 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoly Lovenia
Cendol: Open Instruction-tuned Generative Large Language Models for Indonesian Languages
Apr 09, 2024
Large language models (LLMs) show remarkable human-like capability in various domains and languages. However, a notable quality gap arises in low-resource languages, e.g., Indonesian indigenous languages, rendering them ineffective and inefficient in such linguistic contexts. To bridge this quality gap, we introduce Cendol, a collection of Indonesian LLMs encompassing both decoder-only and encoder-decoder architectures across a range of model sizes. We highlight Cendol's effectiveness across a diverse array of tasks, attaining 20% improvement, and demonstrate its capability to generalize to unseen tasks and indigenous languages of Indonesia. Furthermore, Cendol models showcase improved human favorability despite their limitations in capturing indigenous knowledge and cultural values in Indonesia. In addition, we discuss the shortcomings of parameter-efficient tunings, such as LoRA, for language adaptation. Alternatively, we propose the usage of vocabulary adaptation to enhance efficiency. Lastly, we evaluate the safety of Cendol and showcase that safety in pre-training in one language such as English is transferable to low-resource languages, such as Indonesian, even without RLHF and safety fine-tuning.
LLMs Are Few-Shot In-Context Low-Resource Language Learners
Mar 27, 2024In-context learning (ICL) empowers large language models (LLMs) to perform diverse tasks in underrepresented languages using only short in-context information, offering a crucial avenue for narrowing the gap between high-resource and low-resource languages. Nonetheless, there is only a handful of works explored ICL for low-resource languages with most of them focusing on relatively high-resource languages, such as French and Spanish. In this work, we extensively study ICL and its cross-lingual variation (X-ICL) on 25 low-resource and 7 relatively higher-resource languages. Our study not only assesses the effectiveness of ICL with LLMs in low-resource languages but also identifies the shortcomings of in-context label alignment, and introduces a more effective alternative: query alignment. Moreover, we provide valuable insights into various facets of ICL for low-resource languages. Our study concludes the significance of few-shot in-context information on enhancing the low-resource understanding quality of LLMs through semantically relevant information by closing the language gap in the target language and aligning the semantics between the targeted low-resource and the high-resource language that the model is proficient in. Our work highlights the importance of advancing ICL research, particularly for low-resource languages.
Contrastive Learning for Inference in Dialogue
Oct 19, 2023Inference, especially those derived from inductive processes, is a crucial component in our conversation to complement the information implicitly or explicitly conveyed by a speaker. While recent large language models show remarkable advances in inference tasks, their performance in inductive reasoning, where not all information is present in the context, is far behind deductive reasoning. In this paper, we analyze the behavior of the models based on the task difficulty defined by the semantic information gap -- which distinguishes inductive and deductive reasoning (Johnson-Laird, 1988, 1993). Our analysis reveals that the disparity in information between dialogue contexts and desired inferences poses a significant challenge to the inductive inference process. To mitigate this information gap, we investigate a contrastive learning approach by feeding negative samples. Our experiments suggest negative samples help models understand what is wrong and improve their inference generations.
