 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChengzhong Xu
Ranking-based Client Selection with Imitation Learning for Efficient Federated Learning
May 07, 2024
Federated Learning (FL) enables multiple devices to collaboratively train a shared model while ensuring data privacy. The selection of participating devices in each training round critically affects both the model performance and training efficiency, especially given the vast heterogeneity in training capabilities and data distribution across devices. To address these challenges, we introduce a novel device selection solution called FedRank, which is an end-to-end, ranking-based approach that is pre-trained by imitation learning against state-of-the-art analytical approaches. It not only considers data and system heterogeneity at runtime but also adaptively and efficiently chooses the most suitable clients for model training. Specifically, FedRank views client selection in FL as a ranking problem and employs a pairwise training strategy for the smart selection process. Additionally, an imitation learning-based approach is designed to counteract the cold-start issues often seen in state-of-the-art learning-based approaches. Experimental results reveal that \model~ boosts model accuracy by 5.2\% to 56.9\%, accelerates the training convergence up to $2.01 \times$ and saves the energy consumption up to $40.1\%$.
Characterized Diffusion and Spatial-Temporal Interaction Network for Trajectory Prediction in Autonomous Driving
May 03, 2024Trajectory prediction is a cornerstone in autonomous driving (AD), playing a critical role in enabling vehicles to navigate safely and efficiently in dynamic environments. To address this task, this paper presents a novel trajectory prediction model tailored for accuracy in the face of heterogeneous and uncertain traffic scenarios. At the heart of this model lies the Characterized Diffusion Module, an innovative module designed to simulate traffic scenarios with inherent uncertainty. This module enriches the predictive process by infusing it with detailed semantic information, thereby enhancing trajectory prediction accuracy. Complementing this, our Spatio-Temporal (ST) Interaction Module captures the nuanced effects of traffic scenarios on vehicle dynamics across both spatial and temporal dimensions with remarkable effectiveness. Demonstrated through exhaustive evaluations, our model sets a new standard in trajectory prediction, achieving state-of-the-art (SOTA) results on the Next Generation Simulation (NGSIM), Highway Drone (HighD), and Macao Connected Autonomous Driving (MoCAD) datasets across both short and extended temporal spans. This performance underscores the model's unparalleled adaptability and efficacy in navigating complex traffic scenarios, including highways, urban streets, and intersections.
MFTraj: Map-Free, Behavior-Driven Trajectory Prediction for Autonomous Driving
May 02, 2024This paper introduces a trajectory prediction model tailored for autonomous driving, focusing on capturing complex interactions in dynamic traffic scenarios without reliance on high-definition maps. The model, termed MFTraj, harnesses historical trajectory data combined with a novel dynamic geometric graph-based behavior-aware module. At its core, an adaptive structure-aware interactive graph convolutional network captures both positional and behavioral features of road users, preserving spatial-temporal intricacies. Enhanced by a linear attention mechanism, the model achieves computational efficiency and reduced parameter overhead. Evaluations on the Argoverse, NGSIM, HighD, and MoCAD datasets underscore MFTraj's robustness and adaptability, outperforming numerous benchmarks even in data-challenged scenarios without the need for additional information such as HD maps or vectorized maps. Importantly, it maintains competitive performance even in scenarios with substantial missing data, on par with most existing state-of-the-art models. The results and methodology suggest a significant advancement in autonomous driving trajectory prediction, paving the way for safer and more efficient autonomous systems.
