels detected from the images. In previous work, pseudo-captions, i.e., sentences that contain the detected object labels, were assigned to a given image. The focus of the previous work was on the alignment of input images and pseudo-captions at the sentence level. However, pseudo-captions contain many words that are irrelevant to a given image. In this work, we investigate the effect of removing mismatched words from image-sentence alignment to determine how they make this task difficult. We propose a simple gating mechanism that is trained to align image features with only the most reliable words in pseudo-captions: the detected object labels. The experimental results show that our proposed method outperforms the previous methods without introducing complex sentence-level learning objectives. Combined with the sentence-level alignment method of previous work, our method further improves its performance. These results confirm the importance of careful alignment in word-level details.