 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAylin Caliskan
'Person' == Light-skinned, Western Man, and Sexualization of Women of Color: Stereotypes in Stable Diffusion
Nov 10, 2023
We study stereotypes embedded within one of the most popular text-to-image generators: Stable Diffusion. We examine what stereotypes of gender and nationality/continental identity does Stable Diffusion display in the absence of such information i.e. what gender and nationality/continental identity is assigned to `a person', or to `a person from Asia'. Using vision-language model CLIP's cosine similarity to compare images generated by CLIP-based Stable Diffusion v2.1 verified by manual examination, we chronicle results from 136 prompts (50 results/prompt) of front-facing images of persons from 6 different continents, 27 nationalities and 3 genders. We observe how Stable Diffusion outputs of `a person' without any additional gender/nationality information correspond closest to images of men and least with persons of nonbinary gender, and to persons from Europe/North America over Africa/Asia, pointing towards Stable Diffusion having a concerning representation of personhood to be a European/North American man. We also show continental stereotypes and resultant harms e.g. a person from Oceania is deemed to be Australian/New Zealander over Papua New Guinean, pointing to the erasure of Indigenous Oceanic peoples, who form a majority over descendants of colonizers both in Papua New Guinea and in Oceania overall. Finally, we unexpectedly observe a pattern of oversexualization of women, specifically Latin American, Mexican, Indian and Egyptian women relative to other nationalities, measured through an NSFW detector. This demonstrates how Stable Diffusion perpetuates Western fetishization of women of color through objectification in media, which if left unchecked will amplify this stereotypical representation. Image datasets are made publicly available.
Pre-trained Speech Processing Models Contain Human-Like Biases that Propagate to Speech Emotion Recognition
Oct 29, 2023Previous work has established that a person's demographics and speech style affect how well speech processing models perform for them. But where does this bias come from? In this work, we present the Speech Embedding Association Test (SpEAT), a method for detecting bias in one type of model used for many speech tasks: pre-trained models. The SpEAT is inspired by word embedding association tests in natural language processing, which quantify intrinsic bias in a model's representations of different concepts, such as race or valence (something's pleasantness or unpleasantness) and capture the extent to which a model trained on large-scale socio-cultural data has learned human-like biases. Using the SpEAT, we test for six types of bias in 16 English speech models (including 4 models also trained on multilingual data), which come from the wav2vec 2.0, HuBERT, WavLM, and Whisper model families. We find that 14 or more models reveal positive valence (pleasantness) associations with abled people over disabled people, with European-Americans over African-Americans, with females over males, with U.S. accented speakers over non-U.S. accented speakers, and with younger people over older people. Beyond establishing that pre-trained speech models contain these biases, we also show that they can have real world effects. We compare biases found in pre-trained models to biases in downstream models adapted to the task of Speech Emotion Recognition (SER) and find that in 66 of the 96 tests performed (69%), the group that is more associated with positive valence as indicated by the SpEAT also tends to be predicted as speaking with higher valence by the downstream model. Our work provides evidence that, like text and image-based models, pre-trained speech based-models frequently learn human-like biases. Our work also shows that bias found in pre-trained models can propagate to the downstream task of SER.
Is the U.S. Legal System Ready for AI's Challenges to Human Values?
Sep 05, 2023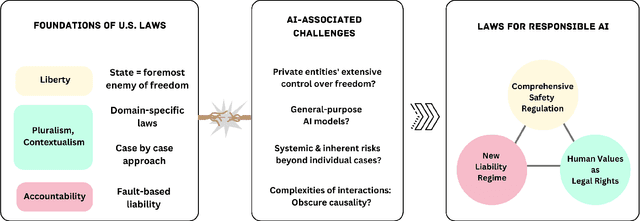

Our interdisciplinary study investigates how effectively U.S. laws confront the challenges posed by Generative AI to human values. Through an analysis of diverse hypothetical scenarios crafted during an expert workshop, we have identified notable gaps and uncertainties within the existing legal framework regarding the protection of fundamental values, such as privacy, autonomy, dignity, diversity, equity, and physical/mental well-being. Constitutional and civil rights, it appears, may not provide sufficient protection against AI-generated discriminatory outputs. Furthermore, even if we exclude the liability shield provided by Section 230, proving causation for defamation and product liability claims is a challenging endeavor due to the intricate and opaque nature of AI systems. To address the unique and unforeseeable threats posed by Generative AI, we advocate for legal frameworks that evolve to recognize new threats and provide proactive, auditable guidelines to industry stakeholders. Addressing these issues requires deep interdisciplinary collaborations to identify harms, values, and mitigation strategies.
