 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXinyi Li
Camera-Based Remote Physiology Sensing for Hundreds of Subjects Across Skin Tones
Apr 07, 2024
Remote photoplethysmography (rPPG) emerges as a promising method for non-invasive, convenient measurement of vital signs, utilizing the widespread presence of cameras. Despite advancements, existing datasets fall short in terms of size and diversity, limiting comprehensive evaluation under diverse conditions. This paper presents an in-depth analysis of the VitalVideo dataset, the largest real-world rPPG dataset to date, encompassing 893 subjects and 6 Fitzpatrick skin tones. Our experimentation with six unsupervised methods and three supervised models demonstrates that datasets comprising a few hundred subjects(i.e., 300 for UBFC-rPPG, 500 for PURE, and 700 for MMPD-Simple) are sufficient for effective rPPG model training. Our findings highlight the importance of diversity and consistency in skin tones for precise performance evaluation across different datasets.
A Multimodal Foundation Agent for Financial Trading: Tool-Augmented, Diversified, and Generalist
Feb 29, 2024Financial trading is a crucial component of the markets, informed by a multimodal information landscape encompassing news, prices, and Kline charts, and encompasses diverse tasks such as quantitative trading and high-frequency trading with various assets. While advanced AI techniques like deep learning and reinforcement learning are extensively utilized in finance, their application in financial trading tasks often faces challenges due to inadequate handling of multimodal data and limited generalizability across various tasks. To address these challenges, we present FinAgent, a multimodal foundational agent with tool augmentation for financial trading. FinAgent's market intelligence module processes a diverse range of data-numerical, textual, and visual-to accurately analyze the financial market. Its unique dual-level reflection module not only enables rapid adaptation to market dynamics but also incorporates a diversified memory retrieval system, enhancing the agent's ability to learn from historical data and improve decision-making processes. The agent's emphasis on reasoning for actions fosters trust in its financial decisions. Moreover, FinAgent integrates established trading strategies and expert insights, ensuring that its trading approaches are both data-driven and rooted in sound financial principles. With comprehensive experiments on 6 financial datasets, including stocks and Crypto, FinAgent significantly outperforms 9 state-of-the-art baselines in terms of 6 financial metrics with over 36% average improvement on profit. Specifically, a 92.27% return (a 84.39% relative improvement) is achieved on one dataset. Notably, FinAgent is the first advanced multimodal foundation agent designed for financial trading tasks.
