 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBowen Zhao
Set the Clock: Temporal Alignment of Pretrained Language Models
Feb 26, 2024
Language models (LMs) are trained on web text originating from many points in time and, in general, without any explicit temporal grounding. This work investigates the temporal chaos of pretrained LMs and explores various methods to align their internal knowledge to a target time, which we call "temporal alignment." To do this, we first automatically construct a dataset containing 20K time-sensitive questions and their answers for each year from 2000 to 2023. Based on this dataset, we empirically show that pretrained LMs (e.g., LLaMa2), despite having a recent pretraining cutoff (e.g., 2022), mostly answer questions using earlier knowledge (e.g., in 2019). We then develop several methods, from prompting to finetuning, to align LMs to use their most recent knowledge when answering questions, and investigate various factors in this alignment. Our experiments show that aligning LLaMa2 to the year 2022 can boost its performance by up to 62% relatively as measured by that year, even without mentioning time information explicitly, indicating the possibility of aligning models' internal sense of time after pretraining. Finally, we find that alignment to a historical time is also possible, with up to 2.8$\times$ the performance of the unaligned LM in 2010 if finetuning models to that year. These findings hint at the sophistication of LMs' internal knowledge organization and the necessity of tuning them properly.
APT: Adaptive Pruning and Tuning Pretrained Language Models for Efficient Training and Inference
Jan 22, 2024Fine-tuning and inference with large Language Models (LM) are generally known to be expensive. Parameter-efficient fine-tuning over pretrained LMs reduces training memory by updating a small number of LM parameters but does not improve inference efficiency. Structured pruning improves LM inference efficiency by removing consistent parameter blocks, yet often increases training memory and time. To improve both training and inference efficiency, we introduce APT that adaptively prunes and tunes parameters for the LMs. At the early stage of fine-tuning, APT dynamically adds salient tuning parameters for fast and accurate convergence while discarding unimportant parameters for efficiency. Compared to baselines, our experiments show that APT maintains up to 98% task performance when pruning RoBERTa and T5 models with 40% parameters left while keeping 86.4% LLaMA models' performance with 70% parameters remained. Furthermore, APT speeds up LMs fine-tuning by up to 8x and reduces large LMs memory training footprint by up to 70%.
Large Language Models are Complex Table Parsers
Dec 13, 2023With the Generative Pre-trained Transformer 3.5 (GPT-3.5) exhibiting remarkable reasoning and comprehension abilities in Natural Language Processing (NLP), most Question Answering (QA) research has primarily centered around general QA tasks based on GPT, neglecting the specific challenges posed by Complex Table QA. In this paper, we propose to incorporate GPT-3.5 to address such challenges, in which complex tables are reconstructed into tuples and specific prompt designs are employed for dialogues. Specifically, we encode each cell's hierarchical structure, position information, and content as a tuple. By enhancing the prompt template with an explanatory description of the meaning of each tuple and the logical reasoning process of the task, we effectively improve the hierarchical structure awareness capability of GPT-3.5 to better parse the complex tables. Extensive experiments and results on Complex Table QA datasets, i.e., the open-domain dataset HiTAB and the aviation domain dataset AIT-QA show that our approach significantly outperforms previous work on both datasets, leading to state-of-the-art (SOTA) performance.
Neural Impostor: Editing Neural Radiance Fields with Explicit Shape Manipulation
Oct 09, 2023Neural Radiance Fields (NeRF) have significantly advanced the generation of highly realistic and expressive 3D scenes. However, the task of editing NeRF, particularly in terms of geometry modification, poses a significant challenge. This issue has obstructed NeRF's wider adoption across various applications. To tackle the problem of efficiently editing neural implicit fields, we introduce Neural Impostor, a hybrid representation incorporating an explicit tetrahedral mesh alongside a multigrid implicit field designated for each tetrahedron within the explicit mesh. Our framework bridges the explicit shape manipulation and the geometric editing of implicit fields by utilizing multigrid barycentric coordinate encoding, thus offering a pragmatic solution to deform, composite, and generate neural implicit fields while maintaining a complex volumetric appearance. Furthermore, we propose a comprehensive pipeline for editing neural implicit fields based on a set of explicit geometric editing operations. We show the robustness and adaptability of our system through diverse examples and experiments, including the editing of both synthetic objects and real captured data. Finally, we demonstrate the authoring process of a hybrid synthetic-captured object utilizing a variety of editing operations, underlining the transformative potential of Neural Impostor in the field of 3D content creation and manipulation.
