 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeihu Zhang
S-NeRF++: Autonomous Driving Simulation via Neural Reconstruction and Generation
Feb 03, 2024
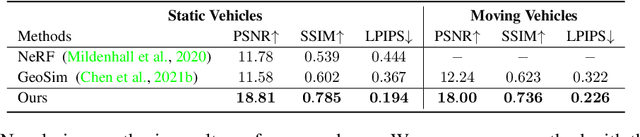
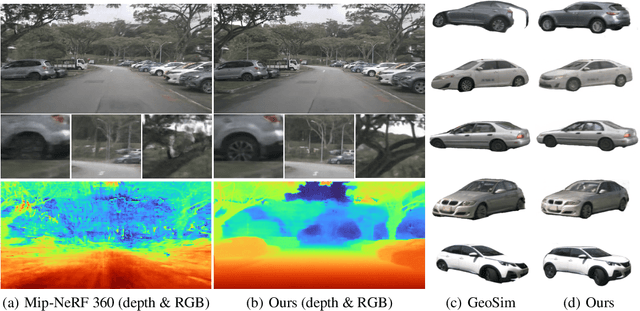
Autonomous driving simulation system plays a crucial role in enhancing self-driving data and simulating complex and rare traffic scenarios, ensuring navigation safety. However, traditional simulation systems, which often heavily rely on manual modeling and 2D image editing, struggled with scaling to extensive scenes and generating realistic simulation data. In this study, we present S-NeRF++, an innovative autonomous driving simulation system based on neural reconstruction. Trained on widely-used self-driving datasets such as nuScenes and Waymo, S-NeRF++ can generate a large number of realistic street scenes and foreground objects with high rendering quality as well as offering considerable flexibility in manipulation and simulation. Specifically, S-NeRF++ is an enhanced neural radiance field for synthesizing large-scale scenes and moving vehicles, with improved scene parameterization and camera pose learning. The system effectively utilizes noisy and sparse LiDAR data to refine training and address depth outliers, ensuring high quality reconstruction and novel-view rendering. It also provides a diverse foreground asset bank through reconstructing and generating different foreground vehicles to support comprehensive scenario creation. Moreover, we have developed an advanced foreground-background fusion pipeline that skillfully integrates illumination and shadow effects, further enhancing the realism of our simulations. With the high-quality simulated data provided by our S-NeRF++, we found the perception methods enjoy performance boost on several autonomous driving downstream tasks, which further demonstrate the effectiveness of our proposed simulator.
Transformation Decoupling Strategy based on Screw Theory for Deterministic Point Cloud Registration with Gravity Prior
Nov 02, 2023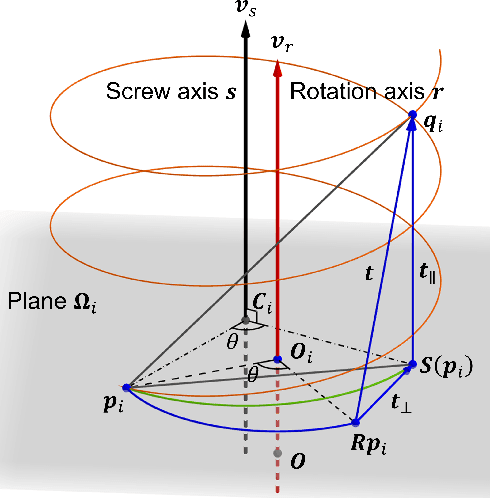
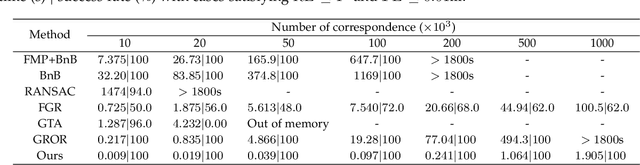
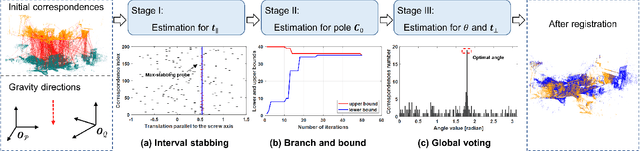

Point cloud registration is challenging in the presence of heavy outlier correspondences. This paper focuses on addressing the robust correspondence-based registration problem with gravity prior that often arises in practice. The gravity directions are typically obtained by inertial measurement units (IMUs) and can reduce the degree of freedom (DOF) of rotation from 3 to 1. We propose a novel transformation decoupling strategy by leveraging screw theory. This strategy decomposes the original 4-DOF problem into three sub-problems with 1-DOF, 