Exploring Fine-tuning ChatGPT for News Recommendation
Nov 10, 2023
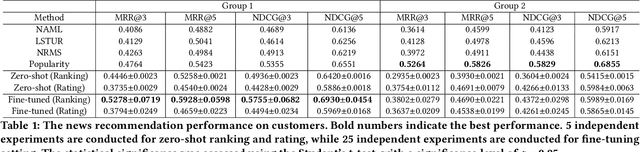
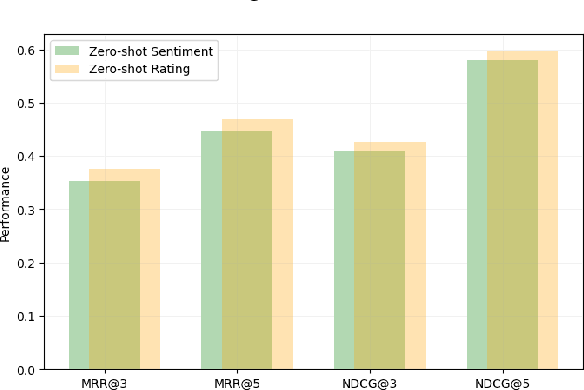
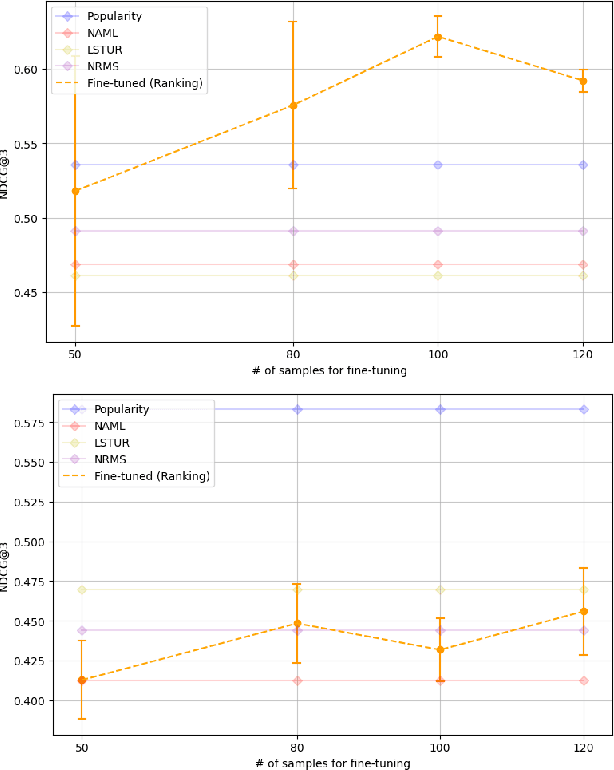
News recommendation systems (RS) play a pivotal role in the current digital age, shaping how individuals access and engage with information. The fusion of natural language processing (NLP) and RS, spurred by the rise of large language models such as the GPT and T5 series, blurs the boundaries between these domains, making a tendency to treat RS as a language task. ChatGPT, renowned for its user-friendly interface and increasing popularity, has become a prominent choice for a wide range of NLP tasks. While previous studies have explored ChatGPT on recommendation tasks, this study breaks new ground by investigating its fine-tuning capability, particularly within the news domain. In this study, we design two distinct prompts: one designed to treat news RS as the ranking task and another tailored for the rating task. We evaluate ChatGPT's performance in news recommendation by eliciting direct responses through the formulation of these two tasks. More importantly, we unravel the pivotal role of fine-tuning data quality in enhancing ChatGPT's personalized recommendation capabilities, and illustrates its potential in addressing the longstanding challenge of the "cold item" problem in RS. Our experiments, conducted using the Microsoft News dataset (MIND), reveal significant improvements achieved by ChatGPT after fine-tuning, especially in scenarios where a user's topic interests remain consistent, treating news RS as a ranking task. This study illuminates the transformative potential of fine-tuning ChatGPT as a means to advance news RS, offering more effective news consumption experiences.
Transformation Decoupling Strategy based on Screw Theory for Deterministic Point Cloud Registration with Gravity Prior
Nov 02, 2023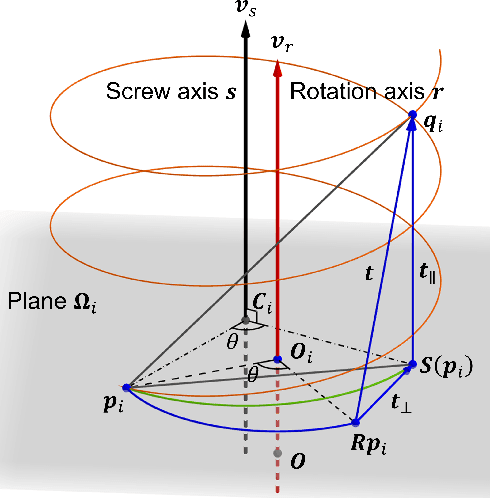
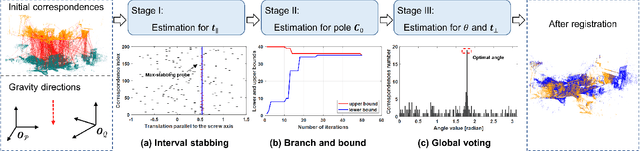

Point cloud registration is challenging in the presence of heavy outlier correspondences. This paper focuses on addressing the robust correspondence-based registration problem with gravity prior that often arises in practice. The gravity directions are typically obtained by inertial measurement units (IMUs) and can reduce the degree of freedom (DOF) of rotation from 3 to 1. We propose a novel transformation decoupling strategy by leveraging screw theory. This strategy decomposes the original 4-DOF problem into three sub-problems with 1-DOF, 2-DOF, and 