CEC: Crowdsourcing-based Evolutionary Computation for Distributed Optimization
Apr 12, 2023
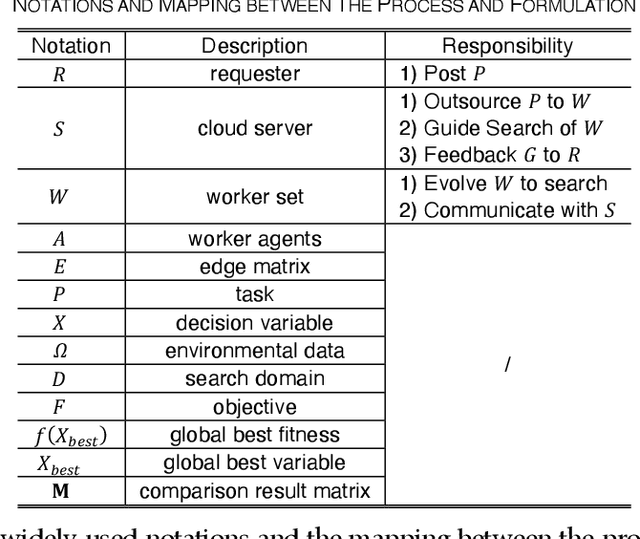
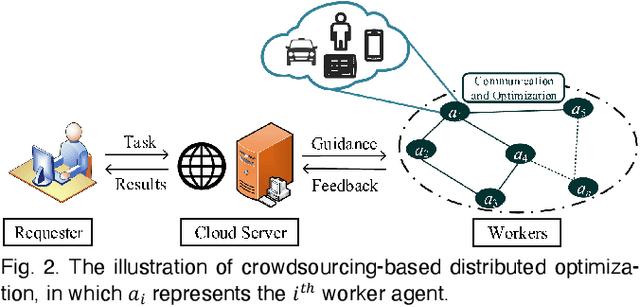
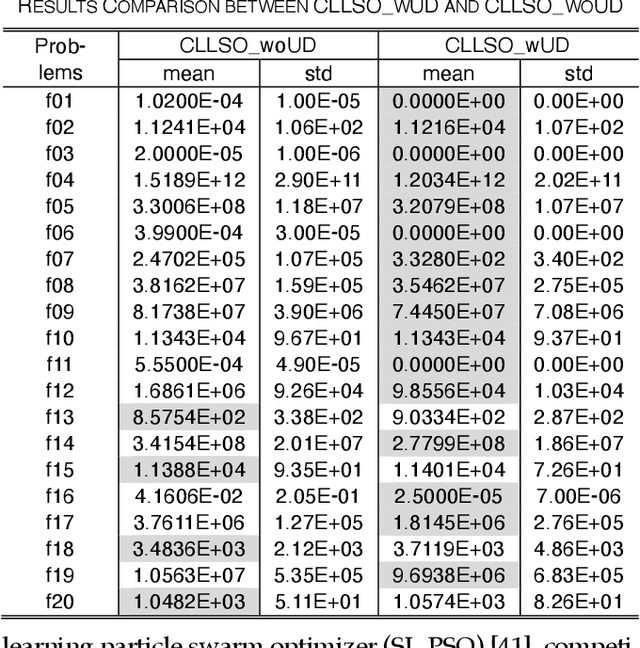
Crowdsourcing is an emerging computing paradigm that takes advantage of the intelligence of a crowd to solve complex problems effectively. Besides collecting and processing data, it is also a great demand for the crowd to conduct optimization. Inspired by this, this paper intends to introduce crowdsourcing into evolutionary computation (EC) to propose a crowdsourcing-based evolutionary computation (CEC) paradigm for distributed optimization. EC is helpful for optimization tasks of crowdsourcing and in turn, crowdsourcing can break the spatial limitation of EC for large-scale distributed optimization. Therefore, this paper firstly introduces the paradigm of crowdsourcing-based distributed optimization. Then, CEC is elaborated. CEC performs optimization based on a server and a group of workers, in which the server dispatches a large task to workers. Workers search for promising solutions through EC optimizers and cooperate with connected neighbors. To eliminate uncertainties brought by the heterogeneity of worker behaviors and devices, the server adopts the competitive ranking and uncertainty detection strategy to guide the cooperation of workers. To illustrate the satisfactory performance of CEC, a crowdsourcing-based swarm optimizer is implemented as an example for extensive experiments. Comparison results on benchmark functions and a distributed clustering optimization problem demonstrate the potential applications of CEC.
