 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShengbo Eben Li
Convolutional Bayesian Filtering
Mar 30, 2024
Bayesian filtering serves as the mainstream framework of state estimation in dynamic systems. Its standard version utilizes total probability rule and Bayes' law alternatively, where how to define and compute conditional probability is critical to state distribution inference. Previously, the conditional probability is assumed to be exactly known, which represents a measure of the occurrence probability of one event, given the second event. In this paper, we find that by adding an additional event that stipulates an inequality condition, we can transform the conditional probability into a special integration that is analogous to convolution. Based on this transformation, we show that both transition probability and output probability can be generalized to convolutional forms, resulting in a more general filtering framework that we call convolutional Bayesian filtering. This new framework encompasses standard Bayesian filtering as a special case when the distance metric of the inequality condition is selected as Dirac delta function. It also allows for a more nuanced consideration of model mismatch by choosing different types of inequality conditions. For instance, when the distance metric is defined in a distributional sense, the transition probability and output probability can be approximated by simply rescaling them into fractional powers. Under this framework, a robust version of Kalman filter can be constructed by only altering the noise covariance matrix, while maintaining the conjugate nature of Gaussian distributions. Finally, we exemplify the effectiveness of our approach by reshaping classic filtering algorithms into convolutional versions, including Kalman filter, extended Kalman filter, unscented Kalman filter and particle filter.