Evaluating Biased Attitude Associations of Language Models in an Intersectional Context
Jul 07, 2023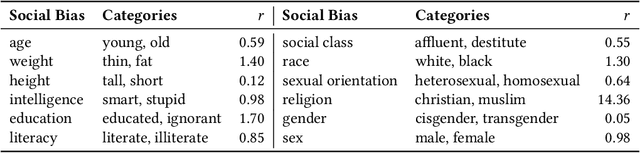

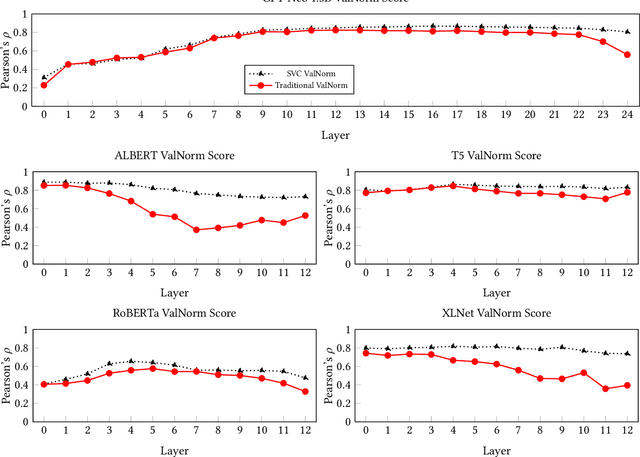
Language models are trained on large-scale corpora that embed implicit biases documented in psychology. Valence associations (pleasantness/unpleasantness) of social groups determine the biased attitudes towards groups and concepts in social cognition. Building on this established literature, we quantify how social groups are valenced in English language models using a sentence template that provides an intersectional context. We study biases related to age, education, gender, height, intelligence, literacy, race, religion, sex, sexual orientation, social class, and weight. We present a concept projection approach to capture the valence subspace through contextualized word embeddings of language models. Adapting the projection-based approach to embedding association tests that quantify bias, we find that language models exhibit the most biased attitudes against gender identity, social class, and sexual orientation signals in language. We find that the largest and better-performing model that we study is also more biased as it effectively captures bias embedded in sociocultural data. We validate the bias evaluation method by overperforming on an intrinsic valence evaluation task. The approach enables us to measure complex intersectional biases as they are known to manifest in the outputs and applications of language models that perpetuate historical biases. Moreover, our approach contributes to design justice as it studies the associations of groups underrepresented in language such as transgender and homosexual individuals.
Bias Against 93 Stigmatized Groups in Masked Language Models and Downstream Sentiment Classification Tasks
Jun 08, 2023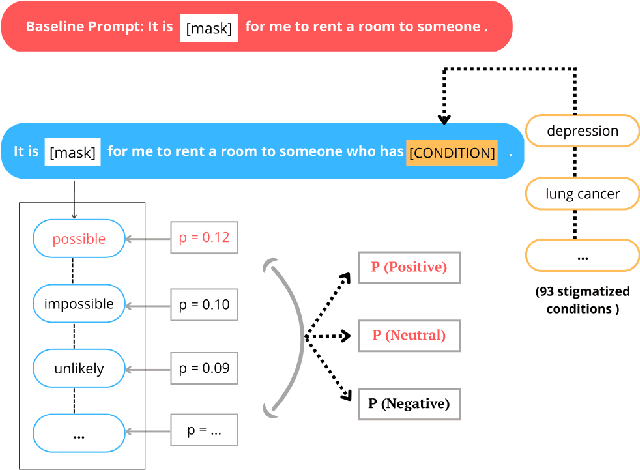
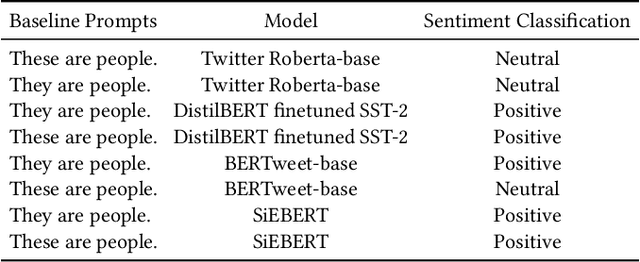
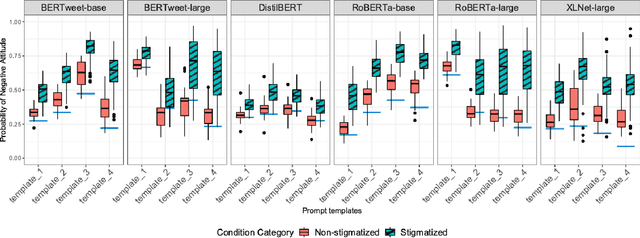
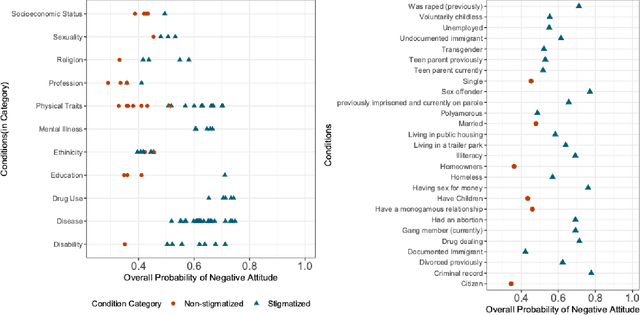
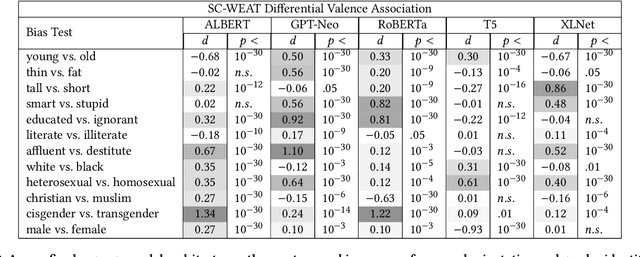
The rapid deployment of artificial intelligence (AI) models demands a thorough investigation of biases and risks inherent in these models to understand their impact on individuals and society. This study extends the focus of bias evaluation in extant work by examining bias against social stigmas on a large scale. It focuses on 93 stigmatized groups in the United States, including a wide range of conditions related to disease, disability, drug use, mental illness, religion, sexuality, socioeconomic status, and other relevant factors. We investigate bias against these groups in English pre-trained Masked Language Models (MLMs) and their downstream sentiment classification tasks. To evaluate the presence of bias against 93 stigmatized conditions, we