InstructTODS: Large Language Models for End-to-End Task-Oriented Dialogue Systems
Oct 13, 2023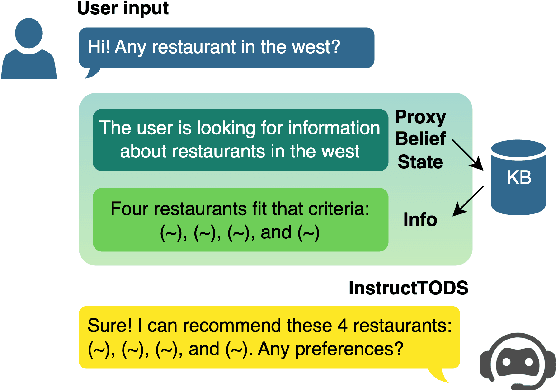
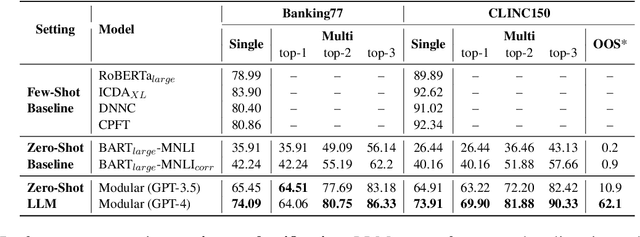
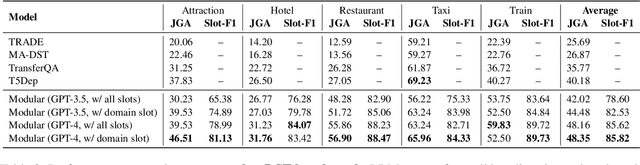
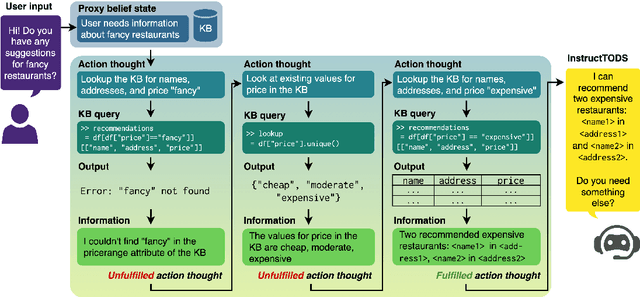
Large language models (LLMs) have been used for diverse tasks in natural language processing (NLP), yet remain under-explored for task-oriented dialogue systems (TODS), especially for end-to-end TODS. We present InstructTODS, a novel off-the-shelf framework for zero-shot end-to-end task-oriented dialogue systems that can adapt to diverse domains without fine-tuning. By leveraging LLMs, InstructTODS generates a proxy belief state that seamlessly translates user intentions into dynamic queries for efficient interaction with any KB. Our extensive experiments demonstrate that InstructTODS achieves comparable performance to fully fine-tuned TODS in guiding dialogues to successful completion without prior knowledge or task-specific data. Furthermore, a rigorous human evaluation of end-to-end TODS shows that InstructTODS produces dialogue responses that notably outperform both the gold responses and the state-of-the-art TODS in terms of helpfulness, informativeness, and humanness. Moreover, the effectiveness of LLMs in TODS is further supported by our comprehensive evaluations on TODS subtasks: dialogue state tracking, intent classification, and response generation. Code and implementations could be found here https://github.com/WillyHC22/InstructTODS/
Negative Object Presence Evaluation (NOPE) to Measure Object Hallucination in Vision-Language Models
Oct 09, 2023Object hallucination poses a significant challenge in vision-language (VL) models, often leading to the generation of nonsensical or unfaithful responses with non-existent objects. However, the absence of a general measurement for evaluating object hallucination in VL models has hindered our understanding and ability to mitigate this issue. In this work, we present NOPE (Negative Object Presence Evaluation), a novel benchmark designed to assess object hallucination in VL models through visual question answering (VQA). We propose a cost-effective and scalable approach utilizing large language models to generate 29.5k synthetic negative pronoun (NegP) data of high quality for NOPE. We extensively investigate the performance of 10 state-of-the-art VL models in discerning the non-existence of objects in visual questions, where the ground truth answers are denoted as NegP (e.g., "none"). Additionally, we evaluate their standard performance on visual questions on 9 other VQA datasets. Through our experiments, we demonstrate that no VL model is immune to the vulnerability of object hallucination, as all models achieve accuracy below 10\% on NegP. Furthermore, we uncover that lexically diverse visual questions, question types with large scopes, and scene-relevant objects capitalize the risk of object hallucination in VL models.
