 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTadayoshi Kohno
Particip-AI: A Democratic Surveying Framework for Anticipating Future AI Use Cases, Harms and Benefits
Mar 21, 2024
General purpose AI, such as ChatGPT, seems to have lowered the barriers for the public to use AI and harness its power. However, the governance and development of AI still remain in the hands of a few, and the pace of development is accelerating without proper assessment of risks. As a first step towards democratic governance and risk assessment of AI, we introduce Particip-AI, a framework to gather current and future AI use cases and their harms and benefits from non-expert public. Our framework allows us to study more nuanced and detailed public opinions on AI through collecting use cases, surfacing diverse harms through risk assessment under alternate scenarios (i.e., developing and not developing a use case), and illuminating tensions over AI development through making a concluding choice on its development. To showcase the promise of our framework towards guiding democratic AI, we gather responses from 295 demographically diverse participants. We find that participants' responses emphasize applications for personal life and society, contrasting with most current AI development's business focus. This shows the value of surfacing diverse harms that are complementary to expert assessments. Furthermore, we found that perceived impact of not developing use cases predicted participants' judgements of whether AI use cases should be developed, and highlighted lay users' concerns of techno-solutionism. We conclude with a discussion on how frameworks like Particip-AI can further guide democratic AI governance and regulation.
SecGPT: An Execution Isolation Architecture for LLM-Based Systems
Mar 08, 2024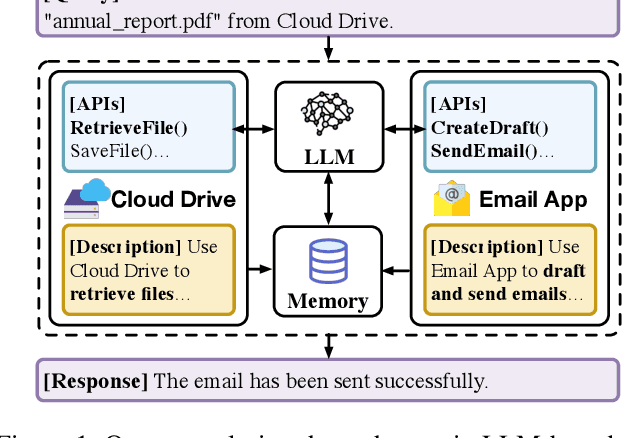
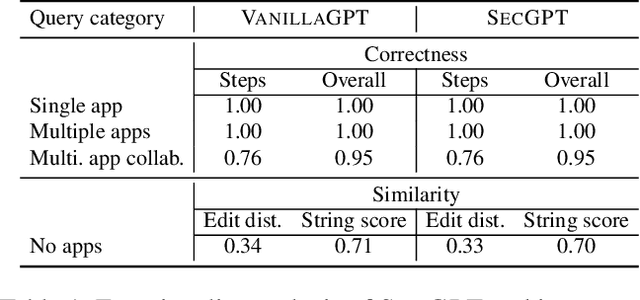
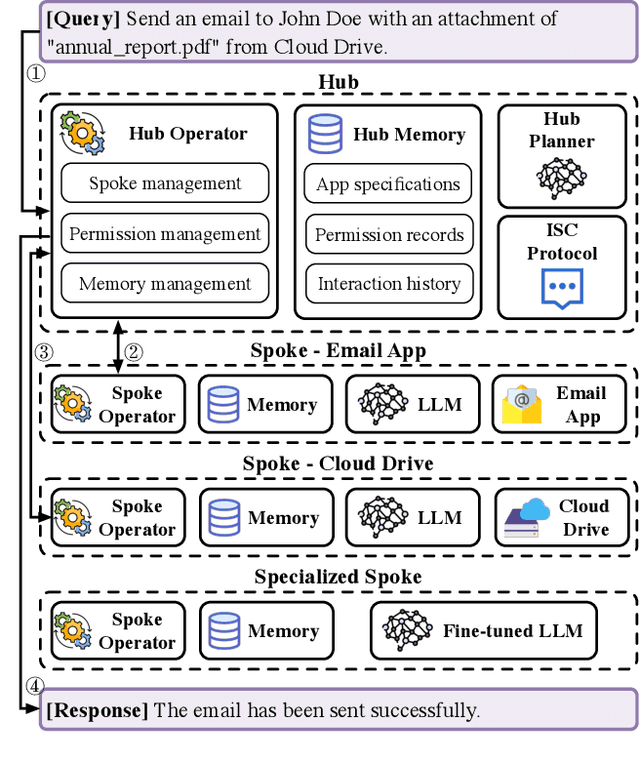
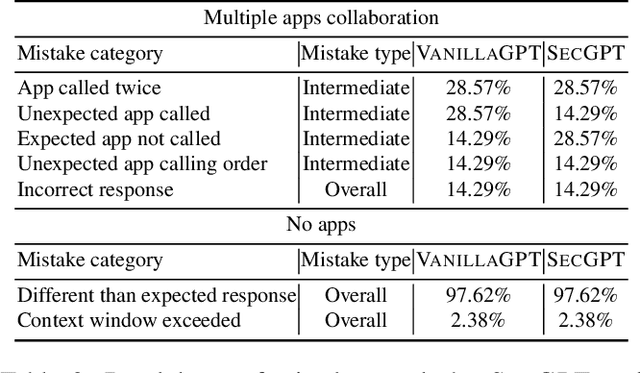
Large language models (LLMs) extended as systems, such as ChatGPT, have begun supporting third-party applications. These LLM apps leverage the de facto natural language-based automated execution paradigm of LLMs: that is, apps and their interactions are defined in natural language, provided access to user data, and allowed to freely interact with each other and the system. These LLM app ecosystems resemble the settings of earlier computing platforms, where there was insufficient isolation between apps and the system. Because third-party apps may not be trustworthy, and exacerbated by the imprecision of the natural language interfaces, the current designs pose security and privacy risks for users. In this paper, we propose SecGPT, an architecture for LLM-based systems that aims to mitigate the security and privacy issues that arise with the execution of third-party apps. SecGPT's key idea is to isolate the execution of apps and more precisely mediate their interactions outside of their isolated environments. We evaluate SecGPT against a number of case study attacks and demonstrate that it protects against many security, privacy, and safety issues that exist in non-isolated LLM-based systems. The performance overhead incurred by SecGPT to improve security is under 0.3x for three-quarters of the tested queries. To foster follow-up research, we release SecGPT's source code at https://github.com/llm-platform-security/SecGPT.