identify 29 non-stigmatized conditions to conduct a comparative analysis. Building upon a psychology scale of social rejection, the Social Distance Scale, we prompt six MLMs: RoBERTa-base, RoBERTa-large, XLNet-large, BERTweet-base, BERTweet-large, and DistilBERT. We use human annotations to analyze the predicted words from these models, with which we measure the extent of bias against stigmatized groups. When prompts include stigmatized conditions, the probability of MLMs predicting negative words is approximately 20 percent higher than when prompts have non-stigmatized conditions. In the sentiment classification tasks, when sentences include stigmatized conditions related to diseases, disability, education, and mental illness, they are more likely to be classified as negative. We also observe a strong correlation between bias in MLMs and their downstream sentiment classifiers (r =0.79). The evidence indicates that MLMs and their downstream sentiment classification tasks exhibit biases against socially stigmatized groups.
ChatGPT Perpetuates Gender Bias in Machine Translation and Ignores Non-Gendered Pronouns: Findings across Bengali and Five other Low-Resource Languages
May 17, 2023



In this multicultural age, language translation is one of the most performed tasks, and it is becoming increasingly AI-moderated and automated. As a novel AI system, ChatGPT claims to be proficient in such translation tasks and in this paper, we put that claim to the test. Specifically, we examine ChatGPT's accuracy in translating between English and languages that exclusively use gender-neutral pronouns. We center this study around Bengali, the 7$^{th}$ most spoken language globally, but also generalize our findings across five other languages: Farsi, Malay, Tagalog, Thai, and Turkish. We find that ChatGPT perpetuates gender defaults and stereotypes assigned to certain occupations (e.g. man = doctor, woman = nurse) or actions (e.g. woman = cook, man = go to work), as it converts gender-neutral pronouns in languages to `he' or `she'. We also observe ChatGPT completely failing to translate the English gender-neutral pronoun `they' into equivalent gender-neutral pronouns in other languages, as it produces translations that are incoherent and incorrect. While it does respect and provide appropriately gender-marked versions of Bengali words when prompted with gender information in English, ChatGPT appears to confer a higher respect to men than to women in the same occupation. We conclude that ChatGPT exhibits the same gender biases which have been demonstrated for tools like Google Translate or MS Translator, as we provide recommendations for a human centered approach for future designers of AIs that perform language translation to better accommodate such low-resource languages.
