 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArash Ahmadian
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Feb 26, 2024
AI alignment in the shape of Reinforcement Learning from Human Feedback (RLHF) is increasingly treated as a crucial ingredient for high performance large language models. Proximal Policy Optimization (PPO) has been positioned by recent literature as the canonical method for the RL part of RLHF. However, it involves both high computational cost and sensitive hyperparameter tuning. We posit that most of the motivational principles that led to the development of PPO are less of a practical concern in RLHF and advocate for a less computationally expensive method that preserves and even increases performance. We revisit the formulation of alignment from human preferences in the context of RL. Keeping simplicity as a guiding principle, we show that many components of PPO are unnecessary in an RLHF context and that far simpler REINFORCE-style optimization variants outperform both PPO and newly proposed "RL-free" methods such as DPO and RAFT. Our work suggests that careful adaptation to LLMs alignment characteristics enables benefiting from online RL optimization at low cost.
Pushing Mixture of Experts to the Limit: Extremely Parameter Efficient MoE for Instruction Tuning
Sep 11, 2023



The Mixture of Experts (MoE) is a widely known neural architecture where an ensemble of specialized sub-models optimizes overall performance with a constant computational cost. However, conventional MoEs pose challenges at scale due to the need to store all experts in memory. In this paper, we push MoE to the limit. We propose extremely parameter-efficient MoE by uniquely combining MoE architecture with lightweight experts.Our MoE architecture outperforms standard parameter-efficient fine-tuning (PEFT) methods and is on par with full fine-tuning by only updating the lightweight experts -- less than 1% of an 11B parameters model. Furthermore, our method generalizes to unseen tasks as it does not depend on any prior task knowledge. Our research underscores the versatility of the mixture of experts architecture, showcasing its ability to deliver robust performance even when subjected to rigorous parameter constraints. Our code used in all the experiments is publicly available here: https://github.com/for-ai/parameter-efficient-moe.
$λ$-AC: Learning latent decision-aware models for reinforcement learning in continuous state-spaces
Jun 30, 2023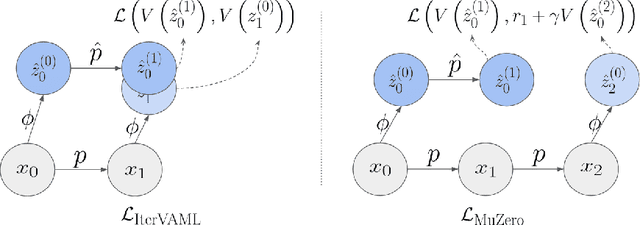

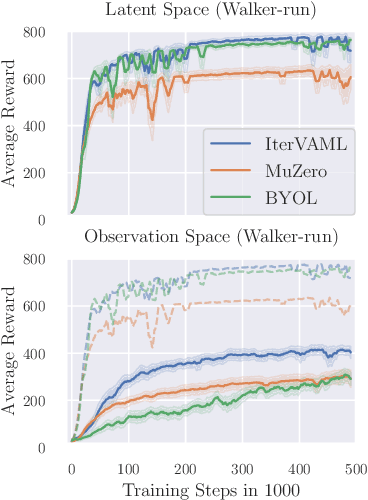
The idea of decision-aware model learning, that models should be accurate where it matters for decision-making, has gained prominence in model-based reinforcement learning. While promising theoretical results have been established, the empirical performance of algorithms leveraging a decision-aware loss has been lacking, especially in continuous control problems. In this paper, we present a study on the necessary components for decision-aware reinforcement learning models and we showcase design choices that enable well-performing algorithms. To this end, we provide a theoretical and empirical investigation into prominent algorithmic ideas in the field. We highlight that empirical design decisions established in the MuZero line of works are vital to achieving good performance for related algorithms, and we showcase differences in behavior between different instantiations of value-aware algorithms in stochastic environments. Using these insights, we propose the Latent Model-Based Decision-Aware Actor-Critic framework ($\lambda$-AC) for decision-aware model-based reinforcement learning in continuous state-spaces and highlight important design choices in different environments.
Intriguing Properties of Quantization at Scale
May 30, 2023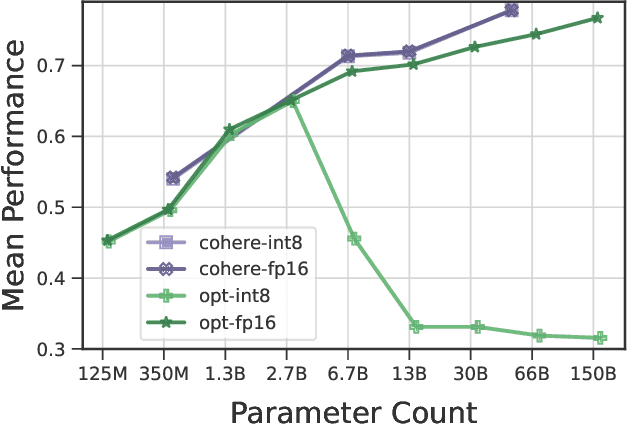
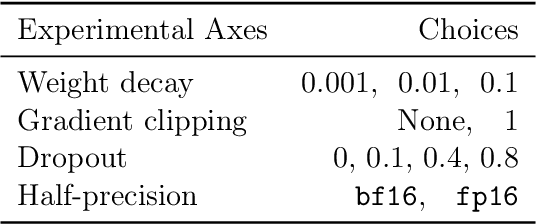
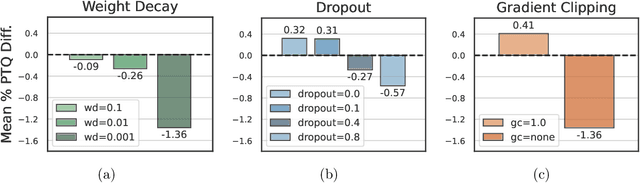

