 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuhei Kurita
Text-driven Affordance Learning from Egocentric Vision
Apr 03, 2024
Visual affordance learning is a key component for robots to understand how to interact with objects. Conventional approaches in this field rely on pre-defined objects and actions, falling short of capturing diverse interactions in realworld scenarios. The key idea of our approach is employing textual instruction, targeting various affordances for a wide range of objects. This approach covers both hand-object and tool-object interactions. We introduce text-driven affordance learning, aiming to learn contact points and manipulation trajectories from an egocentric view following textual instruction. In our task, contact points are represented as heatmaps, and the manipulation trajectory as sequences of coordinates that incorporate both linear and rotational movements for various manipulations. However, when we gather data for this task, manual annotations of these diverse interactions are costly. To this end, we propose a pseudo dataset creation pipeline and build a large pseudo-training dataset: TextAFF80K, consisting of over 80K instances of the contact points, trajectories, images, and text tuples. We extend existing referring expression comprehension models for our task, and experimental results show that our approach robustly handles multiple affordances, serving as a new standard for affordance learning in real-world scenarios.
JDocQA: Japanese Document Question Answering Dataset for Generative Language Models
Mar 28, 2024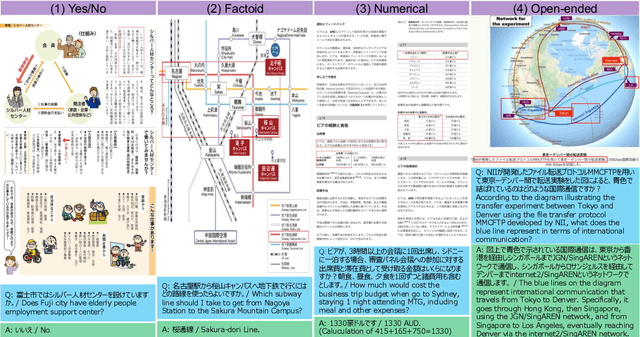