When Evolutionary Computation Meets Privacy
Mar 22, 2023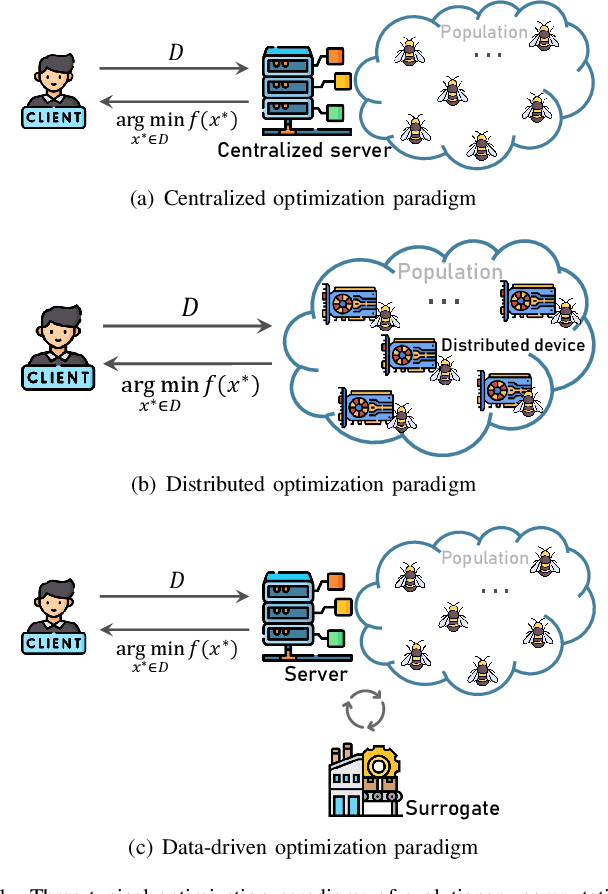
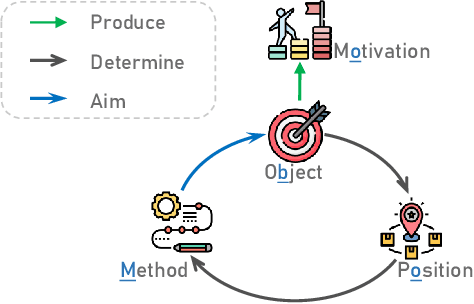
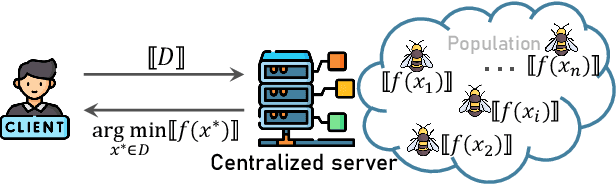
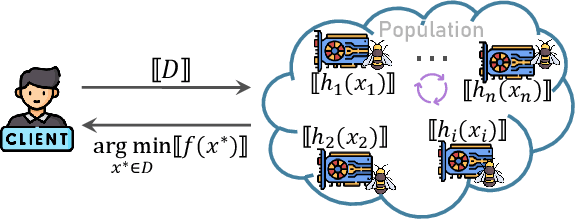
Recently, evolutionary computation (EC) has been promoted by machine learning, distributed computing, and big data technologies, resulting in new research directions of EC like distributed EC and surrogate-assisted EC. These advances have significantly improved the performance and the application scope of EC, but also trigger privacy leakages, such as the leakage of optimal results and surrogate model. Accordingly, evolutionary computation combined with privacy protection is becoming an emerging topic. However, privacy concerns in evolutionary computation lack a systematic exploration, especially for the object, motivation, position, and method of privacy protection. To this end, in this paper, we discuss three typical optimization paradigms (i.e., \textit{centralized optimization, distributed optimization, and data-driven optimization}) to characterize optimization modes of evolutionary computation and propose BOOM to sort out privacy concerns in evolutionary computation. Specifically, the centralized optimization paradigm allows clients to outsource optimization problems to the centralized server and obtain optimization solutions from the server. While the distributed optimization paradigm exploits the storage and computational power of distributed devices to solve optimization problems. Also, the data-driven optimization paradigm utilizes data collected in history to tackle optimization problems lacking explicit objective functions. Particularly, this paper adopts BOOM to characterize the object and motivation of privacy protection in three typical optimization paradigms and discusses potential privacy-preserving technologies balancing optimization performance and privacy guarantees in three typical optimization paradigms. Furthermore, this paper attempts to foresee some new research directions of privacy-preserving evolutionary computation.
