 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtsuyuki Miyai
Unsolvable Problem Detection: Evaluating Trustworthiness of Vision Language Models
Mar 29, 2024
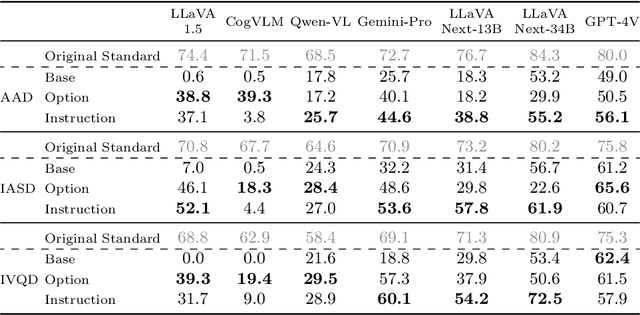


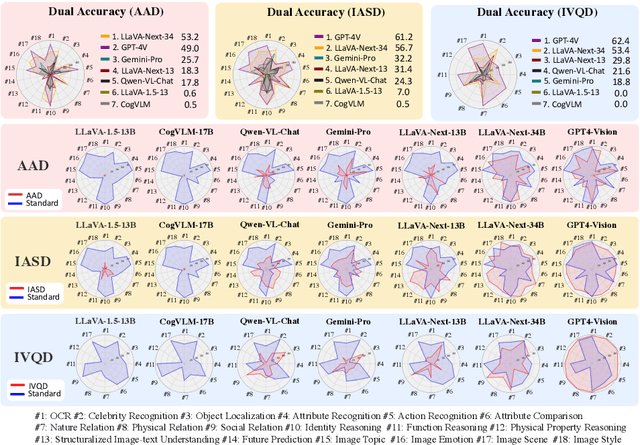
This paper introduces a novel and significant challenge for Vision Language Models (VLMs), termed Unsolvable Problem Detection (UPD). UPD examines the VLM's ability to withhold answers when faced with unsolvable problems in the context of Visual Question Answering (VQA) tasks. UPD encompasses three distinct settings: Absent Answer Detection (AAD), Incompatible Answer Set Detection (IASD), and Incompatible Visual Question Detection (IVQD). To deeply investigate the UPD problem, extensive experiments indicate that most VLMs, including GPT-4V and LLaVA-Next-34B, struggle with our benchmarks to varying extents, highlighting significant room for the improvements. To address UPD, we explore both training-free and training-based solutions, offering new insights into their effectiveness and limitations. We hope our insights, together with future efforts within the proposed UPD settings, will enhance the broader understanding and development of more practical and reliable VLMs.
Can Pre-trained Networks Detect Familiar Out-of-Distribution Data?
Oct 12, 2023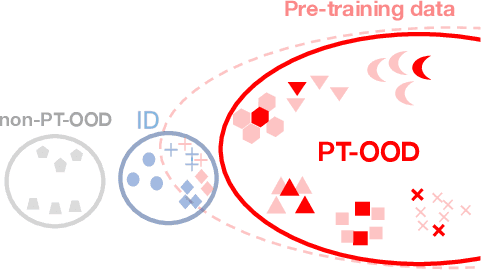
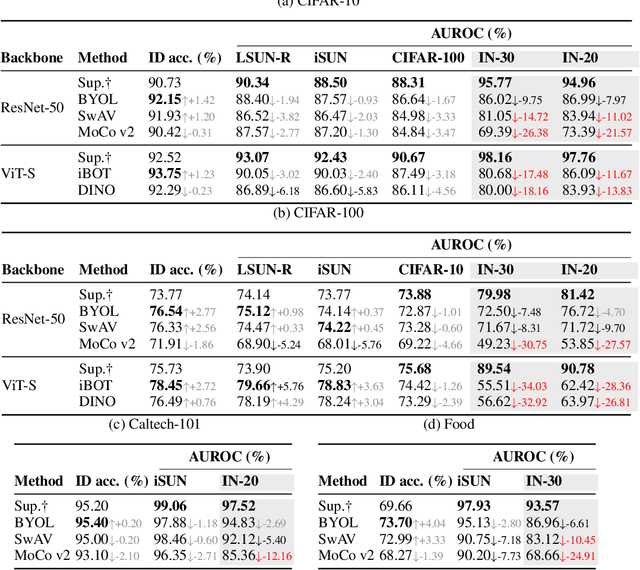
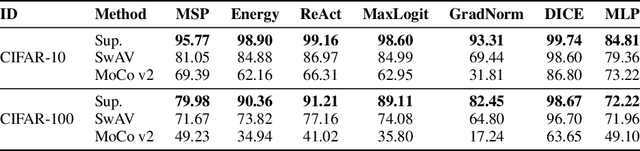
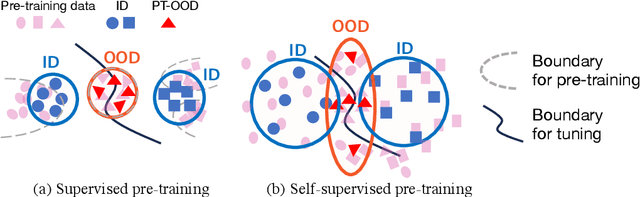