2-DOF, and 1-DOF, respectively, thereby enhancing the computation efficiency. Specifically, the first 1-DOF represents the translation along the rotation axis and we propose an interval stabbing-based method to solve it. The second 2-DOF represents the pole which is an auxiliary variable in screw theory and we utilize a branch-and-bound method to solve it. The last 1-DOF represents the rotation angle and we propose a global voting method for its estimation. The proposed method sequentially solves three consensus maximization sub-problems, leading to efficient and deterministic registration. In particular, it can even handle the correspondence-free registration problem due to its significant robustness. Extensive experiments on both synthetic and real-world datasets demonstrate that our method is more efficient and robust than state-of-the-art methods, even when dealing with outlier rates exceeding 99%.
Efficient and Deterministic Search Strategy Based on Residual Projections for Point Cloud Registration
May 19, 2023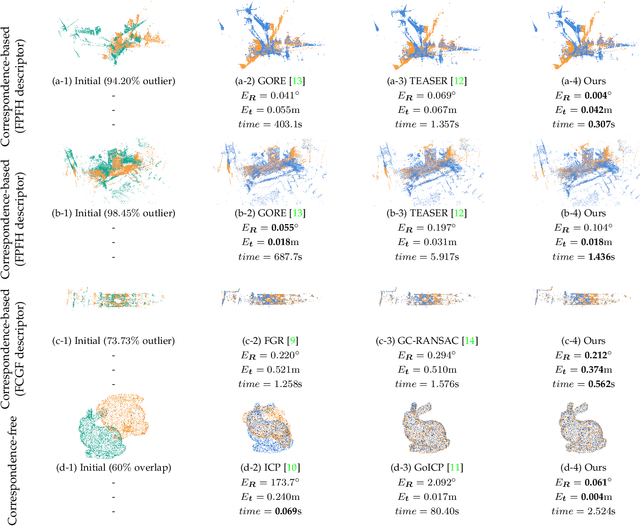

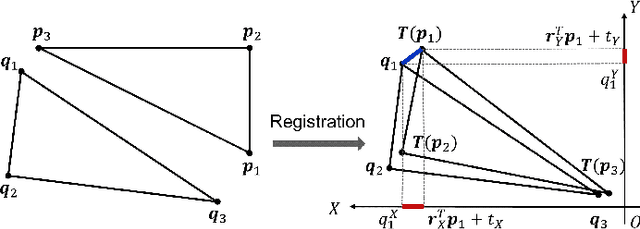
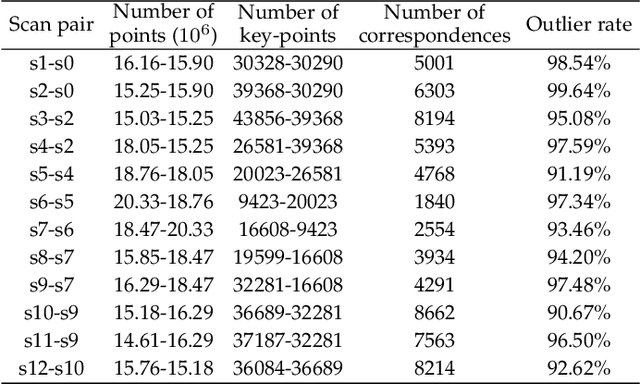
Estimating the rigid transformation between two LiDAR scans through putative 3D correspondences is a typical point cloud registration paradigm. Current 3D feature matching approaches commonly lead to numerous outlier correspondences, making outlier-robust registration techniques indispensable. Many recent studies have adopted the branch and bound (BnB) optimization framework to solve the correspondence-based point cloud registration problem globally and deterministically. Nonetheless, BnB-based methods are time-consuming to search the entire 6-dimensional parameter space, since their computational complexity is exponential to the dimension of the solution domain. In order to enhance algorithm efficiency, existing works attempt to decouple the 6 degrees of freedom (DOF) original problem into two 3-DOF sub-problems, thereby reducing the dimension of the parameter space. In contrast, our proposed approach introduces a novel pose decoupling strategy based on residual projections, effectively decomposing the raw problem into three 2-DOF rotation search sub-problems. Subsequently, we employ a novel BnB-based search method to solve these sub-problems, achieving efficient and deterministic registration. Furthermore, our method can be adapted to address the challenging problem of simultaneous pose and correspondence registration (SPCR). Through extensive experiments conducted on synthetic and real-world datasets, we demonstrate that our proposed method outperforms state-of-the-art methods in terms of efficiency, while simultaneously ensuring robustness.
