 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAyu Purwarianti
Cendol: Open Instruction-tuned Generative Large Language Models for Indonesian Languages
Apr 09, 2024
Large language models (LLMs) show remarkable human-like capability in various domains and languages. However, a notable quality gap arises in low-resource languages, e.g., Indonesian indigenous languages, rendering them ineffective and inefficient in such linguistic contexts. To bridge this quality gap, we introduce Cendol, a collection of Indonesian LLMs encompassing both decoder-only and encoder-decoder architectures across a range of model sizes. We highlight Cendol's effectiveness across a diverse array of tasks, attaining 20% improvement, and demonstrate its capability to generalize to unseen tasks and indigenous languages of Indonesia. Furthermore, Cendol models showcase improved human favorability despite their limitations in capturing indigenous knowledge and cultural values in Indonesia. In addition, we discuss the shortcomings of parameter-efficient tunings, such as LoRA, for language adaptation. Alternatively, we propose the usage of vocabulary adaptation to enhance efficiency. Lastly, we evaluate the safety of Cendol and showcase that safety in pre-training in one language such as English is transferable to low-resource languages, such as Indonesian, even without RLHF and safety fine-tuning.
What Linguistic Features and Languages are Important in LLM Translation?
Feb 21, 2024Large Language Models (LLMs) demonstrate strong capability across multiple tasks, including machine translation. Our study focuses on evaluating Llama2's machine translation capabilities and exploring how translation depends on languages in its training data. Our experiments show that the 7B Llama2 model yields above 10 BLEU score for all languages it has seen, but not always for languages it has not seen. Most gains for those unseen languages are observed the most with the model scale compared to using chat versions or adding shot count. Furthermore, our linguistic distance analysis reveals that syntactic similarity is not always the primary linguistic factor in determining translation quality. Interestingly, we discovered that under specific circumstances, some languages, despite having significantly less training data than English, exhibit strong correlations comparable to English. Our discoveries here give new perspectives for the current landscape of LLMs, raising the possibility that LLMs centered around languages other than English may offer a more effective foundation for a multilingual model.
LinguAlchemy: Fusing Typological and Geographical Elements for Unseen Language Generalization
Feb 01, 2024Pretrained language models (PLMs) have shown remarkable generalization toward multiple tasks and languages. Nonetheless, the generalization of PLMs towards unseen languages is poor, resulting in significantly worse language performance, or even generating nonsensical responses that are comparable to a random baseline. This limitation has been a longstanding problem of PLMs raising the problem of diversity and equal access to language modeling technology. In this work, we solve this limitation by introducing LinguAlchemy, a regularization technique that incorporates various aspects of languages covering typological, geographical, and phylogenetic constraining the resulting representation of PLMs to better characterize the corresponding linguistics constraints. LinguAlchemy significantly improves the accuracy performance of mBERT and XLM-R on unseen languages by ~18% and ~2%, respectively compared to fully finetuned models and displaying a high degree of unseen language generalization. We further introduce AlchemyScale and AlchemyTune, extension of LinguAlchemy which adjusts the linguistic regularization weights automatically, alleviating the need for hyperparameter search. LinguAlchemy enables better cross-lingual generalization to unseen languages which is vital for better inclusivity and accessibility of PLMs.
The Obscure Limitation of Modular Multilingual Language Models
Nov 21, 2023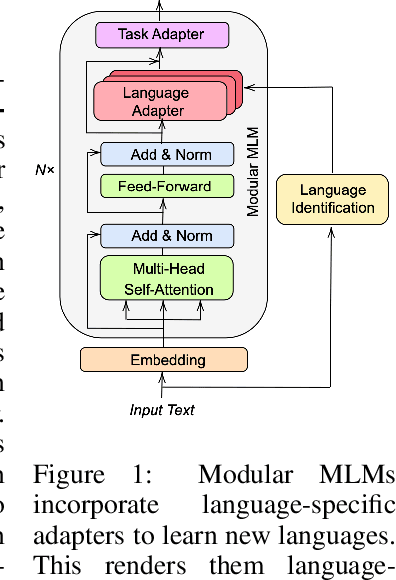
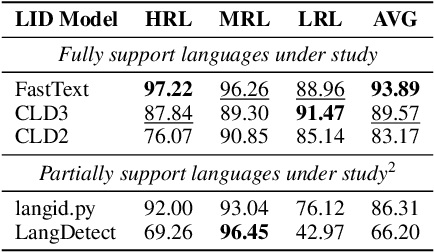
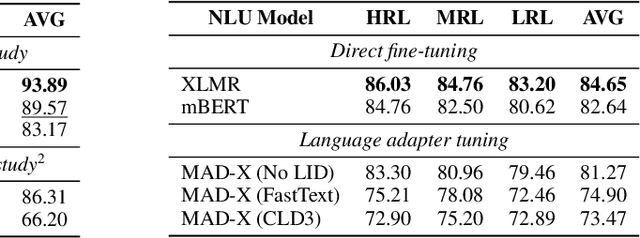

We expose the limitation of modular multilingual language models (MLMs) in multilingual inference scenarios with unknown languages. Existing evaluations of modular MLMs exclude the involvement of language identification (LID) modules, which obscures the performance of real-case multilingual scenarios of modular MLMs. In this work, we showcase the effect of adding LID on the multilingual evaluation of modular MLMs and provide discussions for closing the performance gap of caused by the pipelined approach of LID and modular MLMs.