1-DOF, respectively, thereby enhancing the computation efficiency. Specifically, the first 1-DOF represents the translation along the rotation axis and we propose an interval stabbing-based method to solve it. The second 2-DOF represents the pole which is an auxiliary variable in screw theory and we utilize a branch-and-bound method to solve it. The last 1-DOF represents the rotation angle and we propose a global voting method for its estimation. The proposed method sequentially solves three consensus maximization sub-problems, leading to efficient and deterministic registration. In particular, it can even handle the correspondence-free registration problem due to its significant robustness. Extensive experiments on both synthetic and real-world datasets demonstrate that our method is more efficient and robust than state-of-the-art methods, even when dealing with outlier rates exceeding 99%.
A Preliminary Study of ChatGPT on News Recommendation: Personalization, Provider Fairness, Fake News
Jun 19, 2023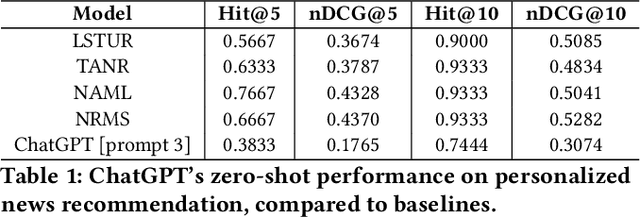


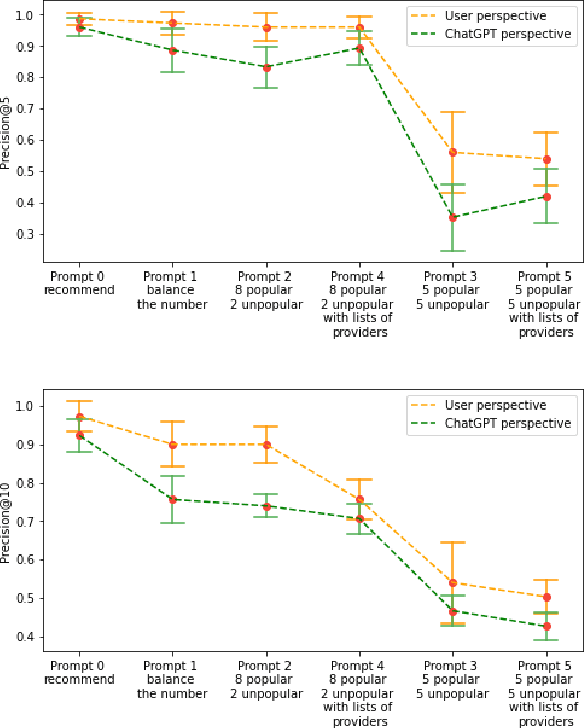
Online news platforms commonly employ personalized news recommendation methods to assist users in discovering interesting articles, and many previous works have utilized language model techniques to capture user interests and understand news content. With the emergence of large language models like GPT-3 and T-5, a new recommendation paradigm has emerged, leveraging pre-trained language models for making recommendations. ChatGPT, with its user-friendly interface and growing popularity, has become a prominent choice for text-based tasks. Considering the growing reliance on ChatGPT for language tasks, the importance of news recommendation in addressing social issues, and the trend of using language models in recommendations, this study conducts an initial investigation of ChatGPT's performance in news recommendations, focusing on three perspectives: personalized news recommendation, news provider fairness, and fake news detection. ChatGPT has the limitation that its output is sensitive to the input phrasing. We therefore aim to explore the constraints present in the generated responses of ChatGPT for each perspective. Additionally, we investigate whether specific prompt formats can alleviate these constraints or if these limitations require further attention from researchers in the future. We also surpass fixed evaluations by developing a webpage to monitor ChatGPT's performance on weekly basis on the tasks and prompts we investigated. Our aim is to contribute to and encourage more researchers to engage in the study of enhancing news recommendation performance through the utilization of large language models such as ChatGPT.