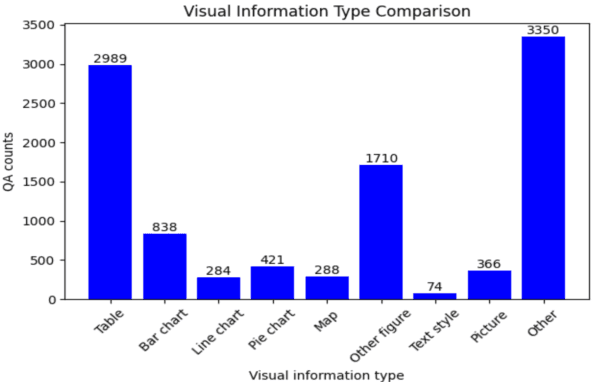
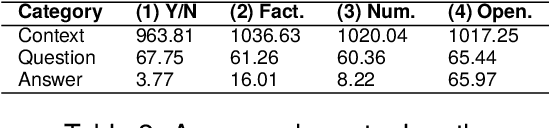
Document question answering is a task of question answering on given documents such as reports, slides, pamphlets, and websites, and it is a truly demanding task as paper and electronic forms of documents are so common in our society. This is known as a quite challenging task because it requires not only text understanding but also understanding of figures and tables, and hence visual question answering (VQA) methods are often examined in addition to textual approaches. We introduce Japanese Document Question Answering (JDocQA), a large-scale document-based QA dataset, essentially requiring both visual and textual information to answer questions, which comprises 5,504 documents in PDF format and annotated 11,600 question-and-answer instances in Japanese. Each QA instance includes references to the document pages and bounding boxes for the answer clues. We incorporate multiple categories of questions and unanswerable questions from the document for realistic question-answering applications. We empirically evaluate the effectiveness of our dataset with text-based large language models (LLMs) and multimodal models. Incorporating unanswerable questions in finetuning may contribute to harnessing the so-called hallucination generation.
Vision Language Model-based Caption Evaluation Method Leveraging Visual Context Extraction
Feb 28, 2024Given the accelerating progress of vision and language modeling, accurate evaluation of machine-generated image captions remains critical. In order to evaluate captions more closely to human preferences, metrics need to discriminate between captions of varying quality and content. However, conventional metrics fail short of comparing beyond superficial matches of words or embedding similarities; thus, they still need improvement. This paper presents VisCE$^2$, a vision language model-based caption evaluation method. Our method focuses on visual context, which refers to the detailed content of images, including objects, attributes, and relationships. By extracting and organizing them into a structured format, we replace the human-written references with visual contexts and help VLMs better understand the image, enhancing evaluation performance. Through meta-evaluation on multiple datasets, we validated that VisCE$^2$ outperforms the conventional pre-trained metrics in capturing caption quality and demonstrates superior consistency with human judgment.
SlideAVSR: A Dataset of Paper Explanation Videos for Audio-Visual Speech Recognition
Jan 18, 2024Audio-visual speech recognition (AVSR) is a multimodal extension of automatic speech recognition (ASR), using video as a complement to audio. In AVSR, considerable efforts have been directed at datasets for facial features such as lip-readings, while they often fall short in evaluating the image comprehension capabilities in broader contexts. In this paper, we construct SlideAVSR, an AVSR dataset using scientific paper explanation videos. SlideAVSR provides a new benchmark where models transcribe speech utterances with texts on the slides on the presentation recordings. As technical terminologies that are frequent in paper explanations are notoriously challenging to transcribe without reference texts, our SlideAVSR dataset spotlights a new aspect of AVSR problems. As a simple yet effective baseline, we propose DocWhisper, an AVSR model that can refer to textual information from slides, and confirm its effectiveness on SlideAVSR.
CityRefer: Geography-aware 3D Visual Grounding Dataset on City-scale Point Cloud Data
Oct 28, 2023City-scale 3D point cloud is a promising way to express detailed and complicated outdoor structures. It encompasses both the appearance and geometry features of segmented city components, including cars, streets, and buildings, that can be utilized for attractive applications such as user-interactive navigation of autonomous vehicles and drones. However, compared to the extensive text annotations available for images and indoor scenes, the scarcity of text annotations for outdoor scenes poses a significant challenge for achieving these applications. To tackle this problem, we introduce the CityRefer dataset for city-level visual grounding. The dataset consists of 35k natural language descriptions of 3D objects appearing in SensatUrban city scenes and 5k landmarks labels synchronizing with OpenStreetMap. To ensure the quality and accuracy of the dataset, all descriptions and labels in the CityRefer dataset are manually verified. We also have developed a baseline system that can learn encoded language descriptions, 3D object instances, and geographical information about the city's landmarks to perform visual grounding on the CityRefer dataset. To the best of our knowledge, the CityRefer dataset is the largest city-level visual grounding dataset for localizing specific 3D objects.
RefEgo: Referring Expression Comprehension Dataset from First-Person Perception of Ego4D
Aug 23, 2023Grounding textual expressions on scene objects from first-person views is a truly demanding capability in developing agents that are aware of their surroundings and behave following intuitive text instructions. Such capability is of necessity for glass-devices or autonomous robots to localize referred objects in the real-world. In the conventional referring expression comprehension tasks of images, however, datasets are mostly constructed based on the web-crawled data and don't reflect diverse real-world structures on the task of grounding textual expressions in diverse objects in the real world. Recently, a massive-scale egocentric video dataset of Ego4D was proposed. Ego4D covers around the world diverse real-world scenes including numerous indoor and outdoor situations such as shopping, cooking, walking, talking, manufacturing, etc. Based on egocentric videos of Ego4D, we constructed a broad coverage of the video-based referring expression comprehension dataset: RefEgo. Our dataset includes more than 12k video clips and 41 hours for video-based referring expression comprehension annotation. In experiments, we combine the state-of-the-art 2D referring expression comprehension models with the object tracking algorithm, achieving the video-wise referred object tracking even in difficult conditions: the referred object becomes out-of-frame in the middle of the video or multiple similar objects are presented in the video.
Cross3DVG: Baseline and Dataset for Cross-Dataset 3D Visual Grounding on Different RGB-D Scans
May 23, 2023