LLM Platform Security: Applying a Systematic Evaluation Framework to OpenAI's ChatGPT Plugins
Sep 19, 2023Large language model (LLM) platforms, such as ChatGPT, have recently begun offering a plugin ecosystem to interface with third-party services on the internet. While these plugins extend the capabilities of LLM platforms, they are developed by arbitrary third parties and thus cannot be implicitly trusted. Plugins also interface with LLM platforms and users using natural language, which can have imprecise interpretations. In this paper, we propose a framework that lays a foundation for LLM platform designers to analyze and improve the security, privacy, and safety of current and future plugin-integrated LLM platforms. Our framework is a formulation of an attack taxonomy that is developed by iteratively exploring how LLM platform stakeholders could leverage their capabilities and responsibilities to mount attacks against each other. As part of our iterative process, we apply our framework in the context of OpenAI's plugin ecosystem. We uncover plugins that concretely demonstrate the potential for the types of issues that we outline in our attack taxonomy. We conclude by discussing novel challenges and by providing recommendations to improve the security, privacy, and safety of present and future LLM-based computing platforms.
Is the U.S. Legal System Ready for AI's Challenges to Human Values?
Sep 05, 2023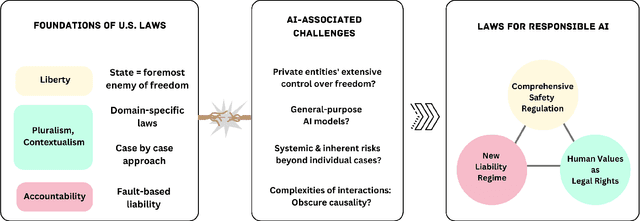

Our interdisciplinary study investigates how effectively U.S. laws confront the challenges posed by Generative AI to human values. Through an analysis of diverse hypothetical scenarios crafted during an expert workshop, we have identified notable gaps and uncertainties within the existing legal framework regarding the protection of fundamental values, such as privacy, autonomy, dignity, diversity, equity, and physical/mental well-being. Constitutional and civil rights, it appears, may not provide sufficient protection against AI-generated discriminatory outputs. Furthermore, even if we exclude the liability shield provided by Section 230, proving causation for defamation and product liability claims is a challenging endeavor due to the intricate and opaque nature of AI systems. To address the unique and unforeseeable threats posed by Generative AI, we advocate for legal frameworks that evolve to recognize new threats and provide proactive, auditable guidelines to industry stakeholders. Addressing these issues requires deep interdisciplinary collaborations to identify harms, values, and mitigation strategies.