HydraLoRA: An Asymmetric LoRA Architecture for Efficient Fine-Tuning
Apr 30, 2024Adapting Large Language Models (LLMs) to new tasks through fine-tuning has been made more efficient by the introduction of Parameter-Efficient Fine-Tuning (PEFT) techniques, such as LoRA. However, these methods often underperform compared to full fine-tuning, particularly in scenarios involving complex datasets. This issue becomes even more pronounced in complex domains, highlighting the need for improved PEFT approaches that can achieve better performance. Through a series of experiments, we have uncovered two critical insights that shed light on the training and parameter inefficiency of LoRA. Building on these insights, we have developed HydraLoRA, a LoRA framework with an asymmetric structure that eliminates the need for domain expertise. Our experiments demonstrate that HydraLoRA outperforms other PEFT approaches, even those that rely on domain knowledge during the training and inference phases. \href{https://github.com/Clin0212/HydraLoRA}{Code}.
A Cognitive-Driven Trajectory Prediction Model for Autonomous Driving in Mixed Autonomy Environment
Apr 26, 2024As autonomous driving technology progresses, the need for precise trajectory prediction models becomes paramount. This paper introduces an innovative model that infuses cognitive insights into trajectory prediction, focusing on perceived safety and dynamic decision-making. Distinct from traditional approaches, our model excels in analyzing interactions and behavior patterns in mixed autonomy traffic scenarios. It represents a significant leap forward, achieving marked performance improvements on several key datasets. Specifically, it surpasses existing benchmarks with gains of 16.2% on the Next Generation Simulation (NGSIM), 27.4% on the Highway Drone (HighD), and 19.8% on the Macao Connected Autonomous Driving (MoCAD) dataset. Our proposed model shows exceptional proficiency in handling corner cases, essential for real-world applications. Moreover, its robustness is evident in scenarios with missing or limited data, outperforming most of the state-of-the-art baselines. This adaptability and resilience position our model as a viable tool for real-world autonomous driving systems, heralding a new standard in vehicle trajectory prediction for enhanced safety and efficiency.
Breaking the Memory Wall for Heterogeneous Federated Learning with Progressive Training
Apr 20, 2024This paper presents ProFL, a novel progressive FL framework to effectively break the memory wall. Specifically, ProFL divides the model into different blocks based on its original architecture. Instead of updating the full model in each training round, ProFL first trains the front blocks and safely freezes them after convergence. Training of the next block is then triggered. This process iterates until the training of the whole model is completed. In this way, the memory footprint is effectively reduced for feasible deployment on heterogeneous devices. In order to preserve the feature representation of each block, we decouple the whole training process into two stages: progressive model shrinking and progressive model growing. During the progressive model shrinking stage, we meticulously design corresponding output modules to assist each block in learning the expected feature representation and obtain the initialization parameters. Then, the obtained output modules are utilized in the corresponding progressive model growing stage. Additionally, to control the training pace for each block, a novel metric from the scalar perspective is proposed to assess the learning status of each block and determines when to trigger the training of the next one. Finally, we theoretically prove the convergence of ProFL and conduct extensive experiments on representative models and datasets to evaluate the effectiveness of ProFL. The results demonstrate that ProFL effectively reduces the peak memory footprint by up to 57.4% and improves model accuracy by up to 82.4%.
Integrated Sensing and Communication for Edge Inference with End-to-End Multi-View Fusion
Apr 16, 2024Integrated sensing and communication (ISAC) is a promising solution to accelerate edge inference via the dual use of wireless signals. However, this paradigm needs to minimize the inference error and latency under ISAC co-functionality interference, for which the existing ISAC or edge resource allocation algorithms become inefficient, as they ignore the inter-dependency between low-level ISAC designs and high-level inference services. This letter proposes an inference-oriented ISAC (IO-ISAC) scheme, which minimizes upper bounds on end-to-end inference error and latency using multi-objective optimization. The key to our approach is to derive a multi-view inference model that accounts for both the number of observations and the angles of observations, by integrating a half-voting fusion rule and an angle-aware sensing model. Simulation results show that the proposed IO-ISAC outperforms other benchmarks in terms of both accuracy and latency.
