 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeyu Wang
Camera-Based Remote Physiology Sensing for Hundreds of Subjects Across Skin Tones
Apr 07, 2024
Remote photoplethysmography (rPPG) emerges as a promising method for non-invasive, convenient measurement of vital signs, utilizing the widespread presence of cameras. Despite advancements, existing datasets fall short in terms of size and diversity, limiting comprehensive evaluation under diverse conditions. This paper presents an in-depth analysis of the VitalVideo dataset, the largest real-world rPPG dataset to date, encompassing 893 subjects and 6 Fitzpatrick skin tones. Our experimentation with six unsupervised methods and three supervised models demonstrates that datasets comprising a few hundred subjects(i.e., 300 for UBFC-rPPG, 500 for PURE, and 700 for MMPD-Simple) are sufficient for effective rPPG model training. Our findings highlight the importance of diversity and consistency in skin tones for precise performance evaluation across different datasets.
HeadEvolver: Text to Head Avatars via Locally Learnable Mesh Deformation
Mar 14, 2024
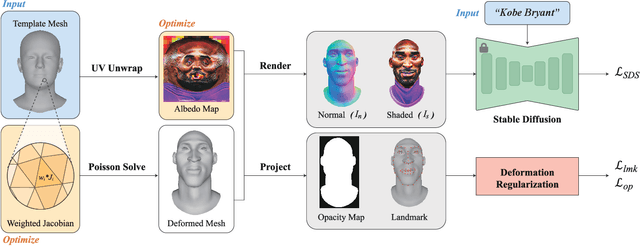
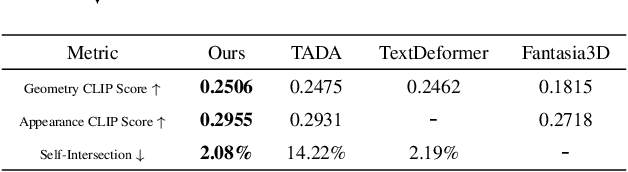
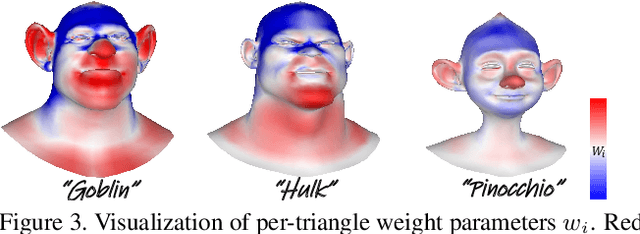
We present HeadEvolver, a novel framework to generate stylized head avatars from text guidance. HeadEvolver uses locally learnable mesh deformation from a template head mesh, producing high-quality digital assets for detail-preserving editing and animation. To tackle the challenges of lacking fine-grained and semantic-aware local shape control in global deformation through Jacobians, we introduce a trainable parameter as a weighting factor for the Jacobian at each triangle to adaptively change local shapes while maintaining global correspondences and facial features. Moreover, to ensure the coherence of the resulting shape and appearance from different viewpoints, we use pretrained image diffusion models for differentiable rendering with regularization terms to refine the deformation under text guidance. Extensive experiments demonstrate that our method can generate diverse head avatars with an articulated mesh that can be edited seamlessly in 3D graphics software, facilitating downstream applications such as more efficient animation with inherited blend shapes and semantic consistency.
SplattingAvatar: Realistic Real-Time Human Avatars with Mesh-Embedded Gaussian Splatting
Mar 08, 2024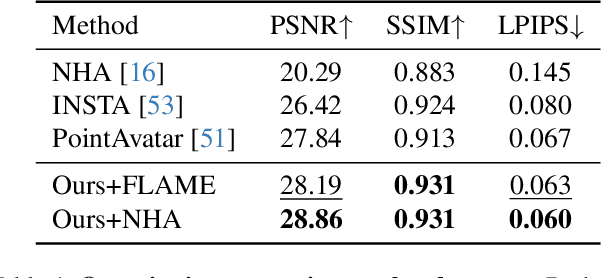
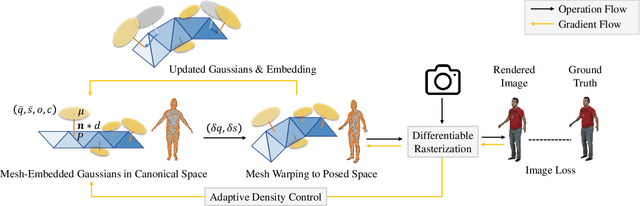


We present SplattingAvatar, a hybrid 3D representation of photorealistic human avatars with Gaussian Splatting embedded on a triangle mesh, which renders over 300 FPS on a modern GPU and 30 FPS on a mobile device. We disentangle the motion and appearance of a virtual human with explicit mesh geometry and implicit appearance modeling with Gaussian Splatting. The Gaussians are defined by barycentric coordinates and displacement on a triangle mesh as Phong surfaces. We extend lifted optimization to simultaneously optimize the parameters of the Gaussians while walking on the triangle mesh. SplattingAvatar is a hybrid representation of virtual humans where the mesh represents low-frequency motion and surface deformation, while the Gaussians take over the high-frequency geometry and detailed appearance. Unlike existing deformation methods that rely on an MLP-based linear blend skinning (LBS) field for motion, we control the rotation and translation of the Gaussians directly by mesh, which empowers its compatibility with various animation techniques, e.g., skeletal animation, blend shapes, and mesh editing. Trainable from monocular videos for both full-body and head avatars, SplattingAvatar shows state-of-the-art rendering quality across multiple datasets.