Survey of Social Bias in Vision-Language Models
Sep 24, 2023In recent years, the rapid advancement of machine learning (ML) models, particularly transformer-based pre-trained models, has revolutionized Natural Language Processing (NLP) and Computer Vision (CV) fields. However, researchers have discovered that these models can inadvertently capture and reinforce social biases present in their training datasets, leading to potential social harms, such as uneven resource allocation and unfair representation of specific social groups. Addressing these biases and ensuring fairness in artificial intelligence (AI) systems has become a critical concern in the ML community. The recent introduction of pre-trained vision-and-language (VL) models in the emerging multimodal field demands attention to the potential social biases present in these models as well. Although VL models are susceptible to social bias, there is a limited understanding compared to the extensive discussions on bias in NLP and CV. This survey aims to provide researchers with a high-level insight into the similarities and differences of social bias studies in pre-trained models across NLP, CV, and VL. By examining these perspectives, the survey aims to offer valuable guidelines on how to approach and mitigate social bias in both unimodal and multimodal settings. The findings and recommendations presented here can benefit the ML community, fostering the development of fairer and non-biased AI models in various applications and research endeavors.
NusaWrites: Constructing High-Quality Corpora for Underrepresented and Extremely Low-Resource Languages
Sep 20, 2023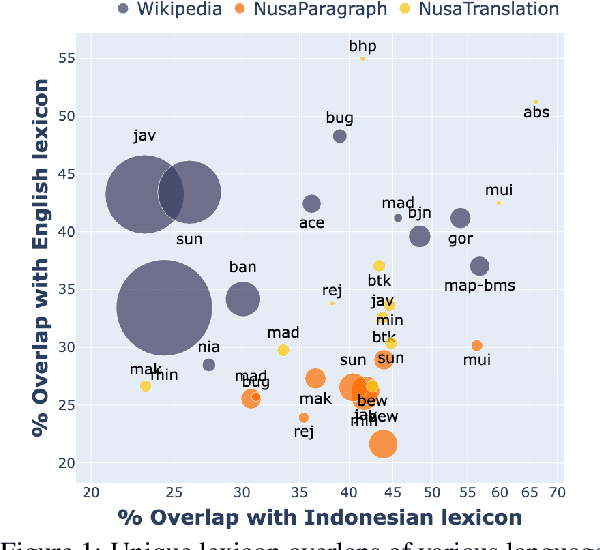
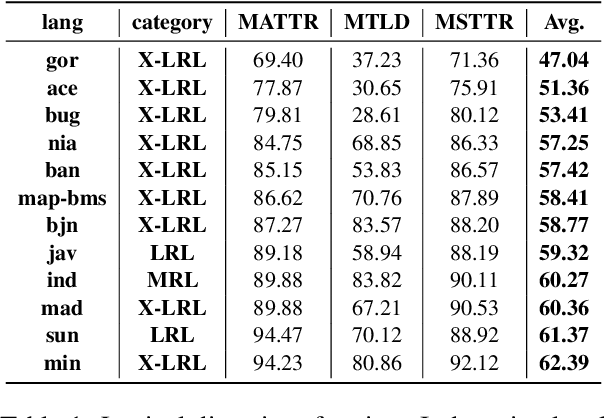
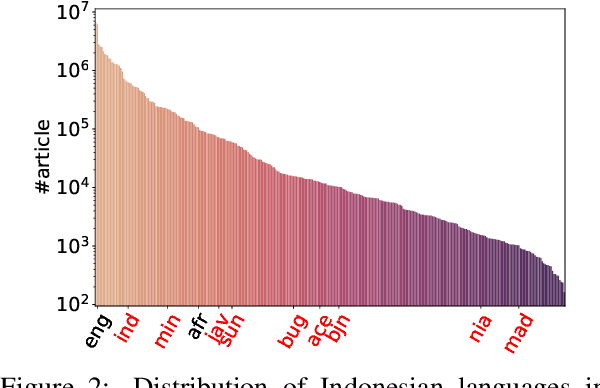
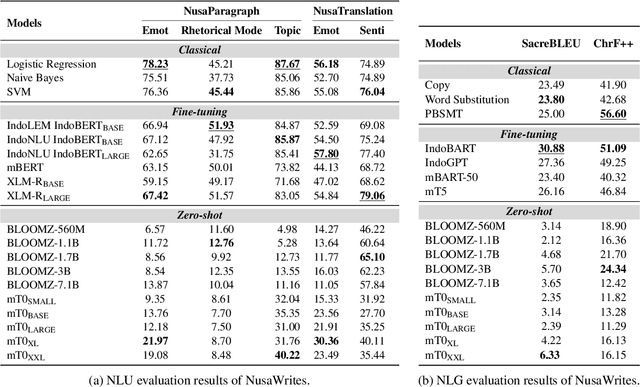
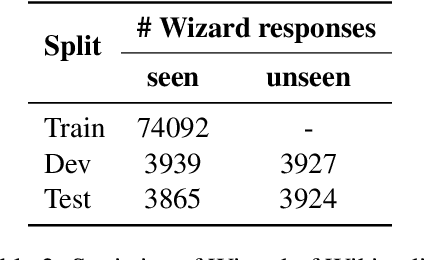
Democratizing access to natural language processing (NLP) technology is crucial, especially for underrepresented and extremely low-resource languages. Previous research has focused on developing labeled and unlabeled corpora for these languages through online scraping and document translation. While these methods have proven effective and cost-efficient, we have identified limitations in the resulting corpora, including a lack of lexical diversity and cultural relevance to local communities. To address this gap, we conduct a case study on Indonesian local languages. We compare the effectiveness of online scraping, human translation, and paragraph writing by native speakers in constructing datasets. Our findings demonstrate that datasets generated through paragraph writing by native speakers exhibit superior quality in terms of lexical diversity and cultural content. In addition, we present the \datasetname{} benchmark, encompassing 12 underrepresented and extremely low-resource languages spoken by millions of individuals in Indonesia. Our empirical experiment results using existing multilingual large language models conclude the need to extend these models to more underrepresented languages. We release the NusaWrites dataset at https://github.com/IndoNLP/nusa-writes.