Continual Learning for Abdominal Multi-Organ and Tumor Segmentation
Jun 01, 2023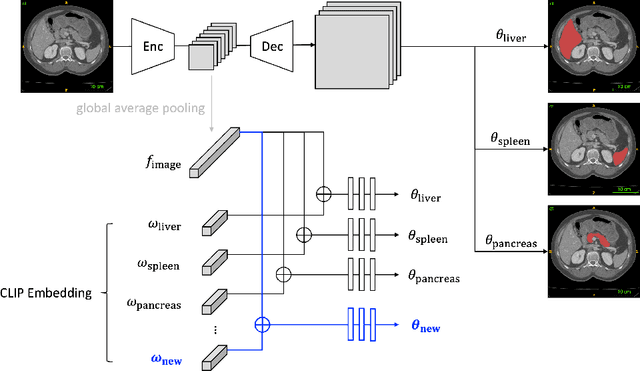

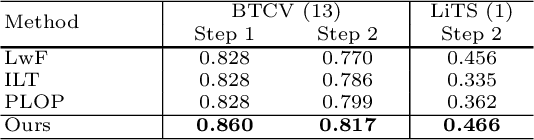
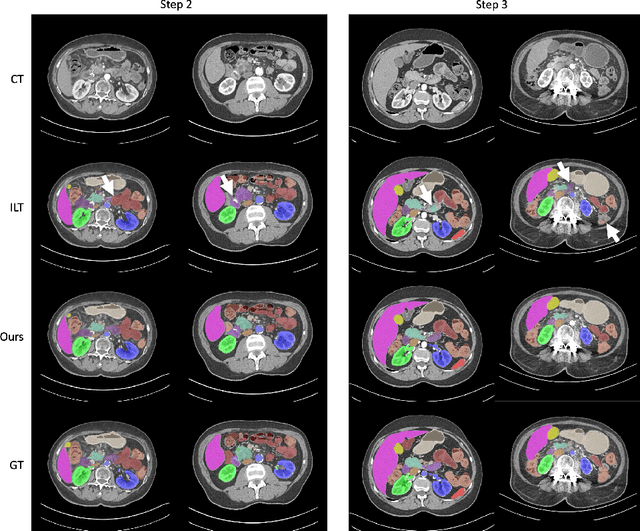
The ability to dynamically extend a model to new data and classes is critical for multiple organ and tumor segmentation. However, due to privacy regulations, accessing previous data and annotations can be problematic in the medical domain. This poses a significant barrier to preserving the high segmentation accuracy of the old classes when learning from new classes because of the catastrophic forgetting problem. In this paper, we first empirically demonstrate that simply using high-quality pseudo labels can fairly mitigate this problem in the setting of organ segmentation. Furthermore, we put forward an innovative architecture designed specifically for continuous organ and tumor segmentation, which incurs minimal computational overhead. Our proposed design involves replacing the conventional output layer with a suite of lightweight, class-specific heads, thereby offering the flexibility to accommodate newly emerging classes. These heads enable independent predictions for newly introduced and previously learned classes, effectively minimizing the impact of new classes on old ones during the course of continual learning. We further propose incorporating Contrastive Language-Image Pretraining (CLIP) embeddings into the organ-specific heads. These embeddings encapsulate the semantic information of each class, informed by extensive image-text co-training. The proposed method is evaluated on both in-house and public abdominal CT datasets under organ and tumor segmentation tasks. Empirical results suggest that the proposed design improves the segmentation performance of a baseline neural network on newly-introduced and previously-learned classes along the learning trajectory.