Policy Bifurcation in Safe Reinforcement Learning
Mar 28, 2024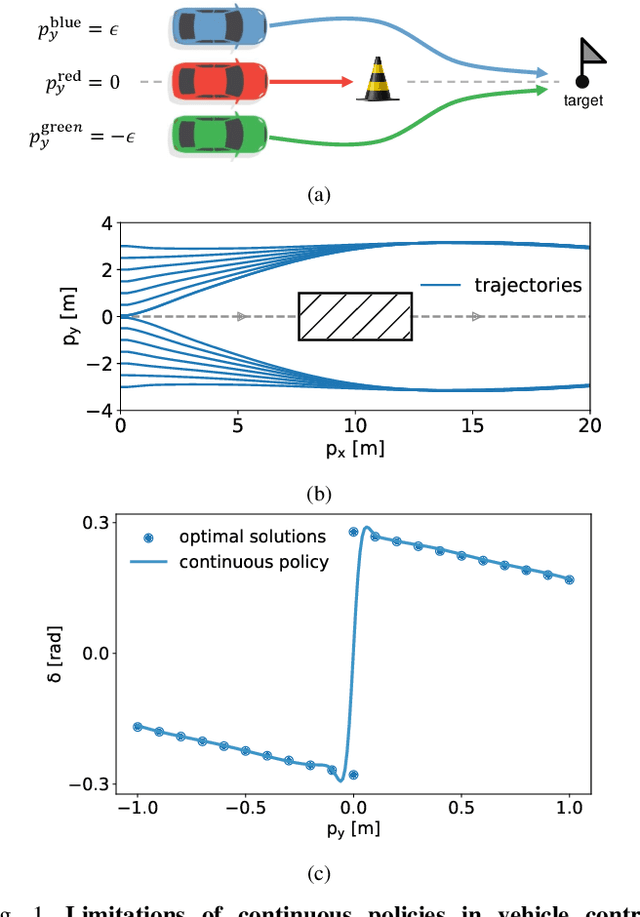
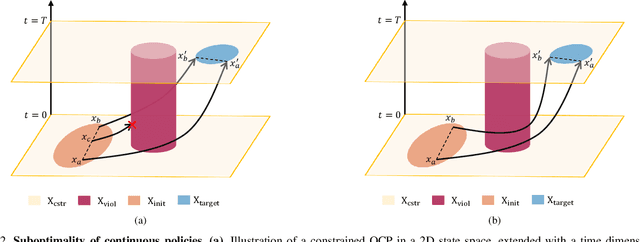
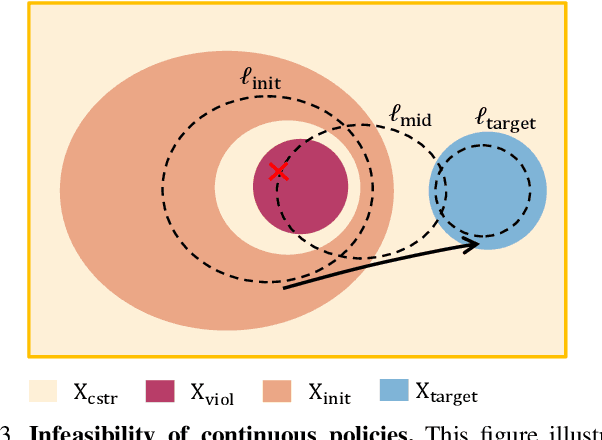
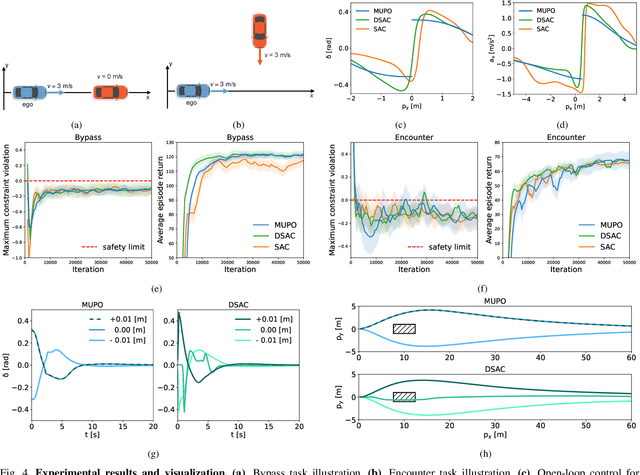
Safe reinforcement learning (RL) offers advanced solutions to constrained optimal control problems. Existing studies in safe RL implicitly assume continuity in policy functions, where policies map states to actions in a smooth, uninterrupted manner; however, our research finds that in some scenarios, the feasible policy should be discontinuous or multi-valued, interpolating between discontinuous local optima can inevitably lead to constraint violations. We are the first to identify the generating mechanism of such a phenomenon, and employ topological analysis to rigorously prove the existence of policy bifurcation in safe RL, which corresponds to the contractibility of the reachable tuple. Our theorem reveals that in scenarios where the obstacle-free state space is non-simply connected, a feasible policy is required to be bifurcated, meaning its output action needs to change abruptly in response to the varying state. To train such a bifurcated policy, we propose a safe RL algorithm called multimodal policy optimization (MUPO), which utilizes a Gaussian mixture distribution as the policy output. The bifurcated behavior can be achieved by selecting the Gaussian component with the highest mixing coefficient. Besides, MUPO also integrates spectral normalization and forward KL divergence to enhance the policy's capability of exploring different modes. Experiments with vehicle control tasks show that our algorithm successfully learns the bifurcated policy and ensures satisfying safety, while a continuous policy suffers from inevitable constraint violations.