Out-of-distribution (OOD) detection is critical for safety-sensitive machine learning applications and has been extensively studied, yielding a plethora of methods developed in the literature. However, most studies for OOD detection did not use pre-trained models and trained a backbone from scratch. In recent years, transferring knowledge from large pre-trained models to downstream tasks by lightweight tuning has become mainstream for training in-distribution (ID) classifiers. To bridge the gap between the practice of OOD detection and current classifiers, the unique and crucial problem is that the samples whose information networks know often come as OOD input. We consider that such data may significantly affect the performance of large pre-trained networks because the discriminability of these OOD data depends on the pre-training algorithm. Here, we define such OOD data as PT-OOD (Pre-Trained OOD) data. In this paper, we aim to reveal the effect of PT-OOD on the OOD detection performance of pre-trained networks from the perspective of pre-training algorithms. To achieve this, we explore the PT-OOD detection performance of supervised and self-supervised pre-training algorithms with linear-probing tuning, the most common efficient tuning method. Through our experiments and analysis, we find that the low linear separability of PT-OOD in the feature space heavily degrades the PT-OOD detection performance, and self-supervised models are more vulnerable to PT-OOD than supervised pre-trained models, even with state-of-the-art detection methods. To solve this vulnerability, we further propose a unique solution to large-scale pre-trained models: Leveraging powerful instance-by-instance discriminative representations of pre-trained models and detecting OOD in the feature space independent of the ID decision boundaries. The code will be available via https://github.com/AtsuMiyai/PT-OOD.