NeRF-LiDAR: Generating Realistic LiDAR Point Clouds with Neural Radiance Fields
Apr 28, 2023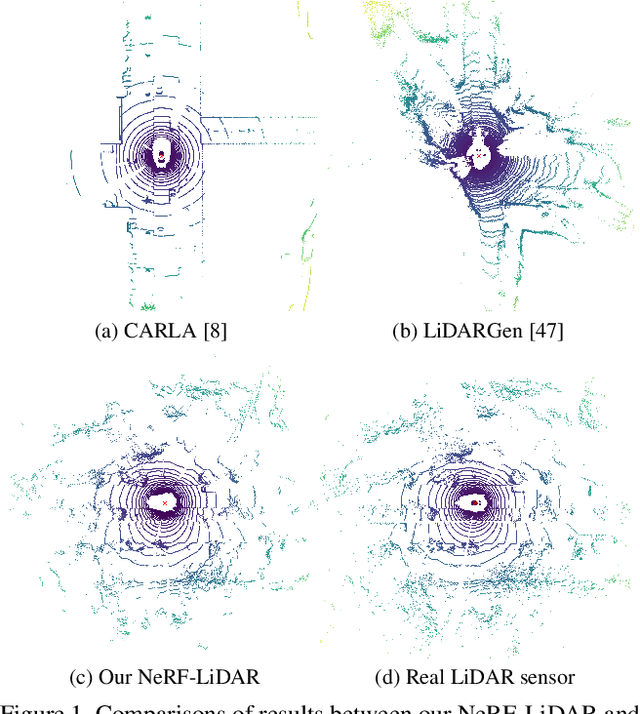
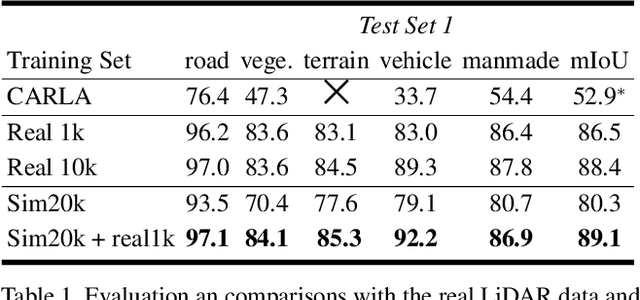
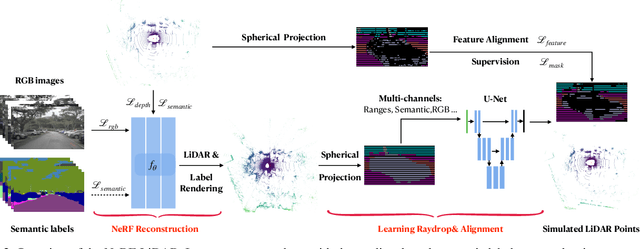
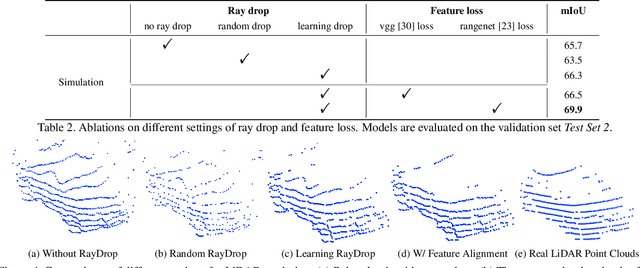
Labeling LiDAR point clouds for training autonomous driving is extremely expensive and difficult. LiDAR simulation aims at generating realistic LiDAR data with labels for training and verifying self-driving algorithms more efficiently. Recently, Neural Radiance Fields (NeRF) have been proposed for novel view synthesis using implicit reconstruction of 3D scenes. Inspired by this, we present NeRF-LIDAR, a novel LiDAR simulation method that leverages real-world information to generate realistic LIDAR point clouds. Different from existing LiDAR simulators, we use real images and point cloud data collected by self-driving cars to learn the 3D scene representation, point cloud generation and label rendering. We verify the effectiveness of our NeRF-LiDAR by training different 3D segmentation models on the generated LiDAR point clouds. It reveals that the trained models are able to achieve similar accuracy when compared with the same model trained on the real LiDAR data. Besides, the generated data is capable of boosting the accuracy through pre-training which helps reduce the requirements of the real labeled data.
