 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKonstantinos N. Plataniotis
ATOM: Attention Mixer for Efficient Dataset Distillation
May 02, 2024
Recent works in dataset distillation seek to minimize training expenses by generating a condensed synthetic dataset that encapsulates the information present in a larger real dataset. These approaches ultimately aim to attain test accuracy levels akin to those achieved by models trained on the entirety of the original dataset. Previous studies in feature and distribution matching have achieved significant results without incurring the costs of bi-level optimization in the distillation process. Despite their convincing efficiency, many of these methods suffer from marginal downstream performance improvements, limited distillation of contextual information, and subpar cross-architecture generalization. To address these challenges in dataset distillation, we propose the ATtentiOn Mixer (ATOM) module to efficiently distill large datasets using a mixture of channel and spatial-wise attention in the feature matching process. Spatial-wise attention helps guide the learning process based on consistent localization of classes in their respective images, allowing for distillation from a broader receptive field. Meanwhile, channel-wise attention captures the contextual information associated with the class itself, thus making the synthetic image more informative for training. By integrating both types of attention, our ATOM module demonstrates superior performance across various computer vision datasets, including CIFAR10/100 and TinyImagenet. Notably, our method significantly improves performance in scenarios with a low number of images per class, thereby enhancing its potential. Furthermore, we maintain the improvement in cross-architectures and applications such as neural architecture search.
The Need for Speed: Pruning Transformers with One Recipe
Mar 26, 2024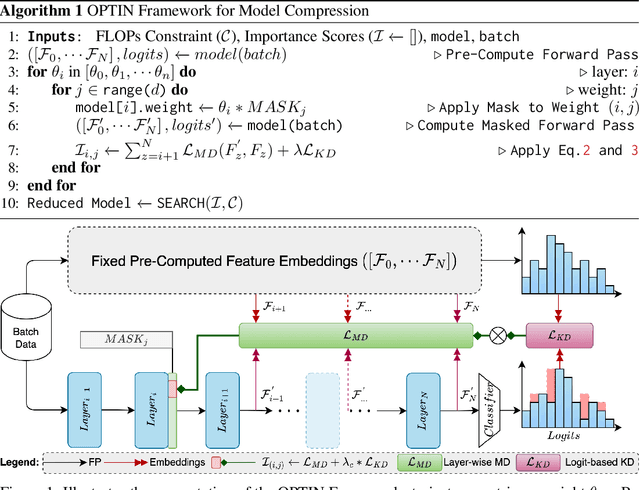
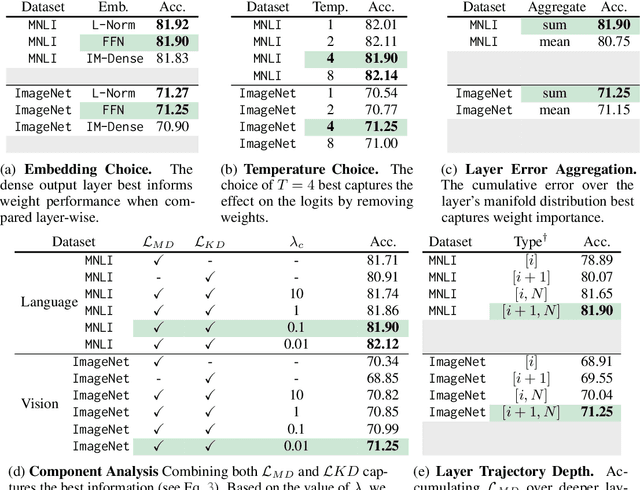

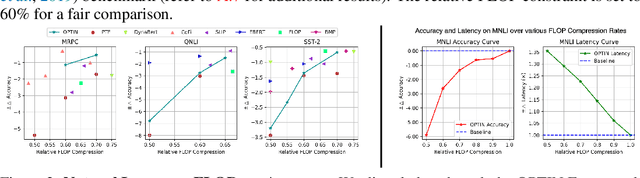
We introduce the $\textbf{O}$ne-shot $\textbf{P}$runing $\textbf{T}$echnique for $\textbf{I}$nterchangeable $\textbf{N}$etworks ($\textbf{OPTIN}$) framework as a tool to increase the efficiency of pre-trained transformer architectures $\textit{without requiring re-training}$. Recent works have explored improving transformer efficiency, however often incur computationally expensive re-training procedures or depend on architecture-specific characteristics, thus impeding practical wide-scale adoption. To address these shortcomings, the OPTIN framework leverages intermediate feature distillation, capturing the long-range dependencies of model parameters (coined $\textit{trajectory}$), to produce state-of-the-art results on natural language, image classification, transfer learning, and semantic segmentation tasks $\textit{without re-training}$. Given a FLOP constraint, the OPTIN framework will compress the network while maintaining competitive accuracy performance and improved throughput. Particularly, we show a $\leq 2$% accuracy degradation from NLP baselines and a $0.5$% improvement from state-of-the-art methods on image classification at competitive FLOPs reductions. We further demonstrate the generalization of tasks and architecture with comparative performance using Mask2Former for semantic segmentation and cnn-style networks. OPTIN presents one of the first one-shot efficient frameworks for compressing transformer architectures that generalizes well across different class domains, in particular: natural language and image-related tasks, without $\textit{re-training}$.
