 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBingbing Nie
Decision-Making under On-Ramp merge Scenarios by Distributional Soft Actor-Critic Algorithm
Mar 08, 2021
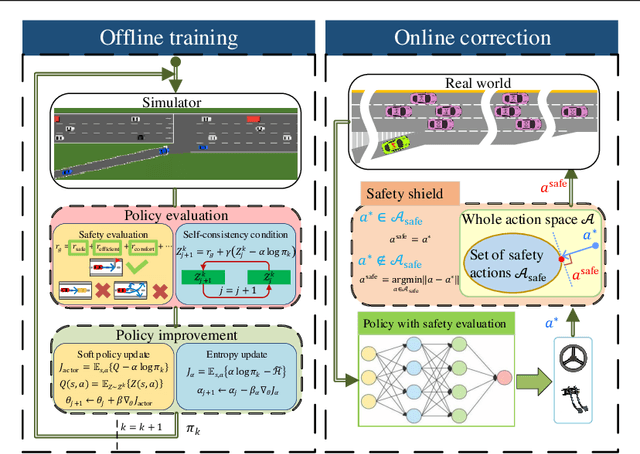
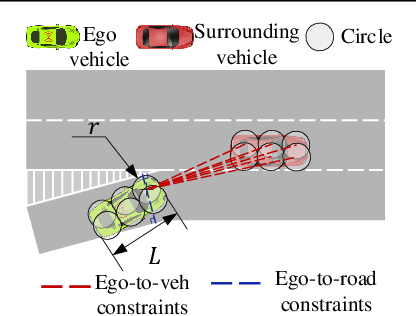
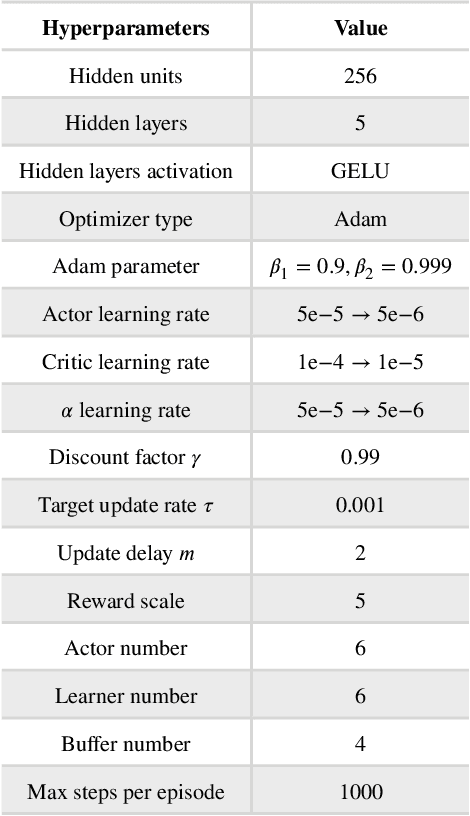
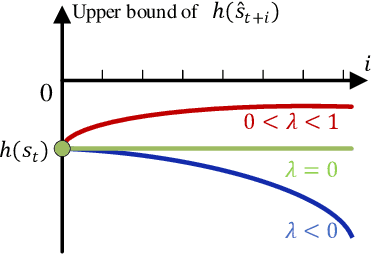
Merging into the highway from the on-ramp is an essential scenario for automated driving. The decision-making under the scenario needs to balance the safety and efficiency performance to optimize a long-term objective, which is challenging due to the dynamic, stochastic, and adversarial characteristics. The Rule-based methods often lead to conservative driving on this task while the learning-based methods have difficulties meeting the safety requirements. In this paper, we propose an RL-based end-to-end decision-making method under a framework of offline training and online correction, called the Shielded Distributional Soft Actor-critic (SDSAC). The SDSAC adopts the policy evaluation with safety consideration and a safety shield parameterized with the barrier function in its offline training and online correction, respectively. These two measures support each other for better safety while not damaging the efficiency performance severely. We verify the SDSAC on an on-ramp merge scenario in simulation. The results show that the SDSAC has the best safety performance compared to baseline algorithms and achieves efficient driving simultaneously.
Mixed Reinforcement Learning with Additive Stochastic Uncertainty
Feb 28, 2020



Reinforcement learning (RL) methods often rely on massive exploration data to search optimal policies, and suffer from poor sampling efficiency. This paper presents a mixed reinforcement learning (mixed RL) algorithm by simultaneously using dual representations of environmental dynamics to search the optimal policy with the purpose of improving both learning accuracy and training speed. The dual representations indicate the environmental model and the state-action data: the former can accelerate the learning process of RL, while its inherent model uncertainty generally leads to worse policy accuracy than the latter, which comes from direct measurements of states and actions. In the framework design of the mixed RL, the compensation of the additive stochastic model uncertainty is embedded inside the policy iteration RL framework by using explored state-action data via iterative Bayesian estimator (IBE). The optimal policy is then computed in an iterative way by alternating between policy evaluation (PEV) and policy improvement (PIM). The convergence of the mixed RL is proved using the Bellman's principle of optimality, and the recursive stability of the generated policy is proved via the Lyapunov's direct method. The effectiveness of the mixed RL is demonstrated by a typical optimal control problem of stochastic non-affine nonlinear systems (i.e., double lane change task with an automated vehicle).