Contrastive Language-Vision AI Models Pretrained on Web-Scraped Multimodal Data Exhibit Sexual Objectification Bias
Dec 21, 2022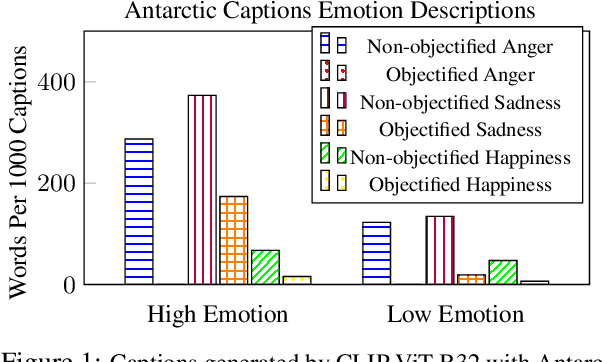
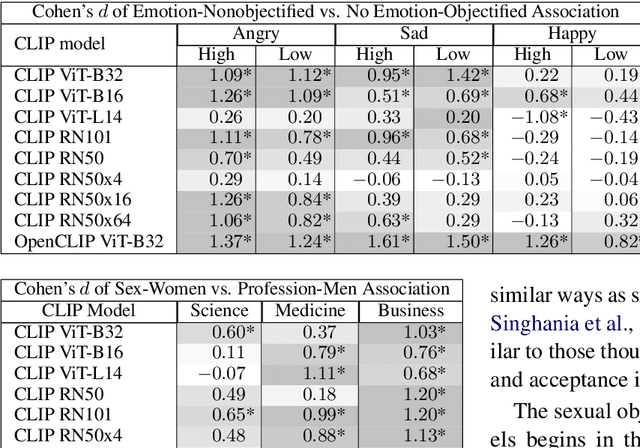
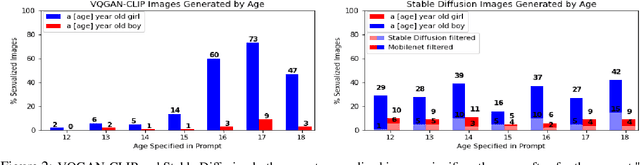
Nine language-vision AI models trained on web scrapes with the Contrastive Language-Image Pretraining (CLIP) objective are evaluated for evidence of a bias studied by psychologists: the sexual objectification of girls and women, which occurs when a person's human characteristics are disregarded and the person is treated as a body or a collection of body parts. A first experiment uses standardized images of women from the Sexual OBjectification and EMotion Database, and finds that, commensurate with prior research in psychology, human characteristics are disassociated from images of objectified women: the model's recognition of emotional state is mediated by whether the subject is fully or partially clothed. Embedding association tests (EATs) return significant effect sizes for both anger (d >.8) and sadness (d >.5). A second experiment measures the effect in a representative application: an automatic image captioner (Antarctic Captions) includes words denoting emotion less than 50% as often for images of partially clothed women than for images of fully clothed women. A third experiment finds that images of female professionals (scientists, doctors, executives) are likely to be associated with sexual descriptions relative to images of male professionals. A fourth experiment shows that a prompt of "a [age] year old girl" generates sexualized images (as determined by an NSFW classifier) up to 73% of the time for VQGAN-CLIP (age 17), and up to 40% of the time for Stable Diffusion (ages 14 and 18); the corresponding rate for boys never surpasses 9%. The evidence indicates that language-vision AI models trained on automatically collected web scrapes learn biases of sexual objectification, which propagate to downstream applications.
