 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYifei Ming
Understanding Retrieval-Augmented Task Adaptation for Vision-Language Models
May 02, 2024
Pre-trained contrastive vision-language models have demonstrated remarkable performance across a wide range of tasks. However, they often struggle on fine-trained datasets with categories not adequately represented during pre-training, which makes adaptation necessary. Recent works have shown promising results by utilizing samples from web-scale databases for retrieval-augmented adaptation, especially in low-data regimes. Despite the empirical success, understanding how retrieval impacts the adaptation of vision-language models remains an open research question. In this work, we adopt a reflective perspective by presenting a systematic study to understand the roles of key components in retrieval-augmented adaptation. We unveil new insights on uni-modal and cross-modal retrieval and highlight the critical role of logit ensemble for effective adaptation. We further present theoretical underpinnings that directly support our empirical observations.
Unsolvable Problem Detection: Evaluating Trustworthiness of Vision Language Models
Mar 29, 2024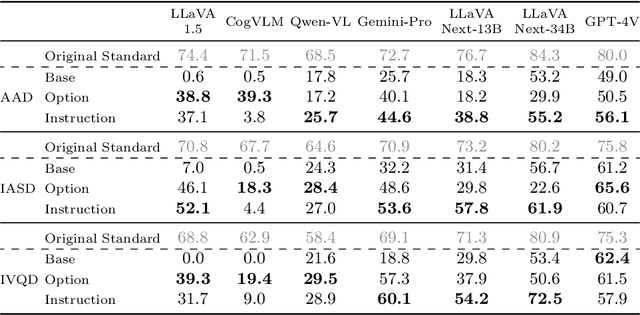


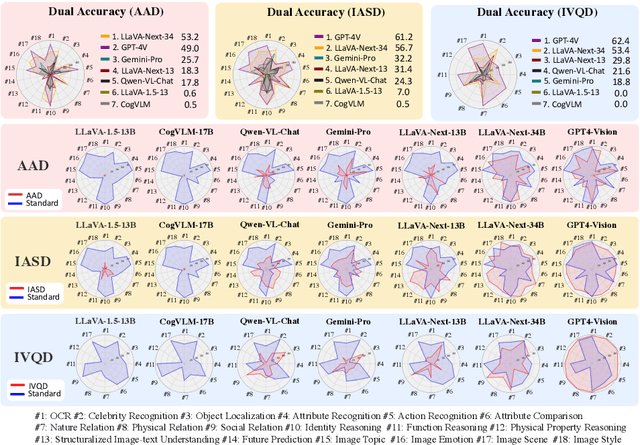
This paper introduces a novel and significant challenge for Vision Language Models (VLMs), termed Unsolvable Problem Detection (UPD). UPD examines the VLM's ability to withhold answers when faced with unsolvable problems in the context of Visual Question Answering (VQA) tasks. UPD encompasses three distinct settings: Absent Answer Detection (AAD), Incompatible Answer Set Detection (IASD), and Incompatible Visual Question Detection (IVQD). To deeply investigate the UPD problem, extensive experiments indicate that most VLMs, including GPT-4V and LLaVA-Next-34B, struggle with our benchmarks to varying extents, highlighting significant room for the improvements. To address UPD, we explore both training-free and training-based solutions, offering new insights into their effectiveness and limitations. We hope our insights, together with future efforts within the proposed UPD settings, will enhance the broader understanding and development of more practical and reliable VLMs.
HYPO: Hyperspherical Out-of-Distribution Generalization
Feb 12, 2024Out-of-distribution (OOD) generalization is critical for machine learning models deployed in the real world. However, achieving this can be fundamentally challenging, as it requires the ability to learn invariant features across different domains or environments. In this paper, we propose a novel framework HYPO (HYPerspherical OOD generalization) that provably learns domain-invariant representations in a hyperspherical space. In particular, our hyperspherical learning algorithm is guided by intra-class variation and inter-class separation principles -- ensuring that features from the same class (across different training domains) are closely aligned with their class prototypes, while different class prototypes are maximally separated. We further provide theoretical justifications on how our prototypical learning objective improves the OOD generalization bound. Through extensive experiments on challenging OOD benchmarks, we demonstrate that our approach outperforms competitive baselines and achieves superior performance. Code is available at https://github.com/deeplearning-wisc/hypo.