Single-view Neural Radiance Fields with Depth Teacher
Mar 17, 2023
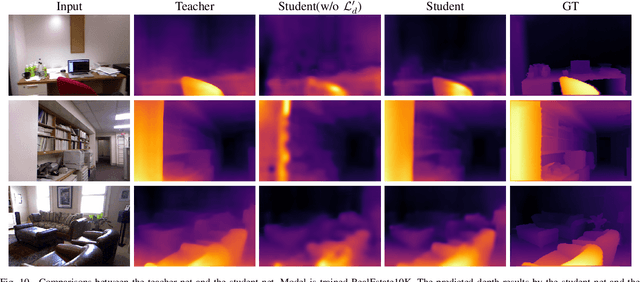
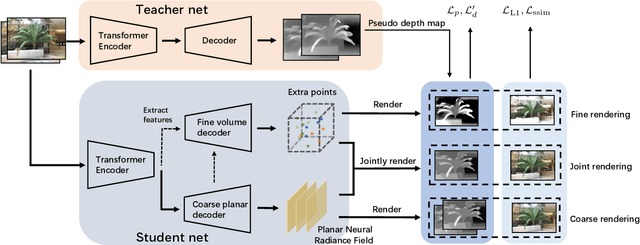
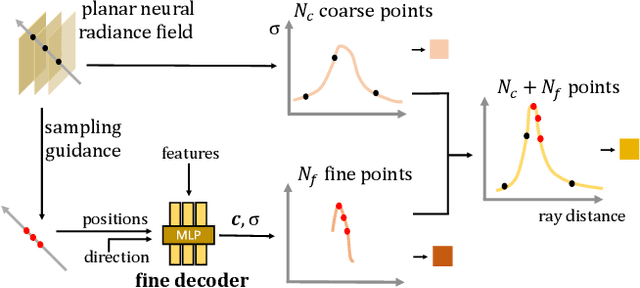
Neural Radiance Fields (NeRF) have been proposed for photorealistic novel view rendering. However, it requires many different views of one scene for training. Moreover, it has poor generalizations to new scenes and requires retraining or fine-tuning on each scene. In this paper, we develop a new NeRF model for novel view synthesis using only a single image as input. We propose to combine the (coarse) planar rendering and the (fine) volume rendering to achieve higher rendering quality and better generalizations. We also design a depth teacher net that predicts dense pseudo depth maps to supervise the joint rendering mechanism and boost the learning of consistent 3D geometry. We evaluate our method on three challenging datasets. It outperforms state-of-the-art single-view NeRFs by achieving 5$\sim$20\% improvements in PSNR and reducing 20$\sim$50\% of the errors in the depth rendering. It also shows excellent generalization abilities to unseen data without the need to fine-tune on each new scene.