PICK: Polished & Informed Candidate Scoring for Knowledge-Grounded Dialogue Systems
Sep 19, 2023
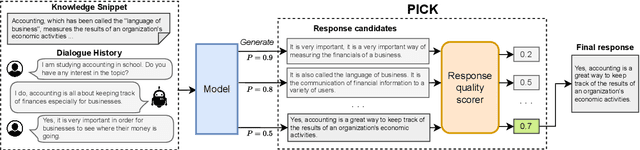

Grounding dialogue response generation on external knowledge is proposed to produce informative and engaging responses. However, current knowledge-grounded dialogue (KGD) systems often fail to align the generated responses with human-preferred qualities due to several issues like hallucination and the lack of coherence. Upon analyzing multiple language model generations, we observe the presence of alternative generated responses within a single decoding process. These alternative responses are more faithful and exhibit a comparable or higher level of relevance to prior conversational turns compared to the optimal responses prioritized by the decoding processes. To address these challenges and driven by these observations, we propose Polished \& Informed Candidate Scoring (PICK), a generation re-scoring framework that empowers models to generate faithful and relevant responses without requiring additional labeled data or model tuning. Through comprehensive automatic and human evaluations, we demonstrate the effectiveness of PICK in generating responses that are more faithful while keeping them relevant to the dialogue history. Furthermore, PICK consistently improves the system's performance with both oracle and retrieved knowledge in all decoding strategies. We provide the detailed implementation in https://github.com/bryanwilie/pick .
Cross-Lingual Cross-Age Group Adaptation for Low-Resource Elderly Speech Emotion Recognition
Jun 26, 2023



Speech emotion recognition plays a crucial role in human-computer interactions. However, most speech emotion recognition research is biased toward English-speaking adults, which hinders its applicability to other demographic groups in different languages and age groups. In this work, we analyze the transferability of emotion recognition across three different languages--English, Mandarin Chinese, and Cantonese; and 2 different age groups--adults and the elderly. To conduct the experiment, we develop an English-Mandarin speech emotion benchmark for adults and the elderly, BiMotion, and a Cantonese speech emotion dataset, YueMotion. This study concludes that different language and age groups require specific speech features, thus making cross-lingual inference an unsuitable method. However, cross-group data augmentation is still beneficial to regularize the model, with linguistic distance being a significant influence on cross-lingual transferability. We release publicly release our code at https://github.com/HLTCHKUST/elderly_ser.