Emergent properties have been widely adopted as a term to describe behavior not present in smaller models but observed in larger models. Recent work suggests that the trade-off incurred by quantization is also an emergent property, with sharp drops in performance in models over 6B parameters. In this work, we ask "are quantization cliffs in performance solely a factor of scale?" Against a backdrop of increased research focus on why certain emergent properties surface at scale, this work provides a useful counter-example. We posit that it is possible to optimize for a quantization friendly training recipe that suppresses large activation magnitude outliers. Here, we find that outlier dimensions are not an inherent product of scale, but rather sensitive to the optimization conditions present during pre-training. This both opens up directions for more efficient quantization, and poses the question of whether other emergent properties are inherent or can be altered and conditioned by optimization and architecture design choices. We successfully quantize models ranging in size from 410M to 52B with minimal degradation in performance.
Pseudo-Inverted Bottleneck Convolution for DARTS Search Space
Dec 31, 2022



Differentiable Architecture Search (DARTS) has attracted considerable attention as a gradient-based Neural Architecture Search (NAS) method. Since the introduction of DARTS, there has been little work done on adapting the action space based on state-of-art architecture design principles for CNNs. In this work, we aim to address this gap by incrementally augmenting the DARTS search space with micro-design changes inspired by ConvNeXt and studying the trade-off between accuracy, evaluation layer count, and computational cost. To this end, we introduce the Pseudo-Inverted Bottleneck conv block intending to reduce the computational footprint of the inverted bottleneck block proposed in ConvNeXt. Our proposed architecture is much less sensitive to evaluation layer count and outperforms a DARTS network with similar size significantly, at layer counts as small as 2. Furthermore, with less layers, not only does it achieve higher accuracy with lower GMACs and parameter count, GradCAM comparisons show that our network is able to better detect distinctive features of target objects compared to DARTS.
Subspace Learning for Feature Selection via Rank Revealing QR Factorization: Unsupervised and Hybrid Approaches with Non-negative Matrix Factorization and Evolutionary Algorithm
Oct 02, 2022



The selection of most informative and discriminative features from high-dimensional data has been noticed as an important topic in machine learning and data engineering. Using matrix factorization-based techniques such as nonnegative matrix factorization for feature selection has emerged as a hot topic in feature selection. The main goal of feature selection using matrix factorization is to extract a subspace which approximates the original space but in a lower dimension. In this study, rank revealing QR (RRQR) factorization, which is computationally cheaper than singular value decomposition (SVD), is leveraged in obtaining the most informative features as a novel unsupervised feature selection technique. This technique uses the permutation matrix of QR for feature selection which is a unique property to this factorization method. Moreover, QR factorization is embedded into non-negative matrix factorization (NMF) objective function as a new unsupervised feature selection method. Lastly, a hybrid feature selection algorithm is proposed by coupling RRQR, as a filter-based technique, and a Genetic algorithm as a wrapper-based technique. In this method, redundant features are removed using RRQR factorization and the most discriminative subset of features are selected using the Genetic algorithm. The proposed algorithm shows to be dependable and robust when compared against state-of-the-art feature selection algorithms in supervised, unsupervised, and semi-supervised settings. All methods are tested on seven available microarray datasets using KNN, SVM and C4.5 classifiers. In terms of evaluation metrics, the experimental results shows that the proposed method is comparable with the state-of-the-art feature selection.