Re-purposing Perceptual Hashing based Client Side Scanning for Physical Surveillance
Dec 08, 2022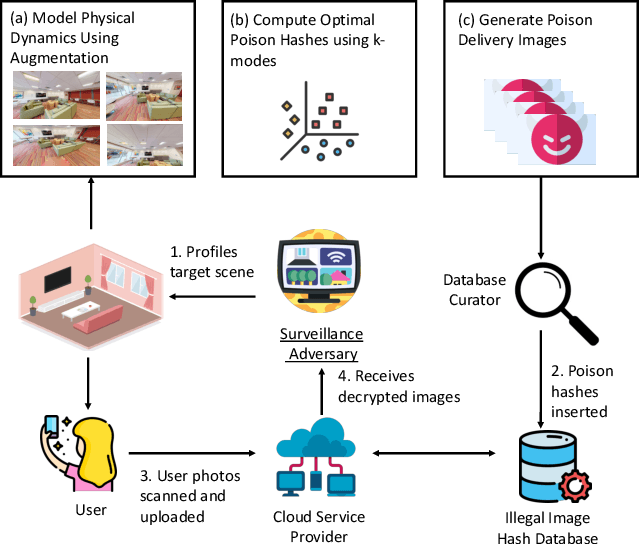
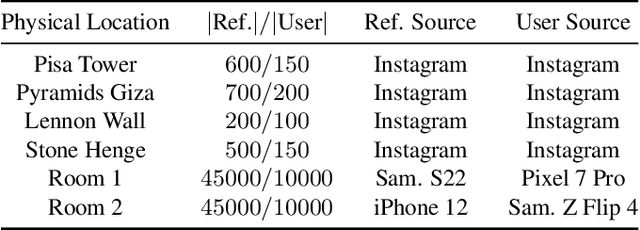


Content scanning systems employ perceptual hashing algorithms to scan user content for illegal material, such as child pornography or terrorist recruitment flyers. Perceptual hashing algorithms help determine whether two images are visually similar while preserving the privacy of the input images. Several efforts from industry and academia propose to conduct content scanning on client devices such as smartphones due to the impending roll out of end-to-end encryption that will make server-side content scanning difficult. However, these proposals have met with strong criticism because of the potential for the technology to be misused and re-purposed. Our work informs this conversation by experimentally characterizing the potential for one type of misuse -- attackers manipulating the content scanning system to perform physical surveillance on target locations. Our contributions are threefold: (1) we offer a definition of physical surveillance in the context of client-side image scanning systems; (2) we experimentally characterize this risk and create a surveillance algorithm that achieves physical surveillance rates of >40% by poisoning 5% of the perceptual hash database; (3) we experimentally study the trade-off between the robustness of client-side image scanning systems and surveillance, showing that more robust detection of illegal material leads to increased potential for physical surveillance.