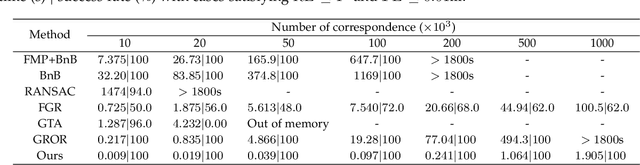
Efficient and Deterministic Search Strategy Based on Residual Projections for Point Cloud Registration
May 19, 2023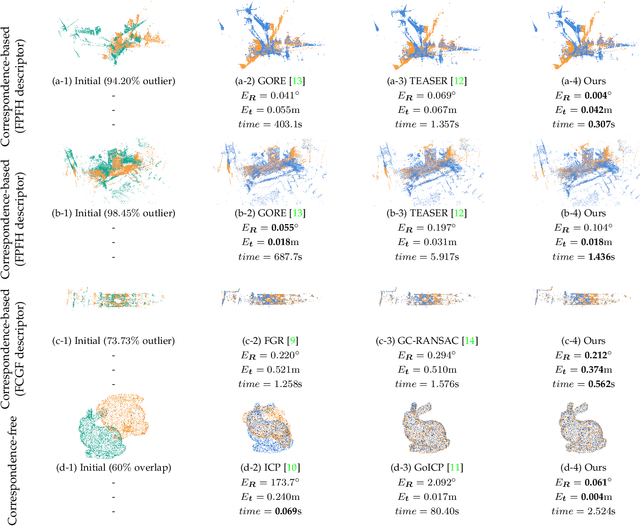

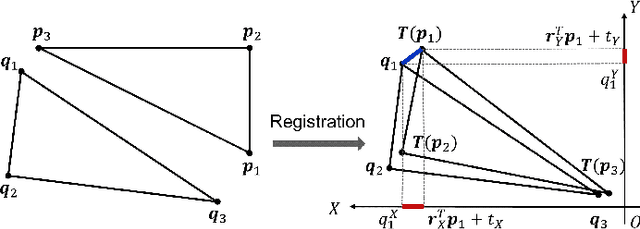
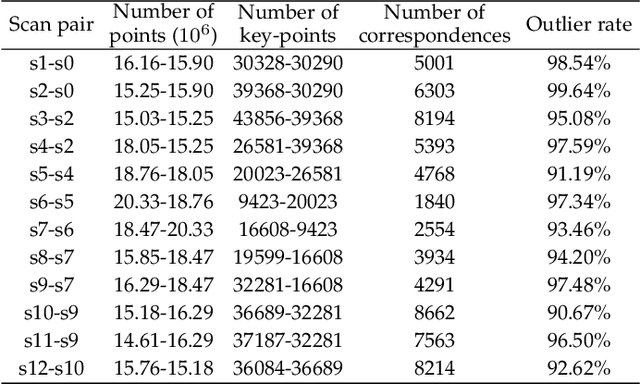
Estimating the rigid transformation between two LiDAR scans through putative 3D correspondences is a typical point cloud registration paradigm. Current 3D feature matching approaches commonly lead to numerous outlier correspondences, making outlier-robust registration techniques indispensable. Many recent studies have adopted the branch and bound (BnB) optimization framework to solve the correspondence-based point cloud registration problem globally and deterministically. Nonetheless, BnB-based methods are time-consuming to search the entire 6-dimensional parameter space, since their computational complexity is exponential to the dimension of the solution domain. In order to enhance algorithm efficiency, existing works attempt to decouple the 6 degrees of freedom (DOF) original problem into two 3-DOF sub-problems, thereby reducing the dimension of the parameter space. In contrast, our proposed approach introduces a novel pose decoupling strategy based on residual projections, effectively decomposing the raw problem into three 2-DOF rotation search sub-problems. Subsequently, we employ a novel BnB-based search method to solve these sub-problems, achieving efficient and deterministic registration. Furthermore, our method can be adapted to address the challenging problem of simultaneous pose and correspondence registration (SPCR). Through extensive experiments conducted on synthetic and real-world datasets, we demonstrate that our proposed method outperforms state-of-the-art methods in terms of efficiency, while simultaneously ensuring robustness.