Canonical Form of Datatic Description in Control Systems
Mar 04, 2024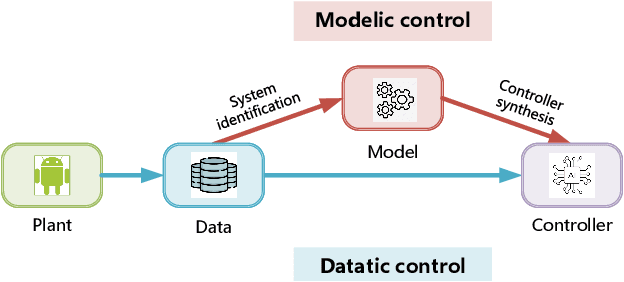
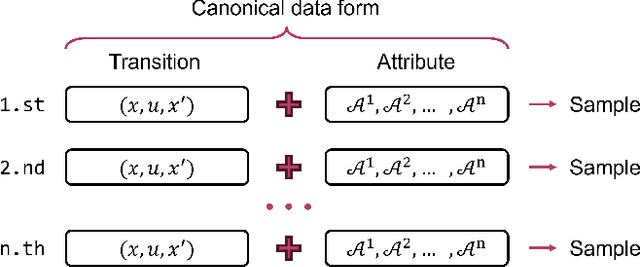
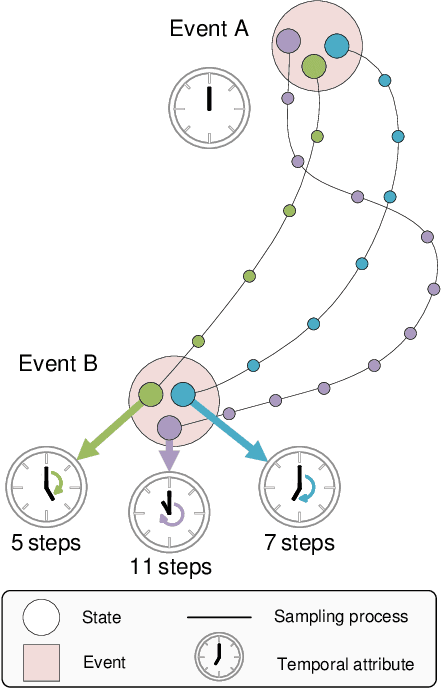
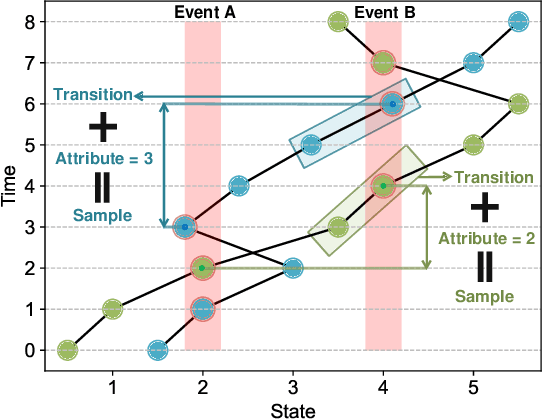
The design of feedback controllers is undergoing a paradigm shift from modelic (i.e., model-driven) control to datatic (i.e., data-driven) control. Canonical form of state space model is an important concept in modelic control systems, exemplified by Jordan form, controllable form and observable form, whose purpose is to facilitate system analysis and controller synthesis. In the realm of datatic control, there is a notable absence in the standardization of data-based system representation. This paper for the first time introduces the concept of canonical data form for the purpose of achieving more effective design of datatic controllers. In a control system, the data sample in canonical form consists of a transition component and an attribute component. The former encapsulates the plant dynamics at the sampling time independently, which is a tuple containing three elements: a state, an action and their corresponding next state. The latter describes one or some artificial characteristics of the current sample, whose calculation must be performed in an online manner. The attribute of each sample must adhere to two requirements: (1) causality, ensuring independence from any future samples; and (2) locality, allowing dependence on historical samples but constrained to a finite neighboring set. The purpose of adding attribute is to offer some kinds of benefits for controller design in terms of effectiveness and efficiency. To provide a more close-up illustration, we present two canonical data forms: temporal form and spatial form, and demonstrate their advantages in reducing instability and enhancing training efficiency in two datatic control systems.