LoCoOp: Few-Shot Out-of-Distribution Detection via Prompt Learning
Jun 10, 2023
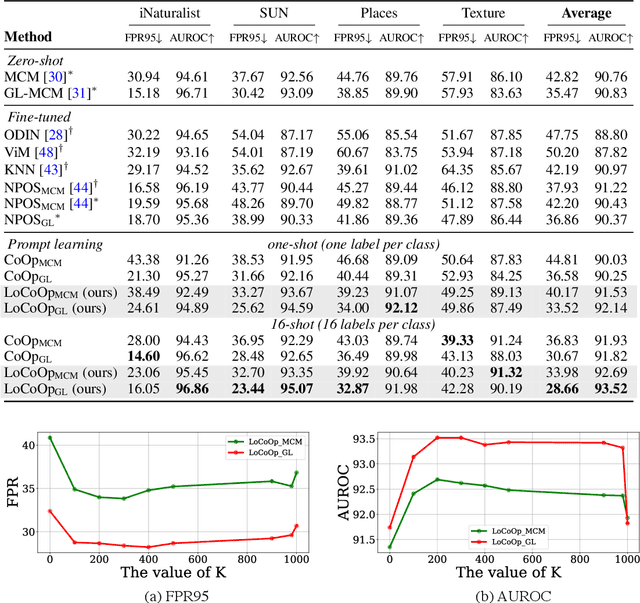
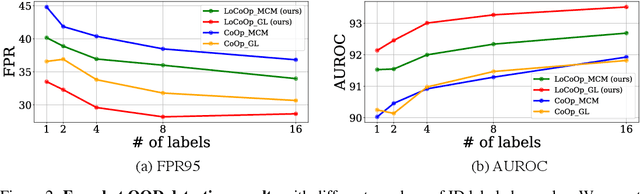

We present a novel vision-language prompt learning approach for few-shot out-of-distribution (OOD) detection. Few-shot OOD detection aims to detect OOD images from classes that are unseen during training using only a few labeled in-distribution (ID) images. While prompt learning methods such as CoOp have shown effectiveness and efficiency in few-shot ID classification, they still face limitations in OOD detection due to the potential presence of ID-irrelevant information in text embeddings. To address this issue, we introduce a new approach called Local regularized Context Optimization (LoCoOp), which performs OOD regularization that utilizes the portions of CLIP local features as OOD features during training. CLIP's local features have a lot of ID-irrelevant nuisances (e.g., backgrounds), and by learning to push them away from the ID class text embeddings, we can remove the nuisances in the ID class text embeddings and enhance the separation between ID and OOD. Experiments on the large-scale ImageNet OOD detection benchmarks demonstrate the superiority of our LoCoOp over zero-shot, fully supervised detection methods and prompt learning methods. Notably, even in a one-shot setting -- just one label per class, LoCoOp outperforms existing zero-shot and fully supervised detection methods. The code will be available via https://github.com/AtsuMiyai/LoCoOp.
Zero-Shot In-Distribution Detection in Multi-Object Settings Using Vision-Language Foundation Models
Apr 10, 2023



Removing out-of-distribution (OOD) images from noisy images scraped from the Internet is an important preprocessing for constructing datasets, which can be addressed by zero-shot OOD detection with vision language foundation models (CLIP). The existing zero-shot OOD detection setting does not consider the realistic case where an image has both in-distribution (ID) objects and OOD objects. However, it is important to identify such images as ID images when collecting the images of rare classes or ethically inappropriate classes that must not be missed. In this paper, we propose a novel problem setting called in-distribution (ID) detection, where we identify images containing ID objects as ID images, even if they contain OOD objects, and images lacking ID objects as OOD images. To solve this problem, we present a new approach, \textbf{G}lobal-\textbf{L}ocal \textbf{M}aximum \textbf{C}oncept \textbf{M}atching (GL-MCM), based on both global and local visual-text alignments of CLIP features, which can identify any image containing ID objects as ID images. Extensive experiments demonstrate that GL-MCM outperforms comparison methods on both multi-object datasets and single-object ImageNet benchmarks.
Rethinking Rotation in Self-Supervised Contrastive Learning: Adaptive Positive or Negative Data Augmentation
Oct 23, 2022



Rotation is frequently listed as a candidate for data augmentation in contrastive learning but seldom provides satisfactory improvements. We argue that this is because the rotated image is always treated as either positive or negative. The semantics of an image can be rotation-invariant or rotation-variant, so whether the rotated image is treated as positive or negative should be determined based on the content of the image. Therefore, we propose a novel augmentation strategy, adaptive Positive or Negative Data Augmentation (PNDA), in which an original and its rotated image are a positive pair if they are semantically close and a negative pair if they are semantically different. To achieve PNDA, we first determine whether rotation is positive or negative on an image-by-image basis in an unsupervised way. Then, we apply PNDA to contrastive learning frameworks. Our experiments showed that PNDA improves the performance of contrastive learning. The code is available at \url{ https://github.com/AtsuMiyai/rethinking_rotation}.