Comp4D: LLM-Guided Compositional 4D Scene Generation
Mar 25, 2024Recent advancements in diffusion models for 2D and 3D content creation have sparked a surge of interest in generating 4D content. However, the scarcity of 3D scene datasets constrains current methodologies to primarily object-centric generation. To overcome this limitation, we present Comp4D, a novel framework for Compositional 4D Generation. Unlike conventional methods that generate a singular 4D representation of the entire scene, Comp4D innovatively constructs each 4D object within the scene separately. Utilizing Large Language Models (LLMs), the framework begins by decomposing an input text prompt into distinct entities and maps out their trajectories. It then constructs the compositional 4D scene by accurately positioning these objects along their designated paths. To refine the scene, our method employs a compositional score distillation technique guided by the pre-defined trajectories, utilizing pre-trained diffusion models across text-to-image, text-to-video, and text-to-3D domains. Extensive experiments demonstrate our outstanding 4D content creation capability compared to prior arts, showcasing superior visual quality, motion fidelity, and enhanced object interactions.
FedD2S: Personalized Data-Free Federated Knowledge Distillation
Feb 16, 2024This paper addresses the challenge of mitigating data heterogeneity among clients within a Federated Learning (FL) framework. The model-drift issue, arising from the noniid nature of client data, often results in suboptimal personalization of a global model compared to locally trained models for each client. To tackle this challenge, we propose a novel approach named FedD2S for Personalized Federated Learning (pFL), leveraging knowledge distillation. FedD2S incorporates a deep-to-shallow layer-dropping mechanism in the data-free knowledge distillation process to enhance local model personalization. Through extensive simulations on diverse image datasets-FEMNIST, CIFAR10, CINIC0, and CIFAR100-we compare FedD2S with state-of-the-art FL baselines. The proposed approach demonstrates superior performance, characterized by accelerated convergence and improved fairness among clients. The introduced layer-dropping technique effectively captures personalized knowledge, resulting in enhanced performance compared to alternative FL models. Moreover, we investigate the impact of key hyperparameters, such as the participation ratio and layer-dropping rate, providing valuable insights into the optimal configuration for FedD2S. The findings demonstrate the efficacy of adaptive layer-dropping in the knowledge distillation process to achieve enhanced personalization and performance across diverse datasets and tasks.
HistoSegCap: Capsules for Weakly-Supervised Semantic Segmentation of Histological Tissue Type in Whole Slide Images
Feb 16, 2024Digital pathology involves converting physical tissue slides into high-resolution Whole Slide Images (WSIs), which pathologists analyze for disease-affected tissues. However, large histology slides with numerous microscopic fields pose challenges for visual search. To aid pathologists, Computer Aided Diagnosis (CAD) systems offer visual assistance in efficiently examining WSIs and identifying diagnostically relevant regions. This paper presents a novel histopathological image analysis method employing Weakly Supervised Semantic Segmentation (WSSS) based on Capsule Networks, the first such application. The proposed model is evaluated using the Atlas of Digital Pathology (ADP) dataset and its performance is compared with other histopathological semantic segmentation methodologies. The findings underscore the potential of Capsule Networks in enhancing the precision and efficiency of histopathological image analysis. Experimental results show that the proposed model outperforms traditional methods in terms of accuracy and the mean Intersection-over-Union (mIoU) metric.
NYCTALE: Neuro-Evidence Transformer for Adaptive and Personalized Lung Nodule Invasiveness Prediction
Feb 15, 2024Drawing inspiration from the primate brain's intriguing evidence accumulation process, and guided by models from cognitive psychology and neuroscience, the paper introduces the NYCTALE framework, a neuro-inspired and evidence accumulation-based Transformer architecture. The proposed neuro-inspired NYCTALE offers a novel pathway in the domain of Personalized Medicine (PM) for lung cancer diagnosis. In nature, Nyctales are small owls known for their nocturnal behavior, hunting primarily during the darkness of night. The NYCTALE operates in a similarly vigilant manner, i.e., processing data in an evidence-based fashion and making predictions dynamically/adaptively. Distinct from conventional Computed Tomography (CT)-based Deep Learning (DL) models, the NYCTALE performs predictions only when sufficient amount of evidence is accumulated. In other words, instead of processing all or a pre-defined subset of CT slices, for each person, slices are provided one at a time. The NYCTALE framework then computes an evidence vector associated with contribution of each new CT image. A decision is made once the total accumulated evidence surpasses a specific threshold. Preliminary experimental analyses conducted using a challenging in-house dataset comprising 114 subjects. The results are noteworthy, suggesting that NYCTALE outperforms the benchmark accuracy even with approximately 60% less training data on this demanding and small dataset.