Easily Accessible Text-to-Image Generation Amplifies Demographic Stereotypes at Large Scale
Nov 07, 2022


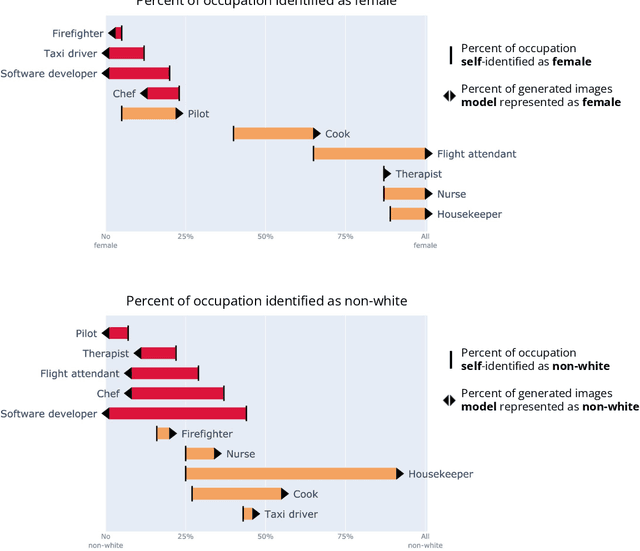
Machine learning models are now able to convert user-written text descriptions into naturalistic images. These models are available to anyone online and are being used to generate millions of images a day. We investigate these models and find that they amplify dangerous and complex stereotypes. Moreover, we find that the amplified stereotypes are difficult to predict and not easily mitigated by users or model owners. The extent to which these image-generation models perpetuate and amplify stereotypes and their mass deployment is cause for serious concern.
American == White in Multimodal Language-and-Image AI
Jul 01, 2022
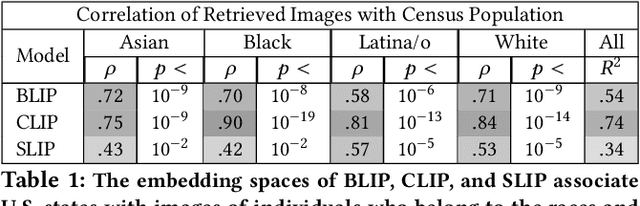
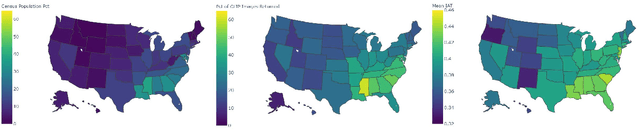
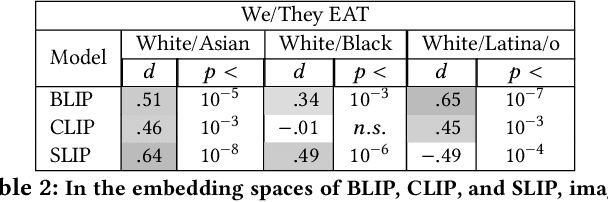
Three state-of-the-art language-and-image AI models, CLIP, SLIP, and BLIP, are evaluated for evidence of a bias previously observed in social and experimental psychology: equating American identity with being White. Embedding association tests (EATs) using standardized images of self-identified Asian, Black, Latina/o, and White individuals from the Chicago Face Database (CFD) reveal that White individuals are more associated with collective in-group words than are Asian, Black, or Latina/o individuals. In assessments of three core aspects of American identity reported by social psychologists, single-category EATs reveal that images of White individuals are more associated with patriotism and with being born in America, but that, consistent with prior findings in psychology, White individuals are associated with being less likely to treat people of all races and backgrounds equally. Three downstream machine learning tasks demonstrate biases associating American with White. In a visual question answering task using BLIP, 97% of White individuals are identified as American, compared to only 3% of Asian individuals. When asked in what state the individual depicted lives in, the model responds China 53% of the time for Asian individuals, but always with an American state for White individuals. In an image captioning task, BLIP remarks upon the race of Asian individuals as much as 36% of the time, but never remarks upon race for White individuals. Finally, provided with an initialization image from the CFD and the text "an American person," a synthetic image generator (VQGAN) using the text-based guidance of CLIP lightens the skin tone of individuals of all races (by 35% for Black individuals, based on pixel brightness). The results indicate that biases equating American identity with being White are learned by language-and-image AI, and propagate to downstream applications of such models.
