 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBo Shen
CodeS: Natural Language to Code Repository via Multi-Layer Sketch
Mar 25, 2024
The impressive performance of large language models (LLMs) on code-related tasks has shown the potential of fully automated software development. In light of this, we introduce a new software engineering task, namely Natural Language to code Repository (NL2Repo). This task aims to generate an entire code repository from its natural language requirements. To address this task, we propose a simple yet effective framework CodeS, which decomposes NL2Repo into multiple sub-tasks by a multi-layer sketch. Specifically, CodeS includes three modules: RepoSketcher, FileSketcher, and SketchFiller. RepoSketcher first generates a repository's directory structure for given requirements; FileSketcher then generates a file sketch for each file in the generated structure; SketchFiller finally fills in the details for each function in the generated file sketch. To rigorously assess CodeS on the NL2Repo task, we carry out evaluations through both automated benchmarking and manual feedback analysis. For benchmark-based evaluation, we craft a repository-oriented benchmark, SketchEval, and design an evaluation metric, SketchBLEU. For feedback-based evaluation, we develop a VSCode plugin for CodeS and engage 30 participants in conducting empirical studies. Extensive experiments prove the effectiveness and practicality of CodeS on the NL2Repo task.
Can Programming Languages Boost Each Other via Instruction Tuning?
Sep 03, 2023
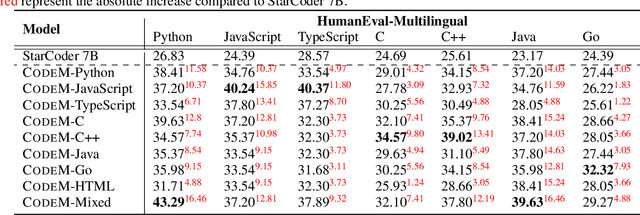


When human programmers have mastered a programming language, it would be easier when they learn a new programming language. In this report, we focus on exploring whether programming languages can boost each other during the instruction fine-tuning phase of code large language models. We conduct extensive experiments of 8 popular programming languages (Python, JavaScript, TypeScript, C, C++, Java, Go, HTML) on StarCoder. Results demonstrate that programming languages can significantly improve each other. For example, CodeM-Python 15B trained on Python is able to increase Java by an absolute 17.95% pass@1 on HumanEval-X. More surprisingly, we found that CodeM-HTML 7B trained on the HTML corpus can improve Java by an absolute 15.24% pass@1. Our training data is released at https://github.com/NL2Code/CodeM.