MemoNav: Working Memory Model for Visual Navigation
Feb 29, 2024Image-goal navigation is a challenging task that requires an agent to navigate to a goal indicated by an image in unfamiliar environments. Existing methods utilizing diverse scene memories suffer from inefficient exploration since they use all historical observations for decision-making without considering the goal-relevant fraction. To address this limitation, we present MemoNav, a novel memory model for image-goal navigation, which utilizes a working memory-inspired pipeline to improve navigation performance. Specifically, we employ three types of navigation memory. The node features on a map are stored in the short-term memory (STM), as these features are dynamically updated. A forgetting module then retains the informative STM fraction to increase efficiency. We also introduce long-term memory (LTM) to learn global scene representations by progressively aggregating STM features. Subsequently, a graph attention module encodes the retained STM and the LTM to generate working memory (WM) which contains the scene features essential for efficient navigation. The synergy among these three memory types boosts navigation performance by enabling the agent to learn and leverage goal-relevant scene features within a topological map. Our evaluation on multi-goal tasks demonstrates that MemoNav significantly outperforms previous methods across all difficulty levels in both Gibson and Matterport3D scenes. Qualitative results further illustrate that MemoNav plans more efficient routes.
Multi-Human Mesh Recovery with Transformers
Feb 26, 2024Conventional approaches to human mesh recovery predominantly employ a region-based strategy. This involves initially cropping out a human-centered region as a preprocessing step, with subsequent modeling focused on this zoomed-in image. While effective for single figures, this pipeline poses challenges when dealing with images featuring multiple individuals, as different people are processed separately, often leading to inaccuracies in relative positioning. Despite the advantages of adopting a whole-image-based approach to address this limitation, early efforts in this direction have fallen short in performance compared to recent region-based methods. In this work, we advocate for this under-explored area of modeling all people at once, emphasizing its potential for improved accuracy in multi-person scenarios through considering all individuals simultaneously and leveraging the overall context and interactions. We introduce a new model with a streamlined transformer-based design, featuring three critical design choices: multi-scale feature incorporation, focused attention mechanisms, and relative joint supervision. Our proposed model demonstrates a significant performance improvement, surpassing state-of-the-art region-based and whole-image-based methods on various benchmarks involving multiple individuals.
HiGen: Hierarchy-Aware Sequence Generation for Hierarchical Text Classification
Jan 24, 2024Hierarchical text classification (HTC) is a complex subtask under multi-label text classification, characterized by a hierarchical label taxonomy and data imbalance. The best-performing models aim to learn a static representation by combining document and hierarchical label information. However, the relevance of document sections can vary based on the hierarchy level, necessitating a dynamic document representation. To address this, we propose HiGen, a text-generation-based framework utilizing language models to encode dynamic text representations. We introduce a level-guided loss function to capture the relationship between text and label name semantics. Our approach incorporates a task-specific pretraining strategy, adapting the language model to in-domain knowledge and significantly enhancing performance for classes with limited examples. Furthermore, we present a new and valuable dataset called ENZYME, designed for HTC, which comprises articles from PubMed with the goal of predicting Enzyme Commission (EC) numbers. Through extensive experiments on the ENZYME dataset and the widely recognized WOS and NYT datasets, our methodology demonstrates superior performance, surpassing existing approaches while efficiently handling data and mitigating class imbalance. The data and code will be released publicly.