S-NeRF: Neural Radiance Fields for Street Views
Mar 01, 2023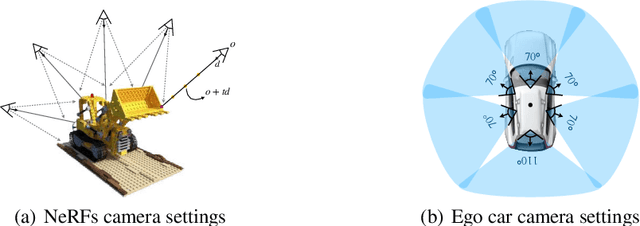
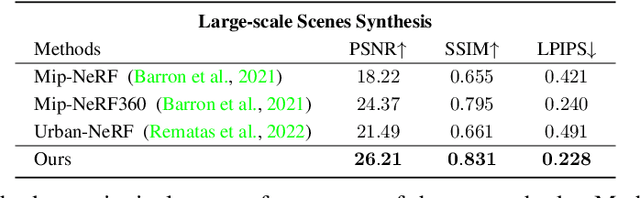
Neural Radiance Fields (NeRFs) aim to synthesize novel views of objects and scenes, given the object-centric camera views with large overlaps. However, we conjugate that this paradigm does not fit the nature of the street views that are collected by many self-driving cars from the large-scale unbounded scenes. Also, the onboard cameras perceive scenes without much overlapping. Thus, existing NeRFs often produce blurs, 'floaters' and other artifacts on street-view synthesis. In this paper, we propose a new street-view NeRF (S-NeRF) that considers novel view synthesis of both the large-scale background scenes and the foreground moving vehicles jointly. Specifically, we improve the scene parameterization function and the camera poses for learning better neural representations from street views. We also use the the noisy and sparse LiDAR points to boost the training and learn a robust geometry and reprojection based confidence to address the depth outliers. Moreover, we extend our S-NeRF for reconstructing moving vehicles that is impracticable for conventional NeRFs. Thorough experiments on the large-scale driving datasets (e.g., nuScenes and Waymo) demonstrate that our method beats the state-of-the-art rivals by reducing 7% to 40% of the mean-squared error in the street-view synthesis and a 45% PSNR gain for the moving vehicles rendering.
Unsupervised Contrastive Domain Adaptation for Semantic Segmentation
Apr 18, 2022
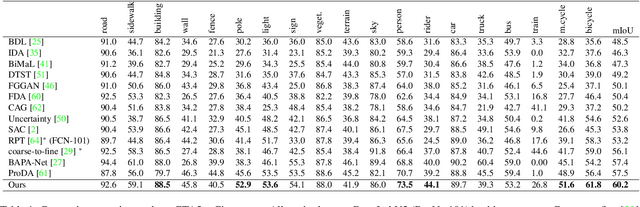
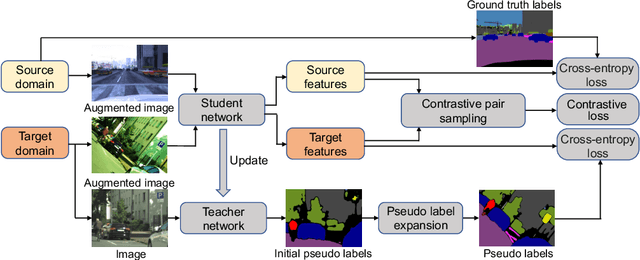
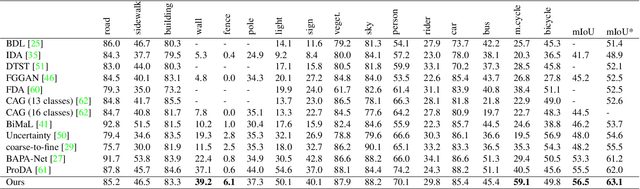
Semantic segmentation models struggle to generalize in the presence of domain shift. In this paper, we introduce contrastive learning for feature alignment in cross-domain adaptation. We assemble both in-domain contrastive pairs and cross-domain contrastive pairs to learn discriminative features that align across domains. Based on the resulting well-aligned feature representations we introduce a label expansion approach that is able to discover samples from hard classes during the adaptation process to further boost performance. The proposed approach consistently outperforms state-of-the-art methods for domain adaptation. It achieves 60.2% mIoU on the Cityscapes dataset when training on the synthetic GTA5 dataset together with unlabeled Cityscapes images.