PanGu-Coder2: Boosting Large Language Models for Code with Ranking Feedback
Jul 27, 2023

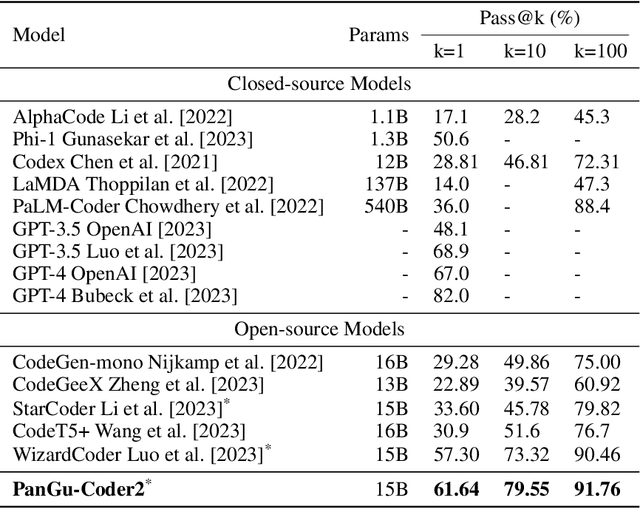
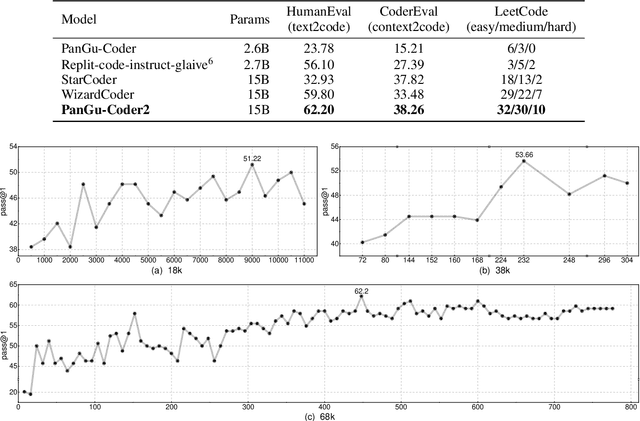
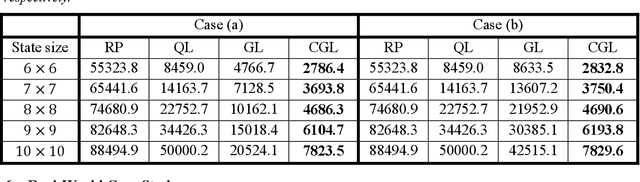
Large Language Models for Code (Code LLM) are flourishing. New and powerful models are released on a weekly basis, demonstrating remarkable performance on the code generation task. Various approaches have been proposed to boost the code generation performance of pre-trained Code LLMs, such as supervised fine-tuning, instruction tuning, reinforcement learning, etc. In this paper, we propose a novel RRTF (Rank Responses to align Test&Teacher Feedback) framework, which can effectively and efficiently boost pre-trained large language models for code generation. Under this framework, we present PanGu-Coder2, which achieves 62.20% pass@1 on the OpenAI HumanEval benchmark. Furthermore, through an extensive evaluation on CoderEval and LeetCode benchmarks, we show that PanGu-Coder2 consistently outperforms all previous Code LLMs.
Provable Convergence of Tensor Decomposition-Based Neural Network Training
Mar 13, 2023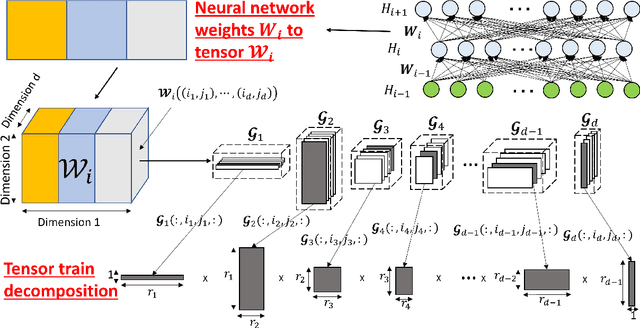
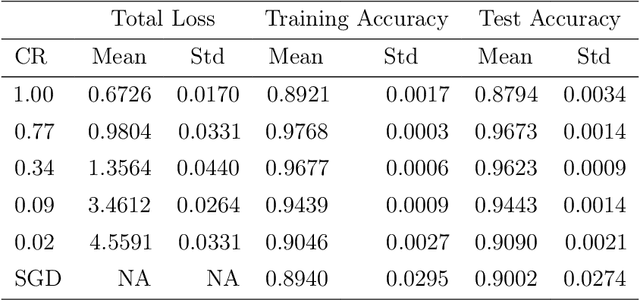
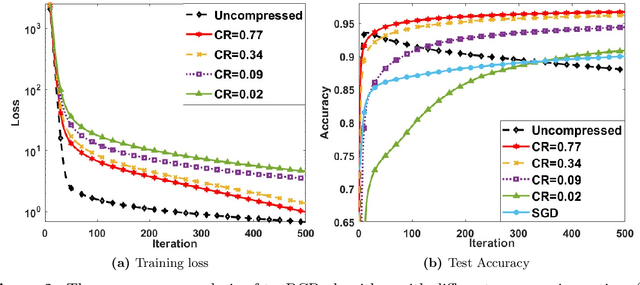
Advanced tensor decomposition, such as tensor train (TT), has been widely studied for tensor decomposition-based neural network (NN) training, which is one of the most common model compression methods. However, training NN with tensor decomposition always suffers significant accuracy loss and convergence issues. In this paper, a holistic framework is proposed for tensor decomposition-based NN training by formulating TT decomposition-based NN training as a nonconvex optimization problem. This problem can be solved by the proposed tensor block coordinate descent (tenBCD) method, which is a gradient-free algorithm. The global convergence of tenBCD to a critical point at a rate of O(1/k) is established with the Kurdyka {\L}ojasiewicz (K{\L}) property, where k is the number of iterations. The theoretical results can be extended to the popular residual neural networks (ResNets). The effectiveness and efficiency of our proposed framework are verified through an image classification dataset, where our proposed method can converge efficiently in training and prevent overfitting.