BoNuS: Boundary Mining for Nuclei Segmentation with Partial Point Labels
Jan 15, 2024Nuclei segmentation is a fundamental prerequisite in the digital pathology workflow. The development of automated methods for nuclei segmentation enables quantitative analysis of the wide existence and large variances in nuclei morphometry in histopathology images. However, manual annotation of tens of thousands of nuclei is tedious and time-consuming, which requires significant amount of human effort and domain-specific expertise. To alleviate this problem, in this paper, we propose a weakly-supervised nuclei segmentation method that only requires partial point labels of nuclei. Specifically, we propose a novel boundary mining framework for nuclei segmentation, named BoNuS, which simultaneously learns nuclei interior and boundary information from the point labels. To achieve this goal, we propose a novel boundary mining loss, which guides the model to learn the boundary information by exploring the pairwise pixel affinity in a multiple-instance learning manner. Then, we consider a more challenging problem, i.e., partial point label, where we propose a nuclei detection module with curriculum learning to detect the missing nuclei with prior morphological knowledge. The proposed method is validated on three public datasets, MoNuSeg, CPM, and CoNIC datasets. Experimental results demonstrate the superior performance of our method to the state-of-the-art weakly-supervised nuclei segmentation methods. Code: https://github.com/hust-linyi/bonus.
Multi-Modal Representation Learning for Molecular Property Prediction: Sequence, Graph, Geometry
Jan 09, 2024Molecular property prediction refers to the task of labeling molecules with some biochemical properties, playing a pivotal role in the drug discovery and design process. Recently, with the advancement of machine learning, deep learning-based molecular property prediction has emerged as a solution to the resource-intensive nature of traditional methods, garnering significant attention. Among them, molecular representation learning is the key factor for molecular property prediction performance. And there are lots of sequence-based, graph-based, and geometry-based methods that have been proposed. However, the majority of existing studies focus solely on one modality for learning molecular representations, failing to comprehensively capture molecular characteristics and information. In this paper, a novel multi-modal representation learning model, which integrates the sequence, graph, and geometry characteristics, is proposed for molecular property prediction, called SGGRL. Specifically, we design a fusion layer to fusion the representation of different modalities. Furthermore, to ensure consistency across modalities, SGGRL is trained to maximize the similarity of representations for the same molecule while minimizing similarity for different molecules. To verify the effectiveness of SGGRL, seven molecular datasets, and several baselines are used for evaluation and comparison. The experimental results demonstrate that SGGRL consistently outperforms the baselines in most cases. This further underscores the capability of SGGRL to comprehensively capture molecular information. Overall, the proposed SGGRL model showcases its potential to revolutionize molecular property prediction by leveraging multi-modal representation learning to extract diverse and comprehensive molecular insights. Our code is released at https://github.com/Vencent-Won/SGGRL.
Revisiting Adversarial Training at Scale
Jan 09, 2024The machine learning community has witnessed a drastic change in the training pipeline, pivoted by those ''foundation models'' with unprecedented scales. However, the field of adversarial training is lagging behind, predominantly centered around small model sizes like ResNet-50, and tiny and low-resolution datasets like CIFAR-10. To bridge this transformation gap, this paper provides a modern re-examination with adversarial training, investigating its potential benefits when applied at scale. Additionally, we introduce an efficient and effective training strategy to enable adversarial training with giant models and web-scale data at an affordable computing cost. We denote this newly introduced framework as AdvXL. Empirical results demonstrate that AdvXL establishes new state-of-the-art robust accuracy records under AutoAttack on ImageNet-1K. For example, by training on DataComp-1B dataset, our AdvXL empowers a vanilla ViT-g model to substantially surpass the previous records of $l_{\infty}$-, $l_{2}$-, and $l_{1}$-robust accuracy by margins of 11.4%, 14.2% and 12.9%, respectively. This achievement posits AdvXL as a pioneering approach, charting a new trajectory for the efficient training of robust visual representations at significantly larger scales. Our code is available at https://github.com/UCSC-VLAA/AdvXL.
A Robust Quantile Huber Loss With Interpretable Parameter Adjustment In Distributional Reinforcement Learning
Jan 07, 2024Distributional Reinforcement Learning (RL) estimates return distribution mainly by learning quantile values via minimizing the quantile Huber loss function, entailing a threshold parameter often selected heuristically or via hyperparameter search, which may not generalize well and can be suboptimal. This paper introduces a generalized quantile Huber loss function derived from Wasserstein distance (WD) calculation between Gaussian distributions, capturing noise in predicted (current) and target (Bellman-updated) quantile values. Compared to the classical quantile Huber loss, this innovative loss function enhances robustness against outliers. Notably, the classical Huber loss function can be seen as an approximation of our proposed loss, enabling parameter adjustment by approximating the amount of noise in the data during the learning process. Empirical tests on Atari games, a common application in distributional RL, and a recent hedging strategy using distributional RL, validate the effectiveness of our proposed loss function and its potential for parameter adjustments in distributional RL. The implementation of the proposed loss function is available here.