PBNR: Prompt-based News Recommender System
Apr 16, 2023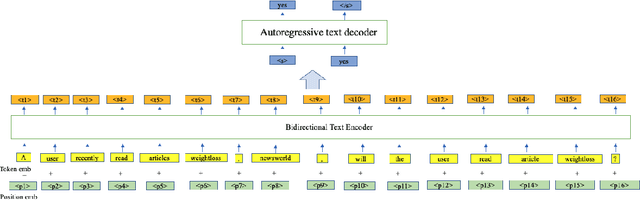


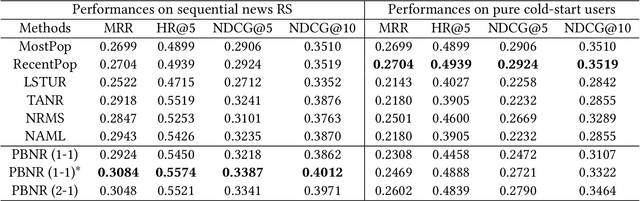
Online news platforms often use personalized news recommendation methods to help users discover articles that align with their interests. These methods typically predict a matching score between a user and a candidate article to reflect the user's preference for the article. Some previous works have used language model techniques, such as the attention mechanism, to capture users' interests based on their past behaviors, and to understand the content of articles. However, these existing model architectures require adjustments if additional information is taken into account. Pre-trained large language models, which can better capture word relationships and comprehend contexts, have seen a significant development in recent years, and these pre-trained models have the advantages of transfer learning and reducing the training time for downstream tasks. Meanwhile, prompt learning is a newly developed technique that leverages pre-trained language models by building task-specific guidance for output generations. To leverage textual information in news articles, this paper introduces the pre-trained large language model and prompt-learning to the community of news recommendation. The proposed model "prompt-based news recommendation" (PBNR) treats the personalized news recommendation as a text-to-text language task and designs personalized prompts to adapt to the pre-trained language model -- text-to-text transfer transformer (T5). Experimental studies using the Microsoft News dataset show that PBNR is capable of making accurate recommendations by taking into account various lengths of past behaviors of different users. PBNR can also easily adapt to new information without changing the model architecture and the training objective. Additionally, PBNR can make recommendations based on users' specific requirements, allowing human-computer interaction in the news recommendation field.
Discussion of Multiscale Fisher's Independence Test for Multivariate Dependence
Apr 26, 2022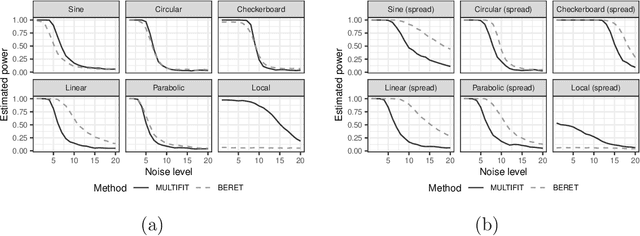

The multiscale Fisher's independence test (MULTIFIT hereafter) proposed by Gorsky & Ma (2022) is a novel method to test independence between two random vectors. By its design, this test is particularly useful in detecting local dependence. Moreover, by adopting a resampling-free approach, it can easily accommodate massive sample sizes. Another benefit of the proposed method is its ability to interpret the nature of dependency. We congratulate the authors, Shai Gorksy and Li Ma, for their very interesting and elegant work. In this comment, we would like to discuss a general framework unifying the MULTIFIT and other tests and compare it with the binary expansion randomized ensemble test (BERET hereafter) proposed by Lee et al. (In press). We also would like to contribute our thoughts on potential extensions of the method.