IndoRobusta: Towards Robustness Against Diverse Code-Mixed Indonesian Local Languages
Nov 21, 2023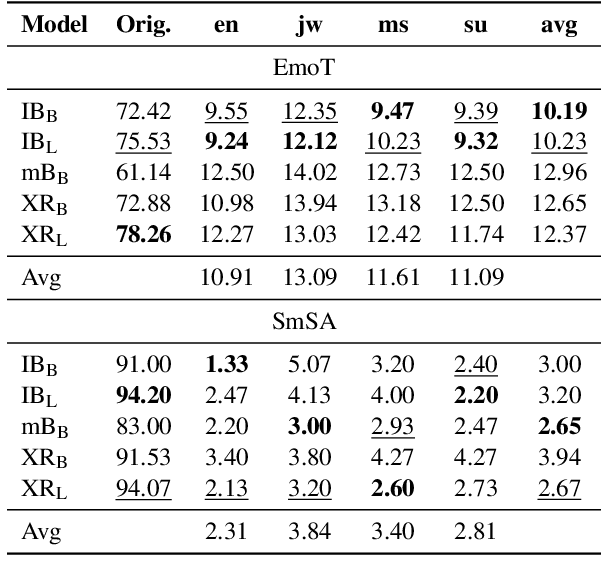

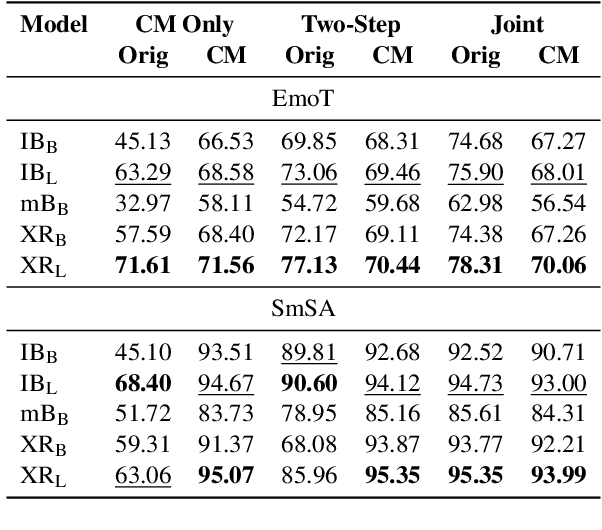
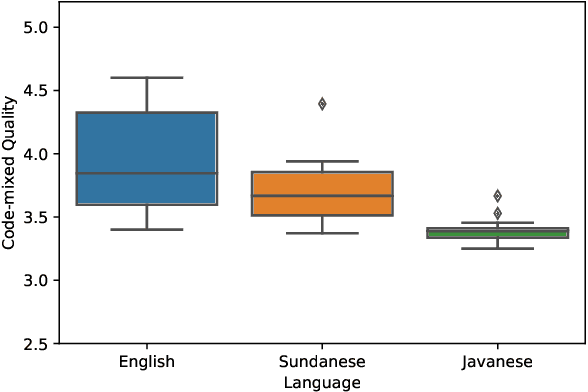
Significant progress has been made on Indonesian NLP. Nevertheless, exploration of the code-mixing phenomenon in Indonesian is limited, despite many languages being frequently mixed with Indonesian in daily conversation. In this work, we explore code-mixing in Indonesian with four embedded languages, i.e., English, Sundanese, Javanese, and Malay; and introduce IndoRobusta, a framework to evaluate and improve the code-mixing robustness. Our analysis shows that the pre-training corpus bias affects the model's ability to better handle Indonesian-English code-mixing when compared to other local languages, despite having higher language diversity.