A Cognitive-Based Trajectory Prediction Approach for Autonomous Driving
Feb 29, 2024In autonomous vehicle (AV) technology, the ability to accurately predict the movements of surrounding vehicles is paramount for ensuring safety and operational efficiency. Incorporating human decision-making insights enables AVs to more effectively anticipate the potential actions of other vehicles, significantly improving prediction accuracy and responsiveness in dynamic environments. This paper introduces the Human-Like Trajectory Prediction (HLTP) model, which adopts a teacher-student knowledge distillation framework inspired by human cognitive processes. The HLTP model incorporates a sophisticated teacher-student knowledge distillation framework. The "teacher" model, equipped with an adaptive visual sector, mimics the visual processing of the human brain, particularly the functions of the occipital and temporal lobes. The "student" model focuses on real-time interaction and decision-making, drawing parallels to prefrontal and parietal cortex functions. This approach allows for dynamic adaptation to changing driving scenarios, capturing essential perceptual cues for accurate prediction. Evaluated using the Macao Connected and Autonomous Driving (MoCAD) dataset, along with the NGSIM and HighD benchmarks, HLTP demonstrates superior performance compared to existing models, particularly in challenging environments with incomplete data. The project page is available at Github.
Safe Offline Reinforcement Learning with Feasibility-Guided Diffusion Model
Jan 19, 2024Safe offline RL is a promising way to bypass risky online interactions towards safe policy learning. Most existing methods only enforce soft constraints, i.e., constraining safety violations in expectation below thresholds predetermined. This can lead to potentially unsafe outcomes, thus unacceptable in safety-critical scenarios. An alternative is to enforce the hard constraint of zero violation. However, this can be challenging in offline setting, as it needs to strike the right balance among three highly intricate and correlated aspects: safety constraint satisfaction, reward maximization, and behavior regularization imposed by offline datasets. Interestingly, we discover that via reachability analysis of safe-control theory, the hard safety constraint can be equivalently translated to identifying the largest feasible region given the offline dataset. This seamlessly converts the original trilogy problem to a feasibility-dependent objective, i.e., maximizing reward value within the feasible region while minimizing safety risks in the infeasible region. Inspired by these, we propose FISOR (FeasIbility-guided Safe Offline RL), which allows safety constraint adherence, reward maximization, and offline policy learning to be realized via three decoupled processes, while offering strong safety performance and stability. In FISOR, the optimal policy for the translated optimization problem can be derived in a special form of weighted behavior cloning. Thus, we propose a novel energy-guided diffusion model that does not require training a complicated time-dependent classifier to extract the policy, greatly simplifying the training. We compare FISOR against baselines on DSRL benchmark for safe offline RL. Evaluation results show that FISOR is the only method that can guarantee safety satisfaction in all tasks, while achieving top returns in most tasks.
BAT: Behavior-Aware Human-Like Trajectory Prediction for Autonomous Driving
Dec 15, 2023The ability to accurately predict the trajectory of surrounding vehicles is a critical hurdle to overcome on the journey to fully autonomous vehicles. To address this challenge, we pioneer a novel behavior-aware trajectory prediction model (BAT) that incorporates insights and findings from traffic psychology, human behavior, and decision-making. Our model consists of behavior-aware, interaction-aware, priority-aware, and position-aware modules that perceive and understand the underlying interactions and account for uncertainty and variability in prediction, enabling higher-level learning and flexibility without rigid categorization of driving behavior. Importantly, this approach eliminates the need for manual labeling in the training process and addresses the challenges of non-continuous behavior labeling and the selection of appropriate time windows. We evaluate BAT's performance across the Next Generation Simulation (NGSIM), Highway Drone (HighD), Roundabout Drone (RounD), and Macao Connected Autonomous Driving (MoCAD) datasets, showcasing its superiority over prevailing state-of-the-art (SOTA) benchmarks in terms of prediction accuracy and efficiency. Remarkably, even when trained on reduced portions of the training data (25%), our model outperforms most of the baselines, demonstrating its robustness and efficiency in predicting vehicle trajectories, and the potential to reduce the amount of data required to train autonomous vehicles, especially in corner cases. In conclusion, the behavior-aware model represents a significant advancement in the development of autonomous vehicles capable of predicting trajectories with the same level of proficiency as human drivers. The project page is available at https://github.com/Petrichor625/BATraj-Behavior-aware-Model.