MPCOM: Robotic Data Gathering with Radio Mapping and Model Predictive Communication
Apr 16, 2024Robotic data gathering (RDG) is an emerging paradigm that navigates a robot to harvest data from remote sensors. However, motion planning in this paradigm needs to maximize the RDG efficiency instead of the navigation efficiency, for which the existing motion planning methods become inefficient, as they plan robot trajectories merely according to motion factors. This paper proposes radio map guided model predictive communication (MPCOM), which navigates the robot with both grid and radio maps for shape-aware collision avoidance and communication-aware trajectory generation in a dynamic environment. The proposed MPCOM is able to trade off the time spent on reaching goal, avoiding collision, and improving communication. MPCOM captures high-order signal propagation characteristics using radio maps and incorporates the map-guided communication regularizer to the motion planning block. Experiments in IRSIM and CARLA simulators show that the proposed MPCOM outperforms other benchmarks in both LOS and NLOS cases. Real-world testing based on car-like robots is also provided to demonstrate the effectiveness of MPCOM in indoor environments.
NeuPAN: Direct Point Robot Navigation with End-to-End Model-based Learning
Mar 11, 2024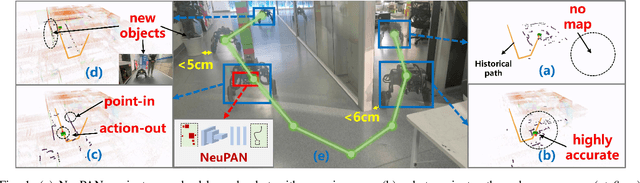

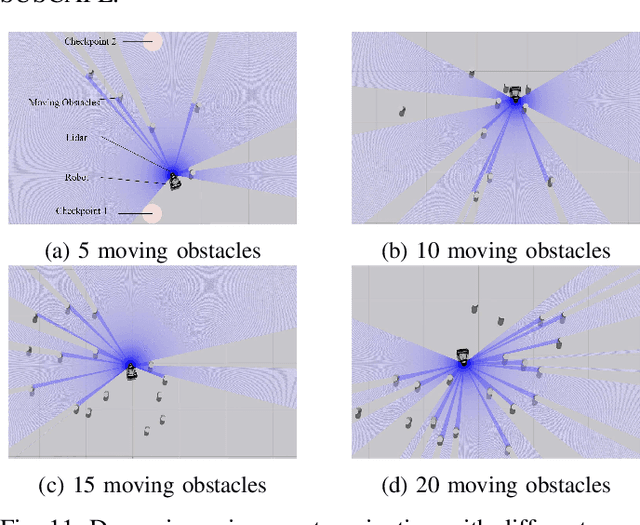
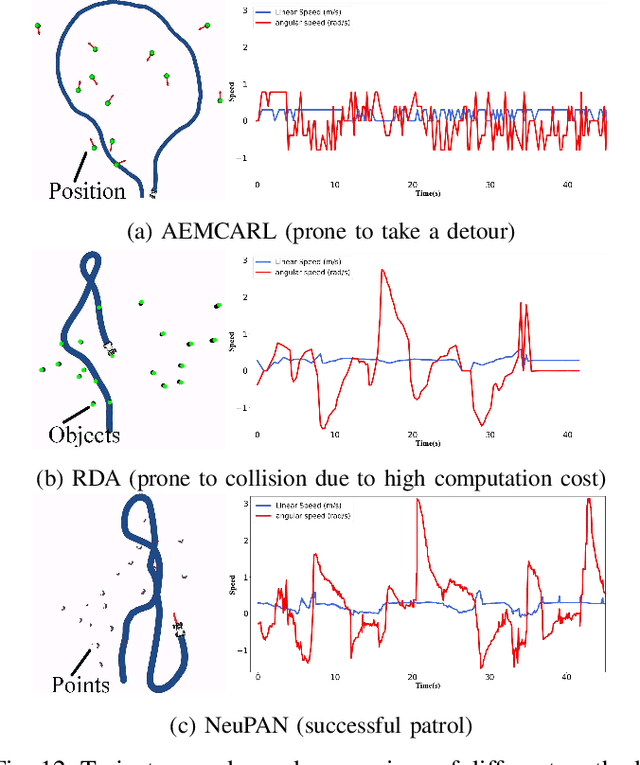
Navigating a nonholonomic robot in a cluttered environment requires extremely accurate perception and locomotion for collision avoidance. This paper presents NeuPAN: a real-time, highly-accurate, map-free, robot-agnostic, and environment-invariant robot navigation solution. Leveraging a tightly-coupled perception-locomotion framework, NeuPAN has two key innovations compared to existing approaches: 1) it directly maps raw points to a learned multi-frame distance space, avoiding error propagation from perception to control; 2) it is interpretable from an end-to-end model-based learning perspective, enabling provable convergence. The crux of NeuPAN is to solve a high-dimensional end-to-end mathematical model with various point-level constraints using the plug-and-play (PnP) proximal