Can Gradient Descent Provably Learn Linear Dynamic Systems?
Nov 19, 2022
We study the learning ability of linear recurrent neural networks with gradient descent. We prove the first theoretical guarantee on linear RNNs with Gradient Descent to learn any stable linear dynamic system. We show that despite the non-convexity of the optimization loss if the width of the RNN is large enough (and the required width in hidden layers does not rely on the length of the input sequence), a linear RNN can provably learn any stable linear dynamic system with the sample and time complexity polynomial in $\frac{1}{1-\rho_C}$ where $\rho_C$ is roughly the spectral radius of the stable system. Our results provide the first theoretical guarantee to learn a linear RNN and demonstrate how can the recurrent structure help to learn a dynamic system.
Imbalanced Data Classification via Generative Adversarial Network with Application to Anomaly Detection in Additive Manufacturing Process
Nov 09, 2022
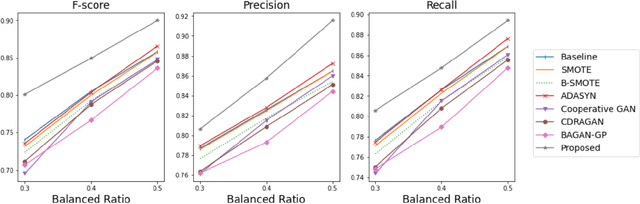

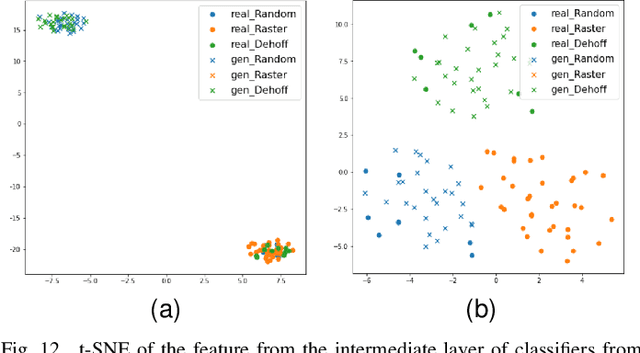
Supervised classification methods have been widely utilized for the quality assurance of the advanced manufacturing process, such as additive manufacturing (AM) for anomaly (defects) detection. However, since abnormal states (with defects) occur much less frequently than normal ones (without defects) in the manufacturing process, the number of sensor data samples collected from a normal state outweighs that from an abnormal state. This issue causes imbalanced training data for classification models, thus deteriorating the performance of detecting abnormal states in the process. It is beneficial to generate effective artificial sample data for the abnormal states to make a more balanced training set. To achieve this goal, this paper proposes a novel data augmentation method based on a generative adversarial network (GAN) using additive manufacturing process image sensor data. The novelty of our approach is that a standard GAN and classifier are jointly optimized with techniques to stabilize the learning process of standard GAN. The diverse and high-quality generated samples provide balanced training data to the classifier. The iterative optimization between GAN and classifier provides the high-performance classifier. The effectiveness of the proposed method is validated by both open-source data and real-world case studies in polymer and metal AM processes.