Reliable and Trustworthy Machine Learning for Health Using Dataset Shift Detection
Oct 26, 2021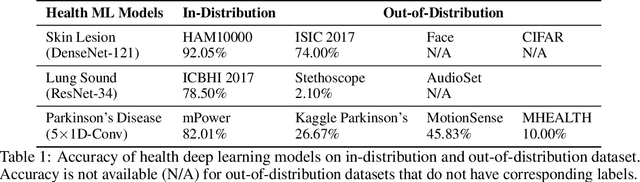
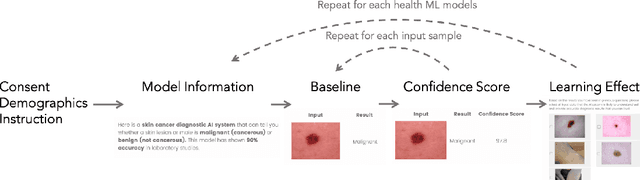
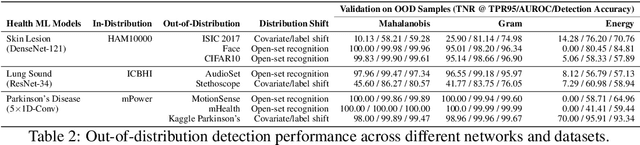

Unpredictable ML model behavior on unseen data, especially in the health domain, raises serious concerns about its safety as repercussions for mistakes can be fatal. In this paper, we explore the feasibility of using state-of-the-art out-of-distribution detectors for reliable and trustworthy diagnostic predictions. We select publicly available deep learning models relating to various health conditions (e.g., skin cancer, lung sound, and Parkinson's disease) using various input data types (e.g., image, audio, and motion data). We demonstrate that these models show unreasonable predictions on out-of-distribution datasets. We show that Mahalanobis distance- and Gram matrices-based out-of-distribution detection methods are able to detect out-of-distribution data with high accuracy for the health models that operate on different modalities. We then translate the out-of-distribution score into a human interpretable CONFIDENCE SCORE to investigate its effect on the users' interaction with health ML applications. Our user study shows that the \textsc{confidence score} helped the participants only trust the results with a high score to make a medical decision and disregard results with a low score. Through this work, we demonstrate that dataset shift is a critical piece of information for high-stake ML applications, such as medical diagnosis and healthcare, to provide reliable and trustworthy predictions to the users.
Disrupting Model Training with Adversarial Shortcuts
Jun 30, 2021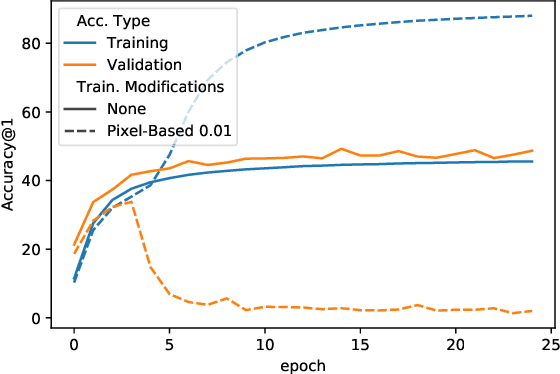

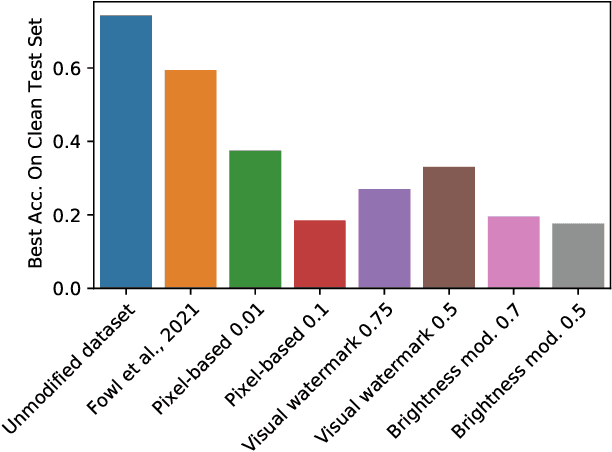
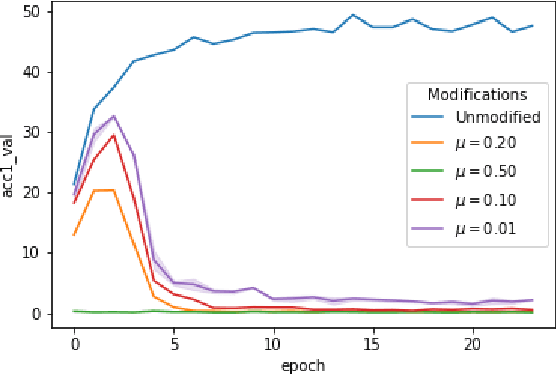
When data is publicly released for human consumption, it is unclear how to prevent its unauthorized usage for machine learning purposes. Successful model training may be preventable with carefully designed dataset modifications, and we present a proof-of-concept approach for the image classification setting. We propose methods based on the notion of adversarial shortcuts, which encourage models to rely on non-robust signals rather than semantic features, and our experiments demonstrate that these measures successfully prevent deep learning models from achieving high accuracy on real, unmodified data examples.