How Does Fine-Tuning Impact Out-of-Distribution Detection for Vision-Language Models?
Jun 09, 2023



Recent large vision-language models such as CLIP have shown remarkable out-of-distribution (OOD) detection and generalization performance. However, their zero-shot in-distribution (ID) accuracy is often limited for downstream datasets. Recent CLIP-based fine-tuning methods such as prompt learning have demonstrated significant improvements in ID classification and OOD generalization where OOD labels are available. Nonetheless, it remains unclear whether the model is reliable to semantic shifts without OOD labels. In this paper, we aim to bridge the gap and present a comprehensive study to understand how fine-tuning impact OOD detection for few-shot downstream tasks. By framing OOD detection as multi-modal concept matching, we establish a connection between fine-tuning methods and various OOD scores. Our results suggest that a proper choice of OOD scores is essential for CLIP-based fine-tuning. In particular, the maximum concept matching (MCM) score provides a promising solution consistently. We also show that prompt learning demonstrates the state-of-the-art OOD detection performance over the zero-shot counterpart.
Domain Generalization via Nuclear Norm Regularization
Mar 13, 2023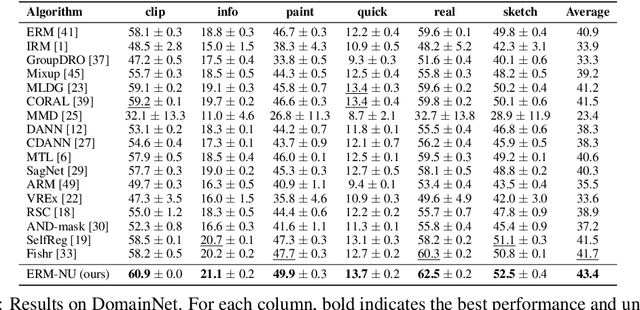
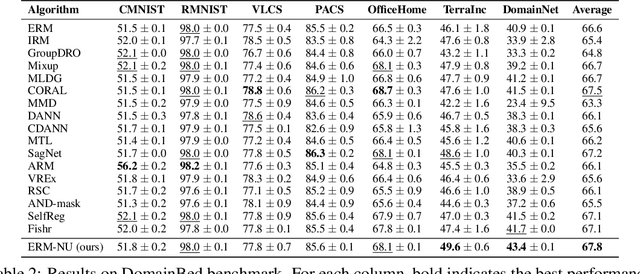
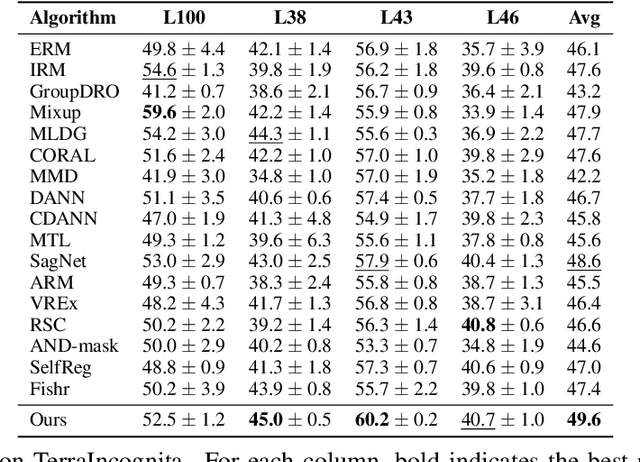
The ability to generalize to unseen domains is crucial for machine learning systems deployed in the real world, especially when we only have data from limited training domains. In this paper, we propose a simple and effective regularization method based on the nuclear norm of the learned features for domain generalization. Intuitively, the proposed regularizer mitigates the impacts of environmental features and encourages learning domain-invariant features. Theoretically, we provide insights into why nuclear norm regularization is more effective compared to ERM and alternative regularization methods. Empirically, we conduct extensive experiments on both synthetic and real datasets. We show that nuclear norm regularization achieves strong performance compared to baselines in a wide range of domain generalization tasks. Moreover, our regularizer is broadly applicable with various methods such as ERM and SWAD with consistently improved performance, e.g., 1.7% and 0.9% test accuracy improvements respectively on the DomainBed benchmark.