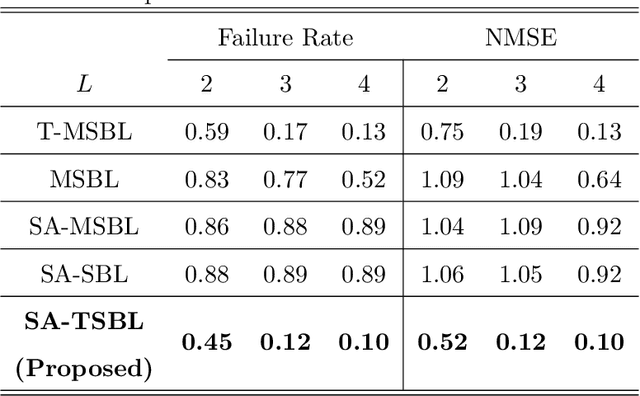
A Novel Sparse Bayesian Learning and Its Application to Fault Diagnosis for Multistation Assembly Systems
Oct 28, 2022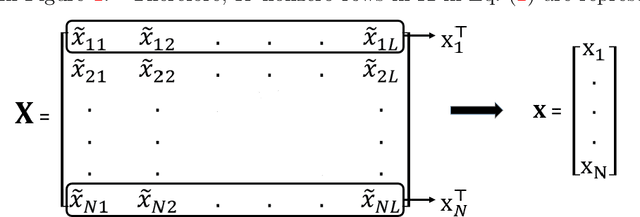
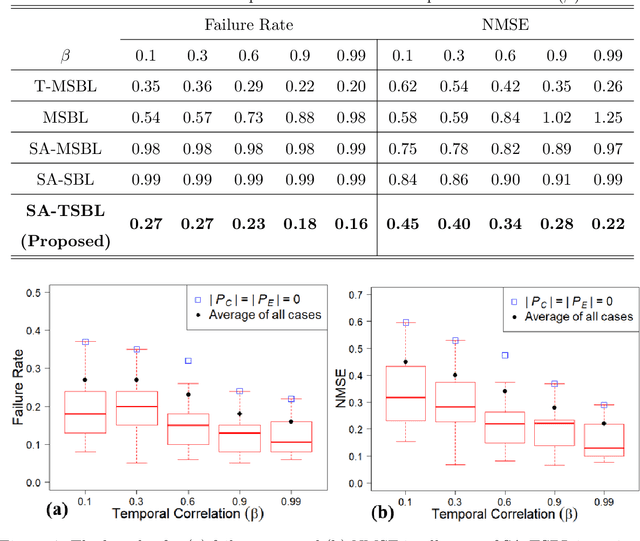
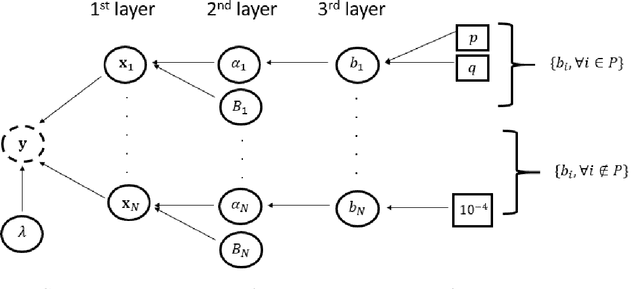
This paper addresses the problem of fault diagnosis in multistation assembly systems. Fault diagnosis is to identify process faults that cause the excessive dimensional variation of the product using dimensional measurements. For such problems, the challenge is solving an underdetermined system caused by a common phenomenon in practice; namely, the number of measurements is less than that of the process errors. To address this challenge, this paper attempts to solve the following two problems: (1) how to utilize the temporal correlation in the time series data of each process error and (2) how to apply prior knowledge regarding which process errors are more likely to be process faults. A novel sparse Bayesian learning method is proposed to achieve the above objectives. The method consists of three hierarchical layers. The first layer has parameterized prior distribution that exploits the temporal correlation of each process error. Furthermore, the second and third layers achieve the prior distribution representing the prior knowledge of process faults. Then, these prior distributions are updated with the likelihood function of the measurement samples from the process, resulting in the accurate posterior distribution of process faults from an underdetermined system. Since posterior distributions of process faults are intractable, this paper derives approximate posterior distributions via Variational Bayes inference. Numerical and simulation case studies using an actual autobody assembly process are performed to demonstrate the effectiveness of the proposed method.