Integrated Drill Boom Hole-Seeking Control via Reinforcement Learning
Dec 04, 2023Intelligent drill boom hole-seeking is a promising technology for enhancing drilling efficiency, mitigating potential safety hazards, and relieving human operators. Most existing intelligent drill boom control methods rely on a hierarchical control framework based on inverse kinematics. However, these methods are generally time-consuming due to the computational complexity of inverse kinematics and the inefficiency of the sequential execution of multiple joints. To tackle these challenges, this study proposes an integrated drill boom control method based on Reinforcement Learning (RL). We develop an integrated drill boom control framework that utilizes a parameterized policy to directly generate control inputs for all joints at each time step, taking advantage of joint posture and target hole information. By formulating the hole-seeking task as a Markov decision process, contemporary mainstream RL algorithms can be directly employed to learn a hole-seeking policy, thus eliminating the need for inverse kinematics solutions and promoting cooperative multi-joint control. To enhance the drilling accuracy throughout the entire drilling process, we devise a state representation that combines Denavit-Hartenberg joint information and preview hole-seeking discrepancy data. Simulation results show that the proposed method significantly outperforms traditional methods in terms of hole-seeking accuracy and time efficiency.
Training Multi-layer Neural Networks on Ising Machine
Nov 06, 2023As a dedicated quantum device, Ising machines could solve large-scale binary optimization problems in milliseconds. There is emerging interest in utilizing Ising machines to train feedforward neural networks due to the prosperity of generative artificial intelligence. However, existing methods can only train single-layer feedforward networks because of the complex nonlinear network topology. This paper proposes an Ising learning algorithm to train quantized neural network (QNN), by incorporating two essential techinques, namely binary representation of topological network and order reduction of loss function. As far as we know, this is the first algorithm to train multi-layer feedforward networks on Ising machines, providing an alternative to gradient-based backpropagation. Firstly, training QNN is formulated as a quadratic constrained binary optimization (QCBO) problem by representing neuron connection and activation function as equality constraints. All quantized variables are encoded by binary bits based on binary encoding protocol. Secondly, QCBO is converted to a quadratic unconstrained binary optimization (QUBO) problem, that can be efficiently solved on Ising machines. The conversion leverages both penalty function and Rosenberg order reduction, who together eliminate equality constraints and reduce high-order loss function into a quadratic one. With some assumptions, theoretical analysis shows the space complexity of our algorithm is $\mathcal{O}(H^2L + HLN\log H)$, quantifying the required number of Ising spins. Finally, the algorithm effectiveness is validated with a simulated Ising machine on MNIST dataset. After annealing 700 ms, the classification accuracy achieves 98.3%. Among 100 runs, the success probability of finding the optimal solution is 72%. Along with the increasing number of spins on Ising machine, our algorithm has the potential to train deeper neural networks.
Optimization Landscape of Policy Gradient Methods for Discrete-time Static Output Feedback
Oct 29, 2023In recent times, significant advancements have been made in delving into the optimization landscape of policy gradient methods for achieving optimal control in linear time-invariant (LTI) systems. Compared with state-feedback control, output-feedback control is more prevalent since the underlying state of the system may not be fully observed in many practical settings. This paper analyzes the optimization landscape inherent to policy gradient methods when applied to static output feedback (SOF) control in discrete-time LTI systems subject to quadratic cost. We begin by establishing crucial properties of the SOF cost, encompassing coercivity, L-smoothness, and M-Lipschitz continuous Hessian. Despite the absence of convexity, we leverage these properties to derive novel findings regarding convergence (and nearly dimension-free rate) to stationary points for three policy gradient methods, including the vanilla policy gradient method, the natural policy gradient method, and the Gauss-Newton method. Moreover, we provide proof that the vanilla policy gradient method exhibits linear convergence towards local minima when initialized near such minima. The paper concludes by presenting numerical examples that validate our theoretical findings. These results not only characterize the performance of gradient descent for optimizing the SOF problem but also provide insights into the effectiveness of general policy gradient methods within the realm of reinforcement learning.