Indo LEGO-ABSA: A Multitask Generative Aspect Based Sentiment Analysis for Indonesian Language
Nov 03, 2023
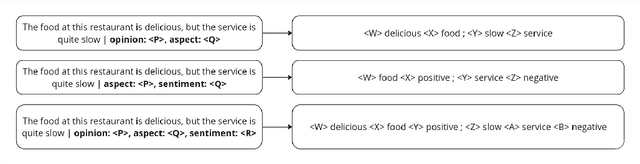


Aspect-based sentiment analysis is a method in natural language processing aimed at identifying and understanding sentiments related to specific aspects of an entity. Aspects are words or phrases that represent an aspect or attribute of a particular entity. Previous research has utilized generative pre-trained language models to perform aspect-based sentiment analysis. LEGO-ABSA is one framework that has successfully employed generative pre-trained language models in aspect-based sentiment analysis, particularly in English. LEGO-ABSA uses a multitask learning and prompting approach to enhance model performance. However, the application of this approach has not been done in the context of Bahasa Indonesia. Therefore, this research aims to implement the multitask learning and prompting approach in aspect-based sentiment analysis for Bahasa Indonesia using generative pre-trained language models. In this study, the Indo LEGO-ABSA model is developed, which is an aspect-based sentiment analysis model utilizing generative pre-trained language models and trained with multitask learning and prompting. Indo LEGO-ABSA is trained with a hotel domain dataset in the Indonesian language. The obtained results include an f1-score of 79.55% for the Aspect Sentiment Triplet Extraction task, 86.09% for Unified Aspect-based Sentiment Analysis, 79.85% for Aspect Opinion Pair Extraction, 87.45% for Aspect Term Extraction, and 88.09% for Opinion Term Extraction. Indo LEGO-ABSA adopts the LEGO-ABSA framework that employs the T5 model, specifically mT5, by applying multitask learning to train all tasks within aspect-based sentiment analysis.
IndoToD: A Multi-Domain Indonesian Benchmark For End-to-End Task-Oriented Dialogue Systems
Nov 02, 2023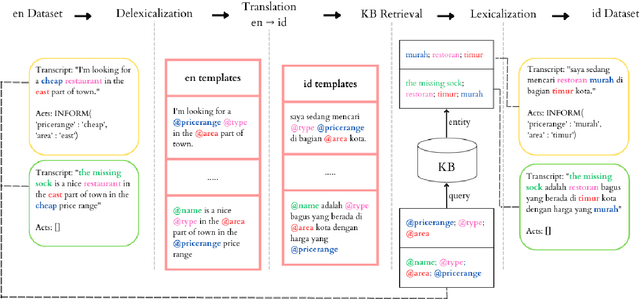
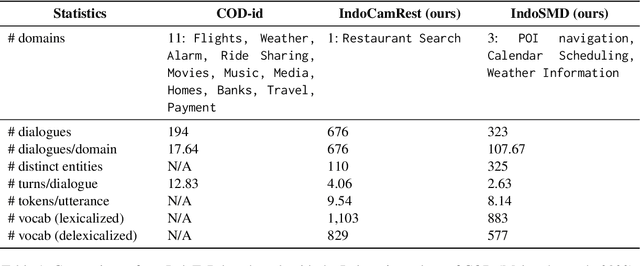
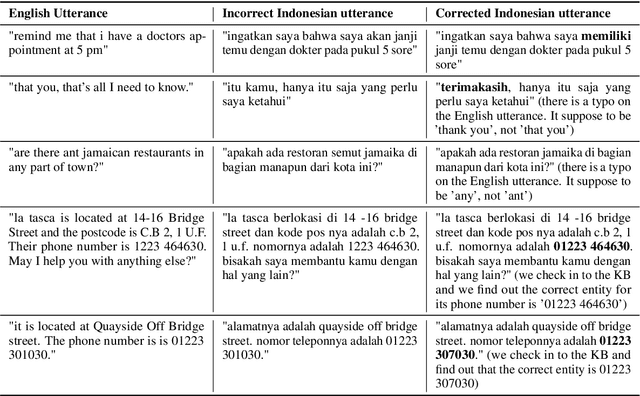
Task-oriented dialogue (ToD) systems have been mostly created for high-resource languages, such as English and Chinese. However, there is a need to develop ToD systems for other regional or local languages to broaden their ability to comprehend the dialogue contexts in various languages. This paper introduces IndoToD, an end-to-end multi domain ToD benchmark in Indonesian. We extend two English ToD datasets to Indonesian, comprising four different domains by delexicalization to efficiently reduce the size of annotations. To ensure a high-quality data collection, we hire native speakers to manually translate the dialogues. Along with the original English datasets, these new Indonesian datasets serve as an effective benchmark for evaluating Indonesian and English ToD systems as well as exploring the potential benefits of cross-lingual and bilingual transfer learning approaches.