We present Cross3DVG, a novel task for cross-dataset visual grounding in 3D scenes, revealing the limitations of existing 3D visual grounding models using restricted 3D resources and thus easily overfit to a specific 3D dataset. To facilitate Cross3DVG, we have created a large-scale 3D visual grounding dataset containing more than 63k diverse descriptions of 3D objects within 1,380 indoor RGB-D scans from 3RScan with human annotations, paired with the existing 52k descriptions on ScanRefer. We perform Cross3DVG by training a model on the source 3D visual grounding dataset and then evaluating it on the target dataset constructed in different ways (e.g., different sensors, 3D reconstruction methods, and language annotators) without using target labels. We conduct comprehensive experiments using established visual grounding models, as well as a CLIP-based 2D-3D integration method, designed to bridge the gaps between 3D datasets. By performing Cross3DVG tasks, we found that (i) cross-dataset 3D visual grounding has significantly lower performance than learning and evaluation with a single dataset, suggesting much room for improvement in cross-dataset generalization of 3D visual grounding, (ii) better detectors and transformer-based localization modules for 3D grounding are beneficial for enhancing 3D grounding performance and (iii) fusing 2D-3D data using CLIP demonstrates further performance improvements. Our Cross3DVG task will provide a benchmark for developing robust 3D visual grounding models capable of handling diverse 3D scenes while leveraging deep language understanding.
Visual Recipe Flow: A Dataset for Learning Visual State Changes of Objects with Recipe Flows
Sep 13, 2022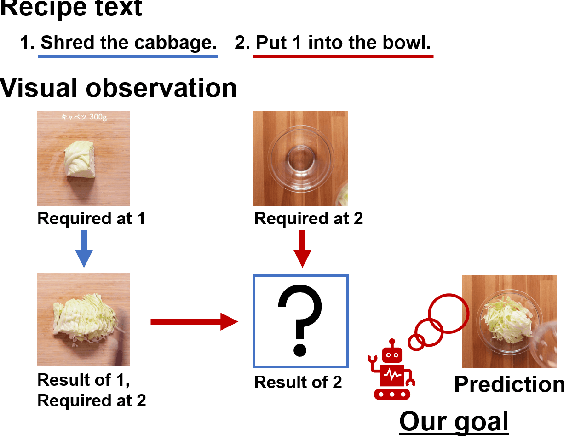

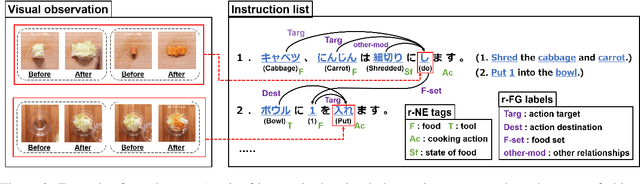
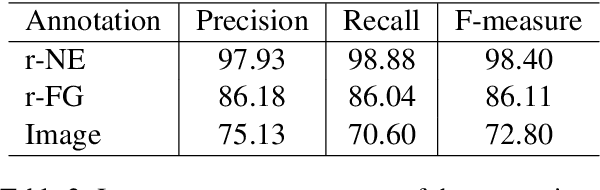
We present a new multimodal dataset called Visual Recipe Flow, which enables us to learn each cooking action result in a recipe text. The dataset consists of object state changes and the workflow of the recipe text. The state change is represented as an image pair, while the workflow is represented as a recipe flow graph (r-FG). The image pairs are grounded in the r-FG, which provides the cross-modal relation. With our dataset, one can try a range of applications, from multimodal commonsense reasoning and procedural text generation.
ScanQA: 3D Question Answering for Spatial Scene Understanding
Dec 20, 2021



We propose a new 3D spatial understanding task of 3D Question Answering (3D-QA). In the 3D-QA task, models receive visual information from the entire 3D scene of the rich RGB-D indoor scan and answer the given textual questions about the 3D scene. Unlike the 2D-question answering of VQA, the conventional 2D-QA models suffer from problems with spatial understanding of object alignment and directions and fail the object localization from the textual questions in 3D-QA. We propose a baseline model for 3D-QA, named ScanQA model, where the model learns a fused descriptor from 3D object proposals and encoded sentence embeddings. This learned descriptor correlates the language expressions with the underlying geometric features of the 3D scan and facilitates the regression of 3D bounding boxes to determine described objects in textual questions. We collected human-edited question-answer pairs with free-form answers that are grounded to 3D objects in each 3D scene. Our new ScanQA dataset contains over 41K question-answer pairs from the 800 indoor scenes drawn from the ScanNet dataset. To the best of our knowledge, ScanQA is the first large-scale effort to perform object-grounded question-answering in 3D environments.
Generative Language-Grounded Policy in Vision-and-Language Navigation with Bayes' Rule
Oct 08, 2020



Vision-and-language navigation (VLN) is a task in which an agent is embodied in a realistic 3D environment and follows an instruction to reach the goal node. While most of the previous studies have built and investigated a discriminative approach, we notice that there are in fact two possible approaches to building such a VLN agent: discriminative \textit{and} generative. In this paper, we design and investigate a generative language-grounded policy which uses a language model to compute the distribution over all possible instructions i.e. all possible sequences of vocabulary tokens given action and the transition history. In experiments, we show that the proposed generative approach outperforms the discriminative approach in the Room-2-Room (R2R) and Room-4-Room (R4R) datasets, especially in the unseen environments. We further show that the combination of the generative and discriminative policies achieves close to the state-of-the art results in the R2R dataset, demonstrating that the generative and discriminative policies capture the different aspects of VLN.