 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBharat Venkitesh
SnapKV: LLM Knows What You are Looking for Before Generation
Apr 22, 2024




Large Language Models (LLMs) have made remarkable progress in processing extensive contexts, with the Key-Value (KV) cache playing a vital role in enhancing their performance. However, the growth of the KV cache in response to increasing input length poses challenges to memory and time efficiency. To address this problem, this paper introduces SnapKV, an innovative and fine-tuning-free approach that efficiently minimizes KV cache size while still delivering comparable performance in real-world applications. We discover that each attention head in the model consistently focuses on specific prompt attention features during generation. Meanwhile, this robust pattern can be obtained from an `observation' window located at the end of the prompts. Drawing on this insight, SnapKV automatically compresses KV caches by selecting clustered important KV positions for each attention head. Our approach significantly reduces the growing computational overhead and memory footprint when processing long input sequences. Specifically, SnapKV achieves a consistent decoding speed with a 3.6x increase in generation speed and an 8.2x enhancement in memory efficiency compared to baseline when processing inputs of 16K tokens. At the same time, it maintains comparable performance to baseline models across 16 long sequence datasets. Moreover, SnapKV can process up to 380K context tokens on a single A100-80GB GPU using HuggingFace implementation with minor changes, exhibiting only a negligible accuracy drop in the Needle-in-a-Haystack test. Further comprehensive studies suggest SnapKV's potential for practical applications.
Intriguing Properties of Quantization at Scale
May 30, 2023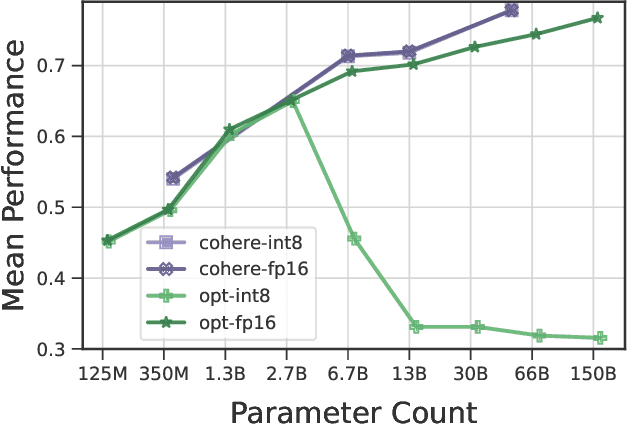
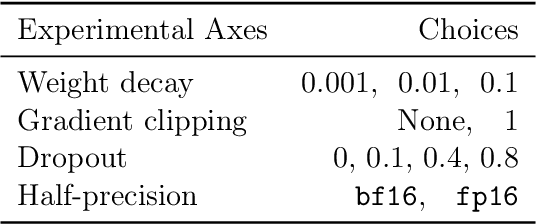
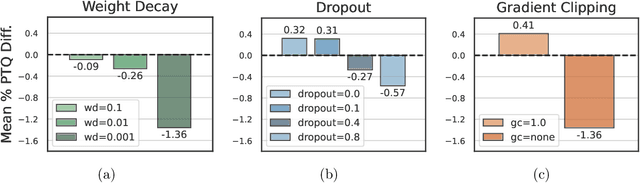

Emergent properties have been widely adopted as a term to describe behavior not present in smaller models but observed in larger models. Recent work suggests that the trade-off incurred by quantization is also an emergent property, with sharp drops in performance in models over 6B parameters. In this work, we ask "are quantization cliffs in performance solely a factor of scale?" Against a backdrop of increased research focus on why certain emergent properties surface at scale, this work provides a useful counter-example. We posit that it is possible to optimize for a quantization friendly training recipe that suppresses large activation magnitude outliers. Here, we find that outlier dimensions are not an inherent product of scale, but rather sensitive to the optimization conditions present during pre-training. This both opens up directions for more efficient quantization, and poses the question of whether other emergent properties are inherent or can be altered and conditioned by optimization and architecture design choices. We successfully quantize models ranging in size from 410M to 52B with minimal degradation in performance.
Exploring Low Rank Training of Deep Neural Networks
Sep 27, 2022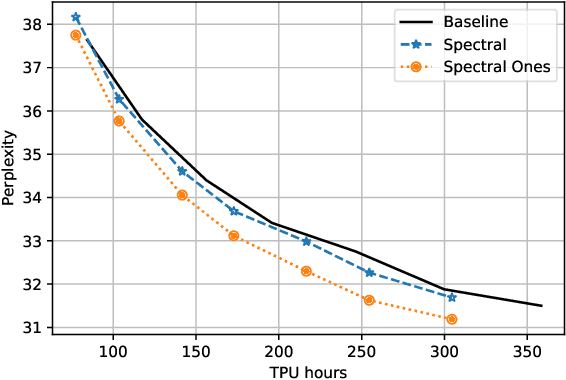

Training deep neural networks in low rank, i.e. with factorised layers, is of particular interest to the community: it offers efficiency over unfactorised training in terms of both memory consumption and training time. Prior work has focused on low rank approximations of pre-trained networks and training in low rank space with additional objectives, offering various ad hoc explanations for chosen practice. We analyse techniques that work well in practice, and through extensive ablations on models such as GPT2 we provide evidence falsifying common beliefs in the field, hinting in the process at exciting research opportunities that still need answering.
Fully Quantizing a Simplified Transformer for End-to-end Speech Recognition
Nov 09, 2019



While significant improvements have been made in recent years in terms of end-to-end automatic speech recognition (ASR) performance, such improvements were obtained through the use of very large neural networks, unfit for embedded use on edge devices. That being said, in this paper, we work on simplifying and compressing Transformer-based encoder-decoder architectures for the end-to-end ASR task. We empirically introduce a more compact Speech-Transformer by investigating the impact of discarding particular modules on the performance of the model. Moreover, we evaluate reducing the numerical precision of our network's weights and activations while maintaining the performance of the full-precision model. Our experiments show that we can reduce the number of parameters of the full-precision model and then further compress the model 4x by fully quantizing to 8-bit fixed point precision.