Delving into Out-of-Distribution Detection with Vision-Language Representations
Nov 24, 2022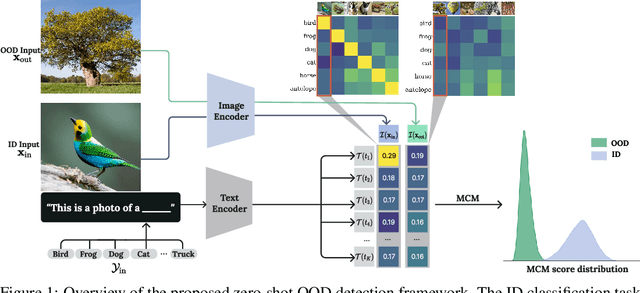
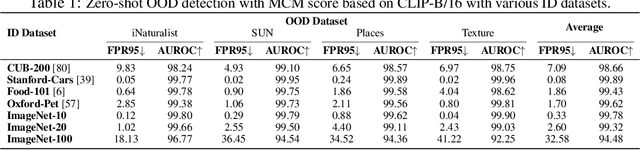
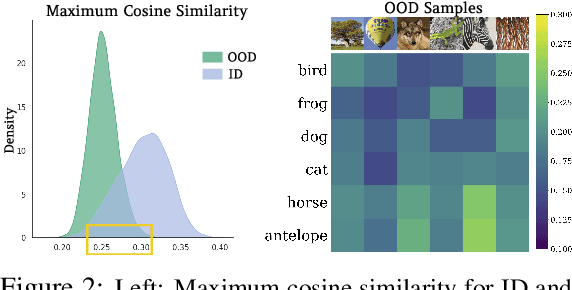
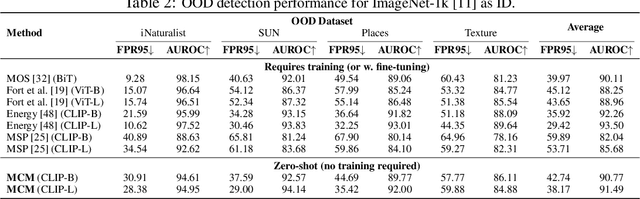
Recognizing out-of-distribution (OOD) samples is critical for machine learning systems deployed in the open world. The vast majority of OOD detection methods are driven by a single modality (e.g., either vision or language), leaving the rich information in multi-modal representations untapped. Inspired by the recent success of vision-language pre-training, this paper enriches the landscape of OOD detection from a single-modal to a multi-modal regime. Particularly, we propose Maximum Concept Matching (MCM), a simple yet effective zero-shot OOD detection method based on aligning visual features with textual concepts. We contribute in-depth analysis and theoretical insights to understand the effectiveness of MCM. Extensive experiments demonstrate that MCM achieves superior performance on a wide variety of real-world tasks. MCM with vision-language features outperforms a common baseline with pure visual features on a hard OOD task with semantically similar classes by 13.1% (AUROC). Code is available at https://github.com/deeplearning-wisc/MCM.
POEM: Out-of-Distribution Detection with Posterior Sampling
Jun 28, 2022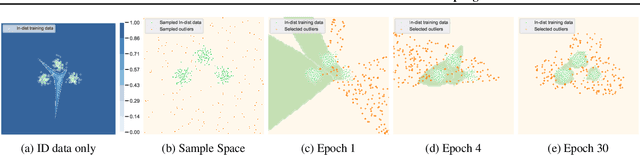
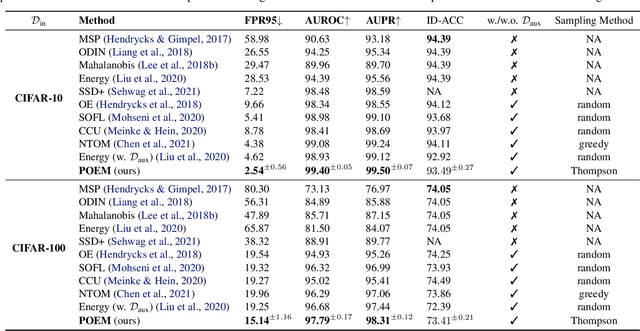
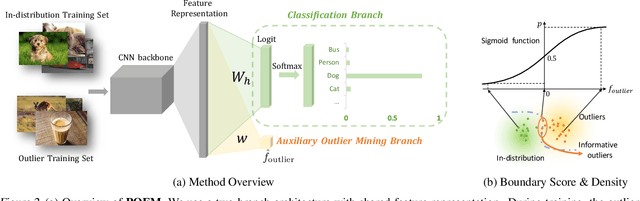

Out-of-distribution (OOD) detection is indispensable for machine learning models deployed in the open world. Recently, the use of an auxiliary outlier dataset during training (also known as outlier exposure) has shown promising performance. As the sample space for potential OOD data can be prohibitively large, sampling informative outliers is essential. In this work, we propose a novel posterior sampling-based outlier mining framework, POEM, which facilitates efficient use of outlier data and promotes learning a compact decision boundary between ID and OOD data for improved detection. We show that POEM establishes state-of-the-art performance on common benchmarks. Compared to the current best method that uses a greedy sampling strategy, POEM improves the relative performance by 42.0% and 24.2% (FPR95) on CIFAR-10 and CIFAR-100, respectively. We further provide theoretical insights on the effectiveness of POEM for OOD detection.