Domain-invariant Stereo Matching Networks
Nov 29, 2019
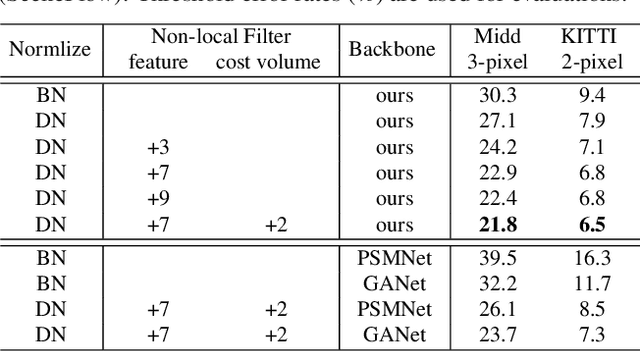
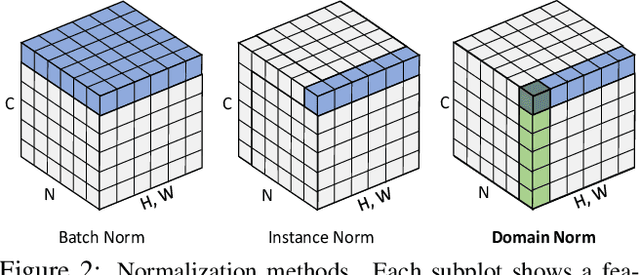
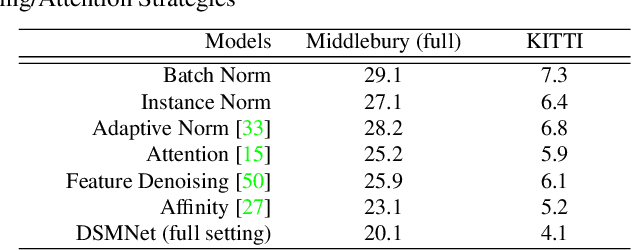
State-of-the-art stereo matching networks have difficulties in generalizing to new unseen environments due to significant domain differences, such as color, illumination, contrast, and texture. In this paper, we aim at designing a domain-invariant stereo matching network (DSMNet) that generalizes well to unseen scenes. To achieve this goal, we propose i) a novel "domain normalization" approach that regularizes the distribution of learned representations to allow them to be invariant to domain differences, and ii) a trainable non-local graph-based filter for extracting robust structural and geometric representations that can further enhance domain-invariant generalizations. When trained on synthetic data and generalized to real test sets, our model performs significantly better than all state-of-the-art models. It even outperforms some deep learning models (e.g. MC-CNN) fine-tuned with test-domain data.