Reinforcement Learning-based Defect Mitigation for Quality Assurance of Additive Manufacturing
Oct 28, 2022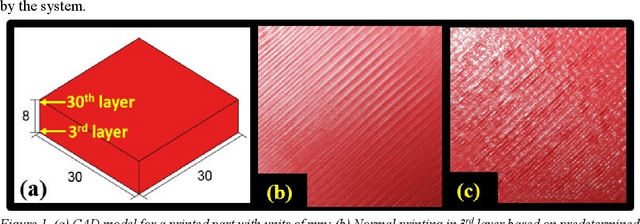

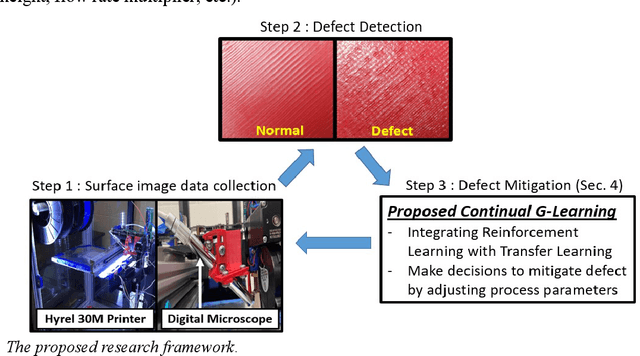
Additive Manufacturing (AM) is a powerful technology that produces complex 3D geometries using various materials in a layer-by-layer fashion. However, quality assurance is the main challenge in AM industry due to the possible time-varying processing conditions during AM process. Notably, new defects may occur during printing, which cannot be mitigated by offline analysis tools that focus on existing defects. This challenge motivates this work to develop online learning-based methods to deal with the new defects during printing. Since AM typically fabricates a small number of customized products, this paper aims to create an online learning-based strategy to mitigate the new defects in AM process while minimizing the number of samples needed. The proposed method is based on model-free Reinforcement Learning (RL). It is called Continual G-learning since it transfers several sources of prior knowledge to reduce the needed training samples in the AM process. Offline knowledge is obtained from literature, while online knowledge is learned during printing. The proposed method develops a new algorithm for learning the optimal defect mitigation strategies proven the best performance when utilizing both knowledge sources. Numerical and real-world case studies in a fused filament fabrication (FFF) platform are performed and demonstrate the effectiveness of the proposed method.
PanGu-Coder: Program Synthesis with Function-Level Language Modeling
Jul 22, 2022
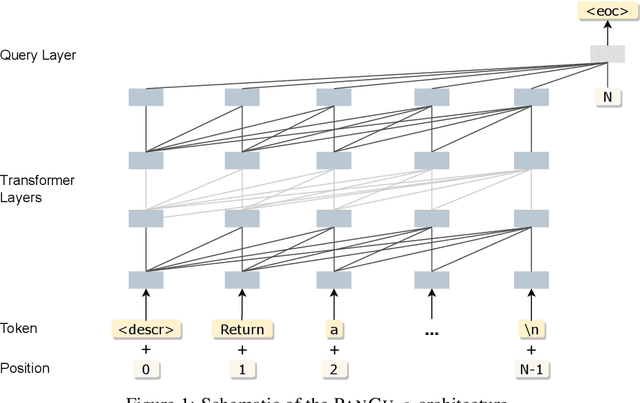
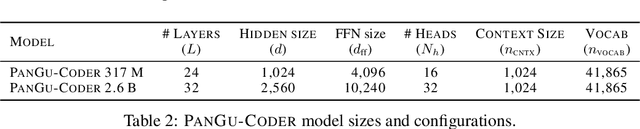
We present PanGu-Coder, a pretrained decoder-only language model adopting the PanGu-Alpha architecture for text-to-code generation, i.e. the synthesis of programming language solutions given a natural language problem description. We train PanGu-Coder using a two-stage strategy: the first stage employs Causal Language Modelling (CLM) to pre-train on raw programming language data, while the second stage uses a combination of Causal Language Modelling and Masked Language Modelling (MLM) training objectives that focus on the downstream task of text-to-code generation and train on loosely curated pairs of natural language program definitions and code functions. Finally, we discuss PanGu-Coder-FT, which is fine-tuned on a combination of competitive programming problems and code with continuous integration tests. We evaluate PanGu-Coder with a focus on whether it generates functionally correct programs and demonstrate that it achieves equivalent or better performance than similarly sized models, such as CodeX, while attending a smaller context window and training on less data.