alternating-minimization network (PAN) with neurons in the loop. This allows NeuPAN to generate real-time, end-to-end, physically-interpretable motions directly from point clouds, which seamlessly integrates data- and knowledge-engines, where its network parameters are adjusted via back propagation. We evaluate NeuPAN on car-like robot, wheel-legged robot, and passenger autonomous vehicle, in both simulated and real-world environments. Experiments demonstrate that NeuPAN outperforms various benchmarks, in terms of accuracy, efficiency, robustness, and generalization capability across various environments, including the cluttered sandbox, office, corridor, and parking lot. We show that NeuPAN works well in unstructured environments with arbitrary-shape undetectable objects, making impassable ways passable.
Seamless Virtual Reality with Integrated Synchronizer and Synthesizer for Autonomous Driving
Mar 06, 2024

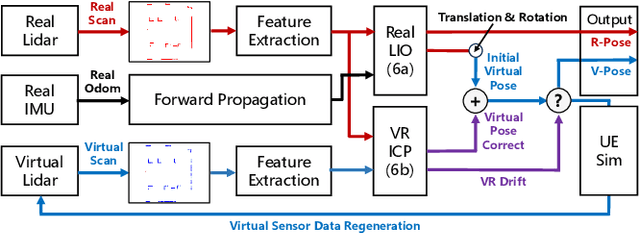
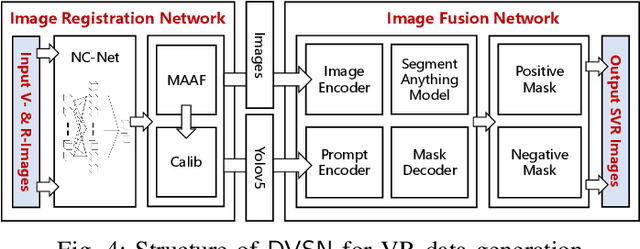
Virtual reality (VR) is a promising data engine for autonomous driving (AD). However, data fidelity in this paradigm is often degraded by VR inconsistency, for which the existing VR approaches become ineffective, as they ignore the inter-dependency between low-level VR synchronizer designs (i.e., data collector) and high-level VR synthesizer designs (i.e., data processor). This paper presents a seamless virtual reality SVR platform for AD, which mitigates such inconsistency, enabling VR agents to interact with each other in a shared symbiotic world. The crux to SVR is an integrated synchronizer and synthesizer IS2 design, which consists of a drift-aware lidar-inertial synchronizer for VR colocation and a motion-aware deep visual synthesis network for augmented reality image generation. We implement SVR on car-like robots in two sandbox platforms, achieving a cm-level VR colocalization accuracy and 3.2% VR image deviation, thereby avoiding missed collisions or model clippings. Experiments show that the proposed SVR reduces the intervention times, missed turns, and failure rates compared to other benchmarks. The SVR-trained neural network can handle unseen situations in real-world environments, by leveraging its knowledge learnt from the VR space.