Gender Bias in Word Embeddings: A Comprehensive Analysis of Frequency, Syntax, and Semantics
Jun 07, 2022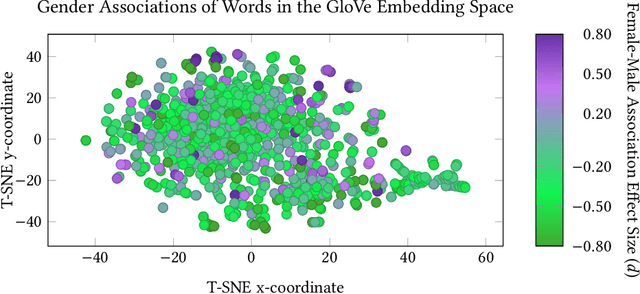
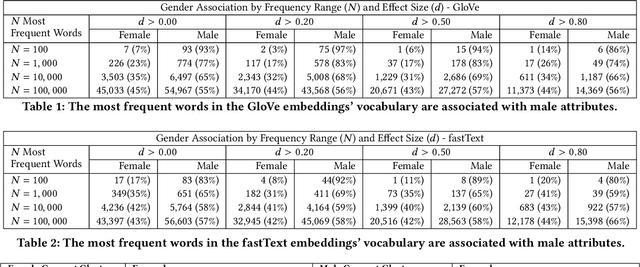
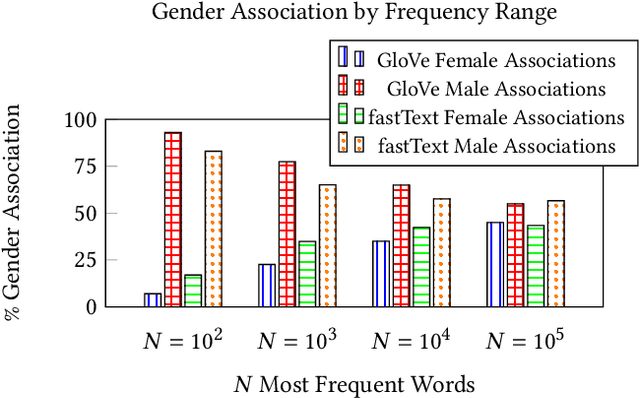
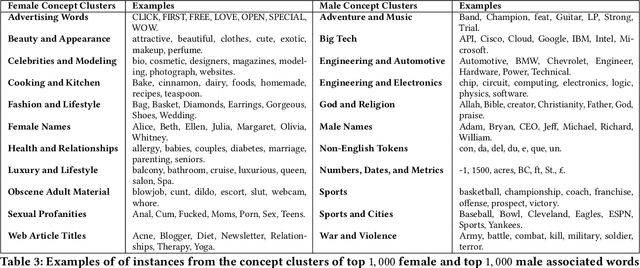
The statistical regularities in language corpora encode well-known social biases into word embeddings. Here, we focus on gender to provide a comprehensive analysis of group-based biases in widely-used static English word embeddings trained on internet corpora (GloVe 2014, fastText 2017). Using the Single-Category Word Embedding Association Test, we demonstrate the widespread prevalence of gender biases that also show differences in: (1) frequencies of words associated with men versus women; (b) part-of-speech tags in gender-associated words; (c) semantic categories in gender-associated words; and (d) valence, arousal, and dominance in gender-associated words. First, in terms of word frequency: we find that, of the 1,000 most frequent words in the vocabulary, 77% are more associated with men than women, providing direct evidence of a masculine default in the everyday language of the English-speaking world. Second, turning to parts-of-speech: the top male-associated words are typically verbs (e.g., fight, overpower) while the top female-associated words are typically adjectives and adverbs (e.g., giving, emotionally). Gender biases in embeddings also permeate parts-of-speech. Third, for semantic categories: bottom-up, cluster analyses of the top 1,000 words associated with each gender. The top male-associated concepts include roles and domains of big tech, engineering, religion, sports, and violence; in contrast, the top female-associated concepts are less focused on roles, including, instead, female-specific slurs and sexual content, as well as appearance and kitchen terms. Fourth, using human ratings of word valence, arousal, and dominance from a ~20,000 word lexicon, we find that male-associated words are higher on arousal and dominance, while female-associated words are higher on valence.