Self-scalable Tanh (Stan): Faster Convergence and Better Generalization in Physics-informed Neural Networks
Apr 29, 2022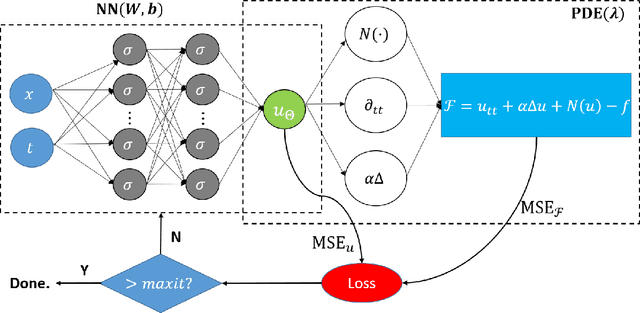
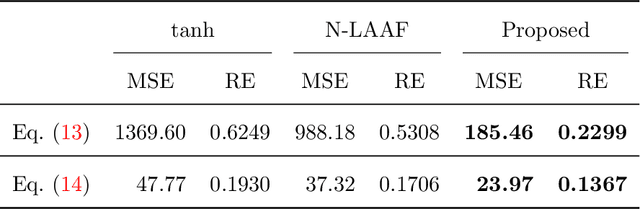
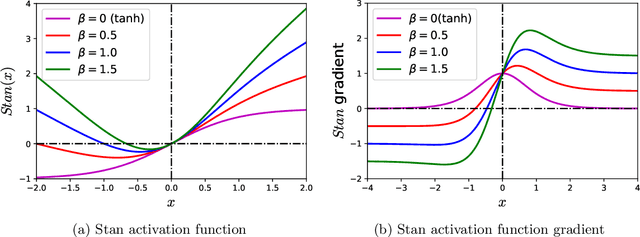
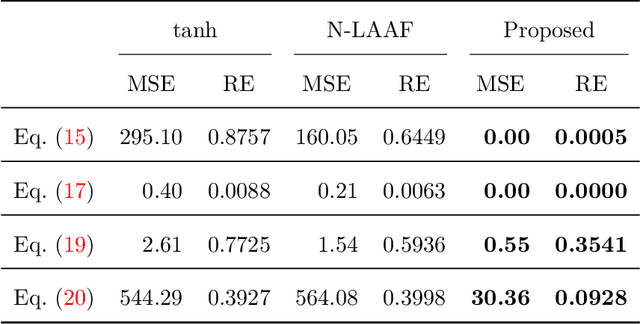
Physics-informed Neural Networks (PINNs) are gaining attention in the engineering and scientific literature for solving a range of differential equations with applications in weather modeling, healthcare, manufacturing, etc. Poor scalability is one of the barriers to utilizing PINNs for many real-world problems. To address this, a Self-scalable tanh (Stan) activation function is proposed for the PINNs. The proposed Stan function is smooth, non-saturating, and has a trainable parameter. During training, it can allow easy flow of gradients to compute the required derivatives and also enable systematic scaling of the input-output mapping. It is shown theoretically that the PINNs with the proposed Stan function have no spurious stationary points when using gradient descent algorithms. The proposed Stan is tested on a number of numerical studies involving general regression problems. It is subsequently used for solving multiple forward problems, which involve second-order derivatives and multiple dimensions, and an inverse problem where the thermal diffusivity of a rod is predicted with heat conduction data. These case studies establish empirically that the Stan activation function can achieve better training and more accurate predictions than the existing activation functions in the literature.