* ICML 2022 (Long Talk); First two authors contributed equally
Utilizing Language-Image Pretraining for Efficient and Robust Bilingual Word Alignment
May 23, 2022
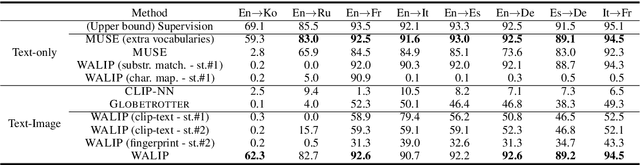


Word translation without parallel corpora has become feasible, rivaling the performance of supervised methods. Recent findings have shown that the accuracy and robustness of unsupervised word translation (UWT) can be improved by making use of visual observations, which are universal representations across languages. In this work, we investigate the potential of using not only visual observations but also pretrained language-image models for enabling a more efficient and robust UWT. Specifically, we develop a novel UWT method dubbed Word Alignment using Language-Image Pretraining (WALIP), which leverages visual observations via the shared embedding space of images and texts provided by CLIP models (Radford et al., 2021). WALIP has a two-step procedure. First, we retrieve word pairs with high confidences of similarity, computed using our proposed image-based fingerprints, which define the initial pivot for the word alignment. Second, we apply our robust Procrustes algorithm to estimate the linear mapping between two embedding spaces, which iteratively corrects and refines the estimated alignment. Our extensive experiments show that WALIP improves upon the state-of-the-art performance of bilingual word alignment for a few language pairs across different word embeddings and displays great robustness to the dissimilarity of language pairs or training corpora for two word embeddings.
Out-of-distribution Detection with Deep Nearest Neighbors
Apr 13, 2022



Out-of-distribution (OOD) detection is a critical task for deploying machine learning models in the open world. Distance-based methods have demonstrated promise, where testing samples are detected as OOD if they are relatively far away from in-distribution (ID) data. However, prior methods impose a strong distributional assumption of the underlying feature space, which may not always hold. In this paper, we explore the efficacy of non-parametric nearest-neighbor distance for OOD detection, which has been largely overlooked in the literature. Unlike prior works, our method does not impose any distributional assumption, hence providing stronger flexibility and generality. We demonstrate the effectiveness of nearest-neighbor-based OOD detection on several benchmarks and establish superior performance. Under the same model trained on ImageNet-1k, our method substantially reduces the false positive rate (FPR@TPR95) by 24.77% compared to a strong baseline SSD+, which uses a parametric approach Mahalanobis distance in detection.
Are Vision Transformers Robust to Spurious Correlations?
Mar 17, 2022



Deep neural networks may be susceptible to learning spurious correlations that hold on average but not in atypical test samples. As with the recent emergence of vision transformer (ViT) models, it remains underexplored how spurious correlations are manifested in such architectures. In this paper, we systematically investigate the robustness of vision transformers to spurious correlations on three challenging benchmark datasets and compare their performance with popular CNNs. Our study reveals that when pre-trained on a sufficiently large dataset, ViT models are more robust to spurious correlations than CNNs. Key to their success is the ability to generalize better from the examples where spurious correlations do not hold. Further, we perform extensive ablations and experiments to understand the role of the self-attention mechanism in providing robustness under spuriously correlated environments. We hope that our work will inspire future research on further understanding the robustness of ViT models.