Replicable Benchmarking of Neural Machine Translation (NMT) on Low-Resource Local Languages in Indonesia
Nov 02, 2023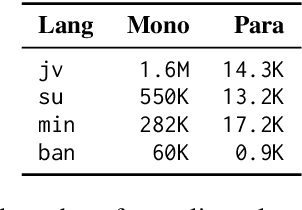

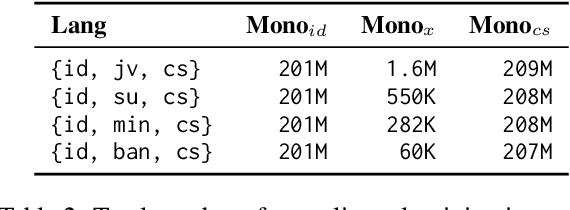
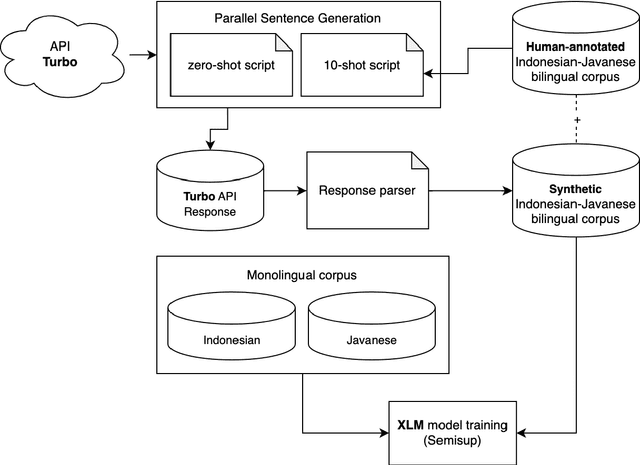
Neural machine translation (NMT) for low-resource local languages in Indonesia faces significant challenges, including the need for a representative benchmark and limited data availability. This work addresses these challenges by comprehensively analyzing training NMT systems for four low-resource local languages in Indonesia: Javanese, Sundanese, Minangkabau, and Balinese. Our study encompasses various training approaches, paradigms, data sizes, and a preliminary study into using large language models for synthetic low-resource languages parallel data generation. We reveal specific trends and insights into practical strategies for low-resource language translation. Our research demonstrates that despite limited computational resources and textual data, several of our NMT systems achieve competitive performances, rivaling the translation quality of zero-shot gpt-3.5-turbo. These findings significantly advance NMT for low-resource languages, offering valuable guidance for researchers in similar contexts.
Domain-Specific Language Model Post-Training for Indonesian Financial NLP
Oct 15, 2023
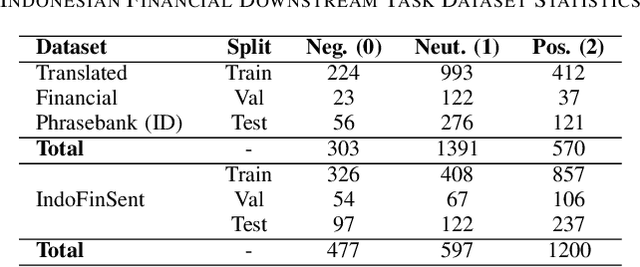

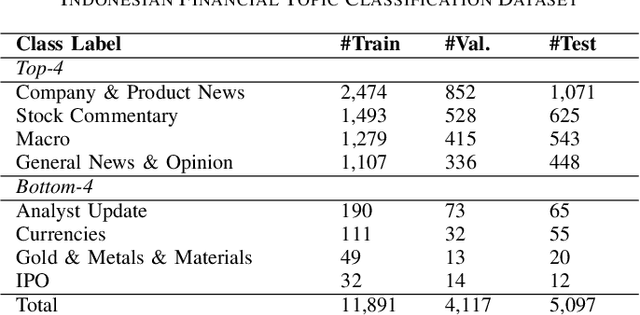
BERT and IndoBERT have achieved impressive performance in several NLP tasks. There has been several investigation on its adaption in specialized domains especially for English language. We focus on financial domain and Indonesian language, where we perform post-training on pre-trained IndoBERT for financial domain using a small scale of Indonesian financial corpus. In this paper, we construct an Indonesian self-supervised financial corpus, Indonesian financial sentiment analysis dataset, Indonesian financial topic classification dataset, and release a family of BERT models for financial NLP. We also evaluate the effectiveness of domain-specific post-training on sentiment analysis and topic classification tasks. Our findings indicate that the post-training increases the effectiveness of a language model when it is fine-tuned to domain-specific downstream tasks.