Instruct-Align: Teaching Novel Languages with to LLMs through Alignment-based Cross-Lingual Instruction
May 23, 2023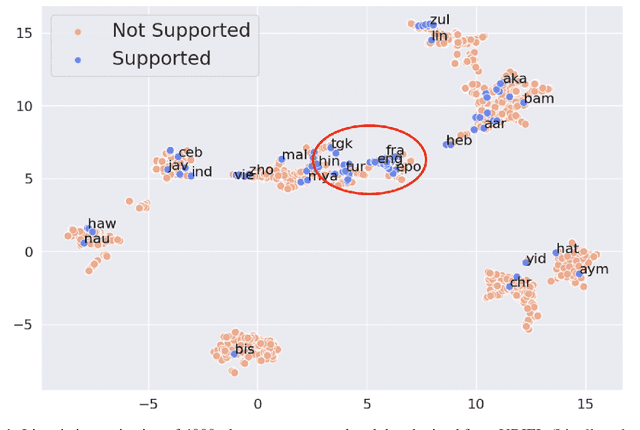

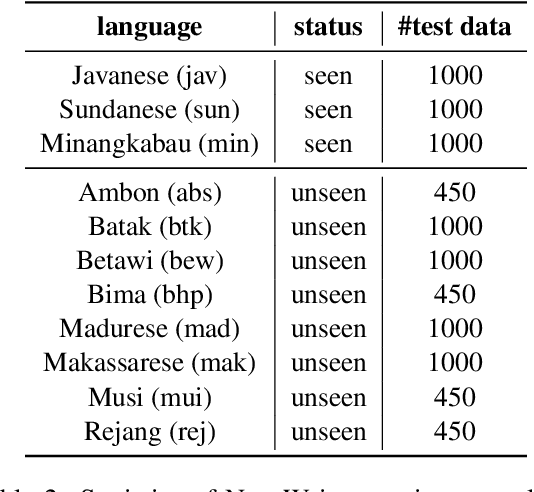
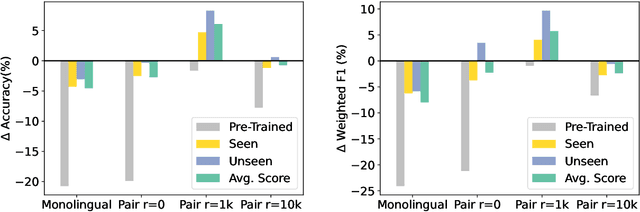
Instruction-tuned large language models (LLMs) have shown remarkable generalization capability over multiple tasks in multiple languages. Nevertheless, their generalization towards different languages varies especially to underrepresented languages or even to unseen languages. Prior works on adapting new languages to LLMs find that naively adapting new languages to instruction-tuned LLMs will result in catastrophic forgetting, which in turn causes the loss of multitasking ability in these LLMs. To tackle this, we propose the Instruct-Align a.k.a (IA)$^1$ framework, which enables instruction-tuned LLMs to learn cross-lingual alignment between unseen and previously learned languages via alignment-based cross-lingual instruction-tuning. Our preliminary result on BLOOMZ-560M shows that (IA)$^1$ is able to learn a new language effectively with only a limited amount of parallel data and at the same time prevent catastrophic forgetting by applying continual instruction-tuning through experience replay. Our work contributes to the progression of language adaptation methods for instruction-tuned LLMs and opens up the possibility of adapting underrepresented low-resource languages into existing instruction-tuned LLMs. Our code will be publicly released upon acceptance.