GA-Net: Guided Aggregation Net for End-to-end Stereo Matching
Apr 13, 2019
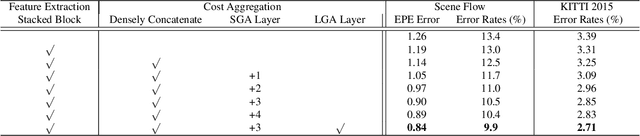
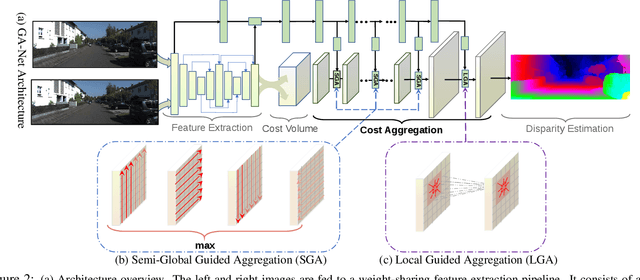
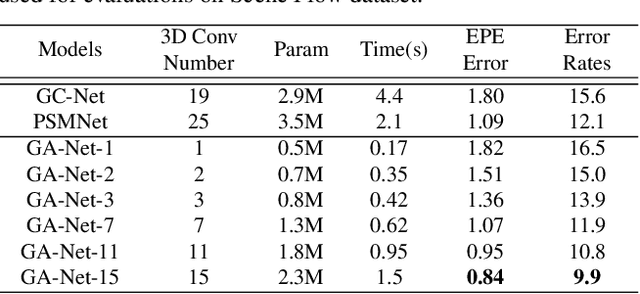
In the stereo matching task, matching cost aggregation is crucial in both traditional methods and deep neural network models in order to accurately estimate disparities. We propose two novel neural net layers, aimed at capturing local and the whole-image cost dependencies respectively. The first is a semi-global aggregation layer which is a differentiable approximation of the semi-global matching, the second is the local guided aggregation layer which follows a traditional cost filtering strategy to refine thin structures. These two layers can be used to replace the widely used 3D convolutional layer which is computationally costly and memory-consuming as it has cubic computational/memory complexity. In the experiments, we show that nets with a two-layer guided aggregation block easily outperform the state-of-the-art GC-Net which has nineteen 3D convolutional layers. We also train a deep guided aggregation network (GA-Net) which gets better accuracies than state-of-the-art methods on both Scene Flow dataset and KITTI benchmarks.
Hypergraph Convolution and Hypergraph Attention
Jan 23, 2019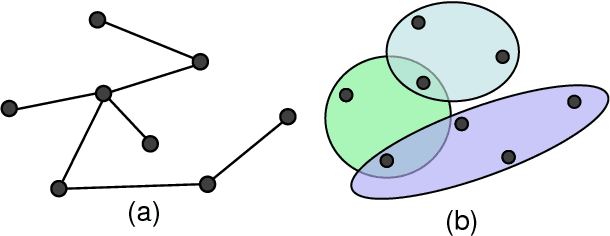
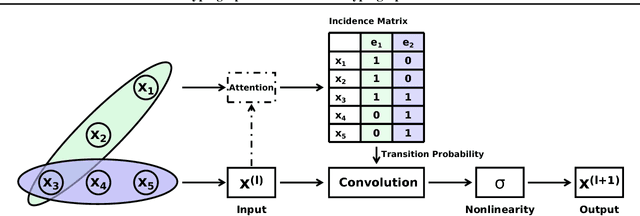
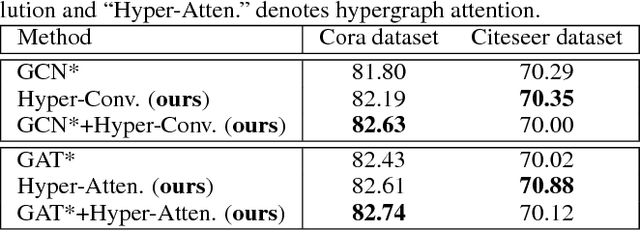
Recently, graph neural networks have attracted great attention and achieved prominent performance in various research fields. Most of those algorithms have assumed pairwise relationships of objects of interest. However, in many real applications, the relationships between objects are in higher-order, beyond a pairwise formulation. To efficiently learn deep embeddings on the high-order graph-structured data, we introduce two end-to-end trainable operators to the family of graph neural networks, i.e., hypergraph convolution and hypergraph attention. Whilst hypergraph convolution defines the basic formulation of performing convolution on a hypergraph, hypergraph attention further enhances the capacity of representation learning by leveraging an attention module. With the two operators, a graph neural network is readily extended to a more flexible model and applied to diverse applications where non-pairwise relationships are observed. Extensive experimental results with semi-supervised node classification demonstrate the effectiveness of hypergraph convolution and hypergraph attention.