Low-Resource Clickbait Spoiling for Indonesian via Question Answering
Oct 12, 2023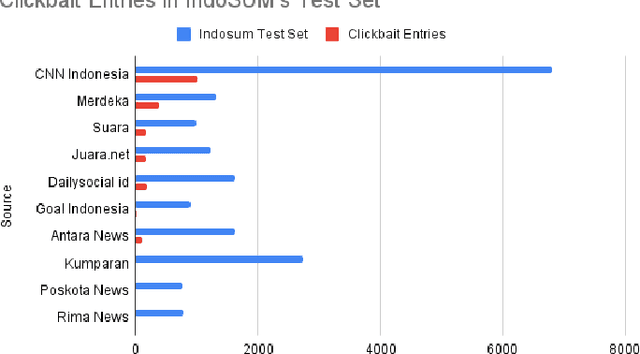
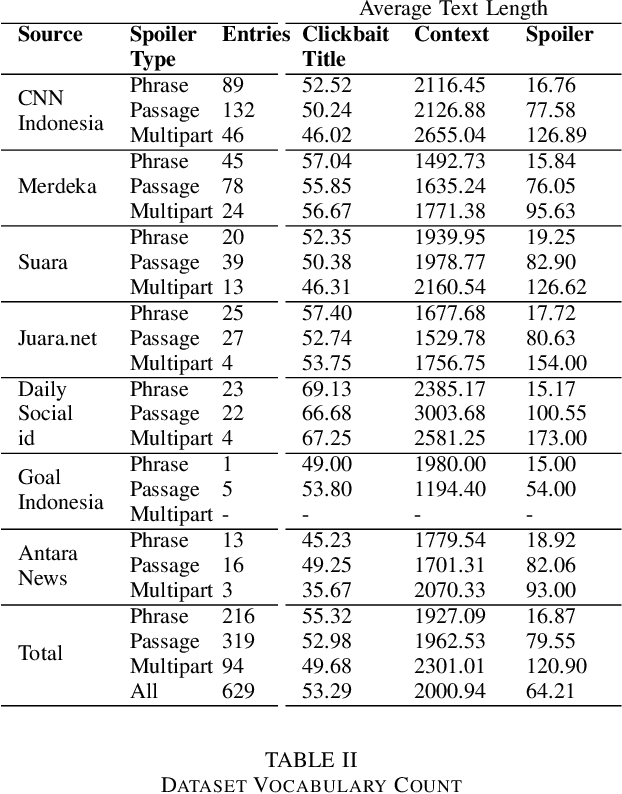
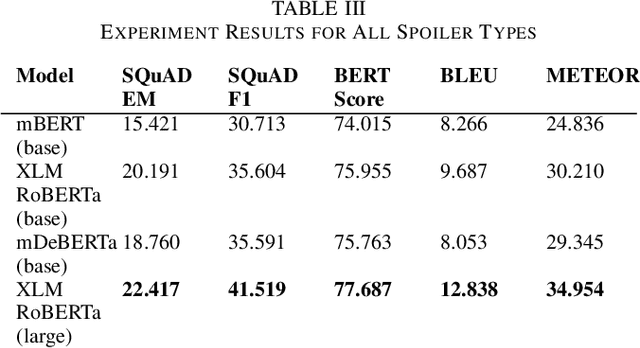

Clickbait spoiling aims to generate a short text to satisfy the curiosity induced by a clickbait post. As it is a newly introduced task, the dataset is only available in English so far. Our contributions include the construction of manually labeled clickbait spoiling corpus in Indonesian and an evaluation on using cross-lingual zero-shot question answering-based models to tackle clikcbait spoiling for low-resource language like Indonesian. We utilize selection of multilingual language models. The experimental results suggest that XLM-RoBERTa (large) model outperforms other models for phrase and passage spoilers, meanwhile, mDeBERTa (base) model outperforms other models for multipart spoilers.