A Robust Quantile Huber Loss With Interpretable Parameter Adjustment In Distributional Reinforcement Learning
Jan 07, 2024Distributional Reinforcement Learning (RL) estimates return distribution mainly by learning quantile values via minimizing the quantile Huber loss function, entailing a threshold parameter often selected heuristically or via hyperparameter search, which may not generalize well and can be suboptimal. This paper introduces a generalized quantile Huber loss function derived from Wasserstein distance (WD) calculation between Gaussian distributions, capturing noise in predicted (current) and target (Bellman-updated) quantile values. Compared to the classical quantile Huber loss, this innovative loss function enhances robustness against outliers. Notably, the classical Huber loss function can be seen as an approximation of our proposed loss, enabling parameter adjustment by approximating the amount of noise in the data during the learning process. Empirical tests on Atari games, a common application in distributional RL, and a recent hedging strategy using distributional RL, validate the effectiveness of our proposed loss function and its potential for parameter adjustments in distributional RL. The implementation of the proposed loss function is available here.
A unified uncertainty-aware exploration: Combining epistemic and aleatory uncertainty
Jan 05, 2024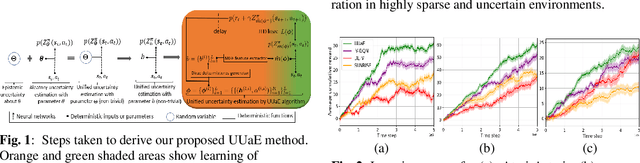
Exploration is a significant challenge in practical reinforcement learning (RL), and uncertainty-aware exploration that incorporates the quantification of epistemic and aleatory uncertainty has been recognized as an effective exploration strategy. However, capturing the combined effect of aleatory and epistemic uncertainty for decision-making is difficult. Existing works estimate aleatory and epistemic uncertainty separately and consider the composite uncertainty as an additive combination of the two. Nevertheless, the additive formulation leads to excessive risk-taking behavior, causing instability. In this paper, we propose an algorithm that clarifies the theoretical connection between aleatory and epistemic uncertainty, unifies aleatory and epistemic uncertainty estimation, and quantifies the combined effect of both uncertainties for a risk-sensitive exploration. Our method builds on a novel extension of distributional RL that estimates a parameterized return distribution whose parameters are random variables encoding epistemic uncertainty. Experimental results on tasks with exploration and risk challenges show that our method outperforms alternative approaches.
ProbMCL: Simple Probabilistic Contrastive Learning for Multi-label Visual Classification
Jan 02, 2024Multi-label image classification presents a challenging task in many domains, including computer vision and medical imaging. Recent advancements have introduced graph-based and transformer-based methods to improve performance and capture label dependencies. However, these methods often include complex modules that entail heavy computation and lack interpretability. In this paper, we propose Probabilistic Multi-label Contrastive Learning (ProbMCL), a novel framework to address these challenges in multi-label image classification tasks. Our simple yet effective approach employs supervised contrastive learning, in which samples that share enough labels with an anchor image based on a decision threshold are introduced as a positive set. This structure captures label dependencies by pulling positive pair embeddings together and pushing away negative samples that fall below the threshold. We enhance representation learning by incorporating a mixture density network into contrastive learning and generating Gaussian mixture distributions to explore the epistemic uncertainty of the feature encoder. We validate the effectiveness of our framework through experimentation with datasets from the computer vision and medical imaging domains. Our method outperforms the existing state-of-the-art methods while achieving a low computational footprint on both datasets. Visualization analyses also demonstrate that ProbMCL-learned classifiers maintain a meaningful semantic topology.
Test-Time Domain Adaptation by Learning Domain-Aware Batch Normalization
Dec 15, 2023Test-time domain adaptation aims to adapt the model trained on source domains to unseen target domains using a few unlabeled images. Emerging research has shown that the label and domain information is separately embedded in the weight matrix and batch normalization (BN) layer. Previous works normally update the whole network naively without explicitly decoupling the knowledge between label and domain. As a result, it leads to knowledge interference and defective distribution adaptation. In this work, we propose to reduce such learning interference and elevate the domain knowledge learning by only manipulating the BN layer. However, the normalization step in BN is intrinsically unstable when the statistics are re-estimated from a few samples. We find that ambiguities can be greatly reduced when only updating the two affine parameters in BN while keeping the source domain statistics. To further enhance the domain knowledge extraction from unlabeled data, we construct an auxiliary branch with label-independent self-supervised learning (SSL) to provide supervision. Moreover, we propose a bi-level optimization based on meta-learning to enforce the alignment of two learning objectives of auxiliary and main branches. The goal is to use the auxiliary branch to adapt the domain and benefit main task for subsequent inference. Our method keeps the same computational cost at inference as the auxiliary branch can be thoroughly discarded after adaptation. Extensive experiments show that our method outperforms the prior works on five WILDS real-world domain shift datasets. Our method can also be integrated with methods with label-dependent optimization to further push the performance boundary. Our code is available at https://github.com/ynanwu/MABN.