TransCamP: Graph Transformer for 6-DoF Camera Pose Estimation
May 28, 2021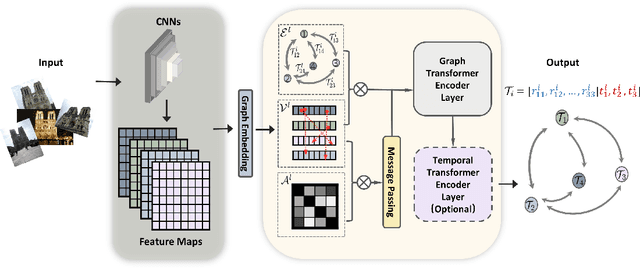
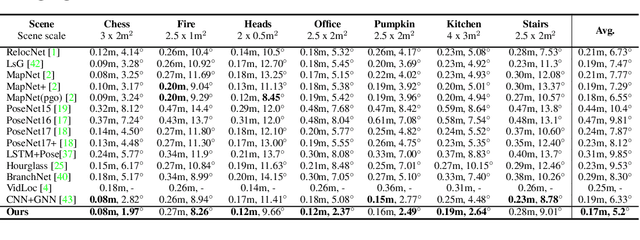
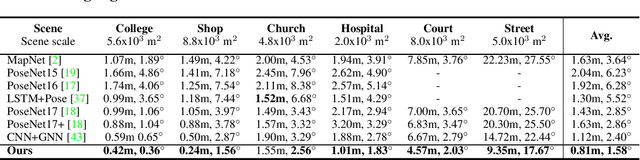
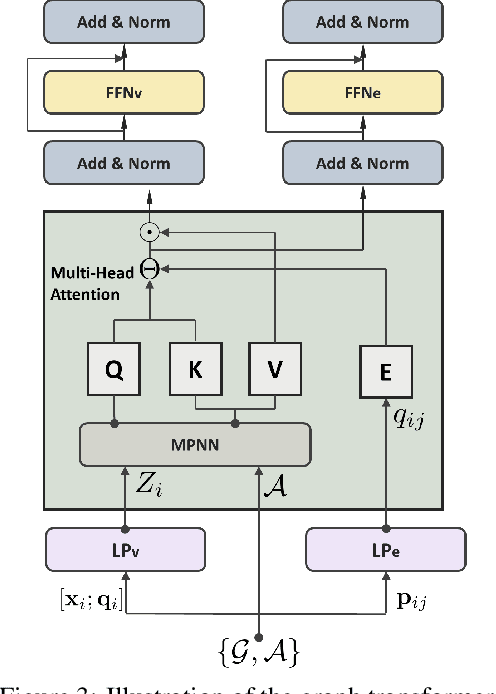
Camera pose estimation or camera relocalization is the centerpiece in numerous computer vision tasks such as visual odometry, structure from motion (SfM) and SLAM. In this paper we propose a neural network approach with a graph transformer backbone, namely TransCamP, to address the camera relocalization problem. In contrast with prior work where the pose regression is mainly guided by photometric consistency, TransCamP effectively fuses the image features, camera pose information and inter-frame relative camera motions into encoded graph attributes and is trained towards the graph consistency and accuracy instead, yielding significantly higher computational efficiency. By leveraging graph transformer layers with edge features and enabling tensorized adjacency matrix, TransCamP dynamically captures the global attention and thus endows the pose graph with evolving structures to achieve improved robustness and accuracy. In addition, optional temporal transformer layers actively enhance the spatiotemporal inter-frame relation for sequential inputs. Evaluation of the proposed network on various public benchmarks demonstrates that TransCamP outperforms state-of-the-art approaches.