GazeReader: Detecting Unknown Word Using Webcam for English as a Second Language (ESL) Learners
Mar 18, 2023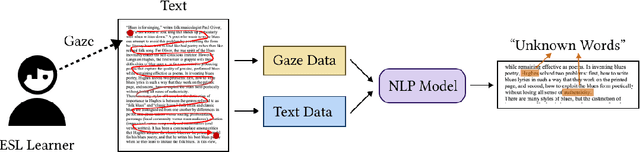
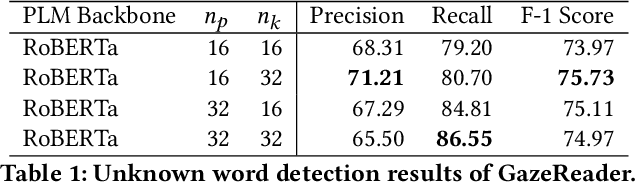
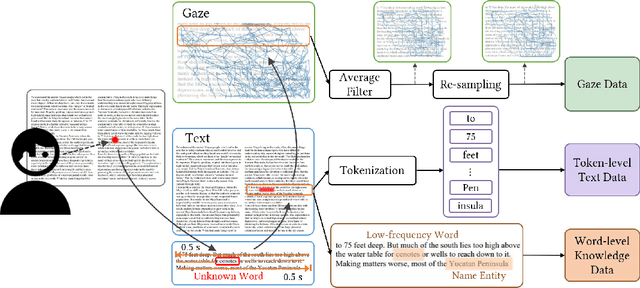

Automatic unknown word detection techniques can enable new applications for assisting English as a Second Language (ESL) learners, thus improving their reading experiences. However, most modern unknown word detection methods require dedicated eye-tracking devices with high precision that are not easily accessible to end-users. In this work, we propose GazeReader, an unknown word detection method only using a webcam. GazeReader tracks the learner's gaze and then applies a transformer-based machine learning model that encodes the text information to locate the unknown word. We applied knowledge enhancement including term frequency, part of speech, and named entity recognition to improve the performance. The user study indicates that the accuracy and F1-score of our method were 98.09% and 75.73%, respectively. Lastly, we explored the design scope for ESL reading and discussed the findings.
A Survey of Secure Computation Using Trusted Execution Environments
Feb 23, 2023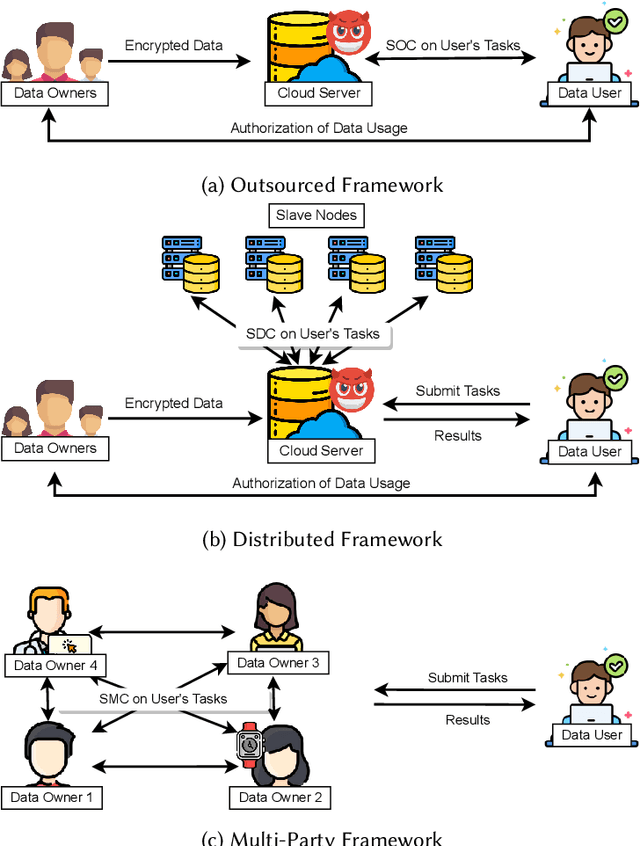
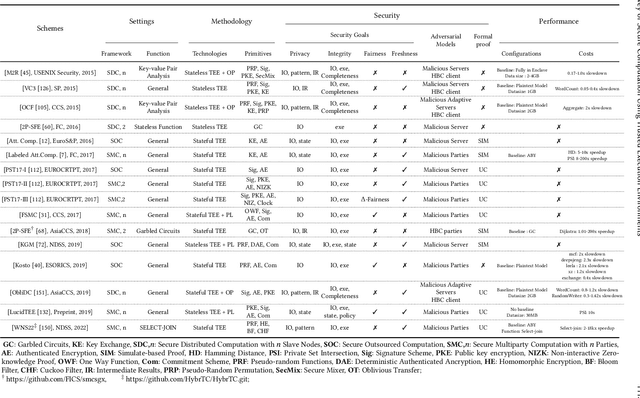
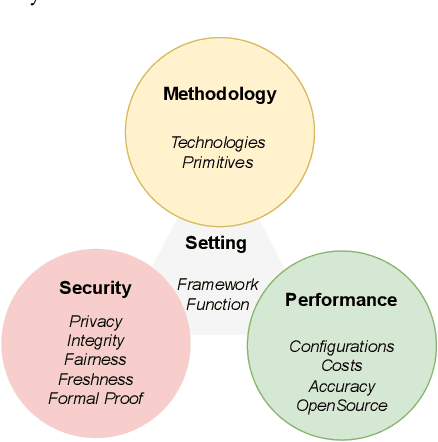
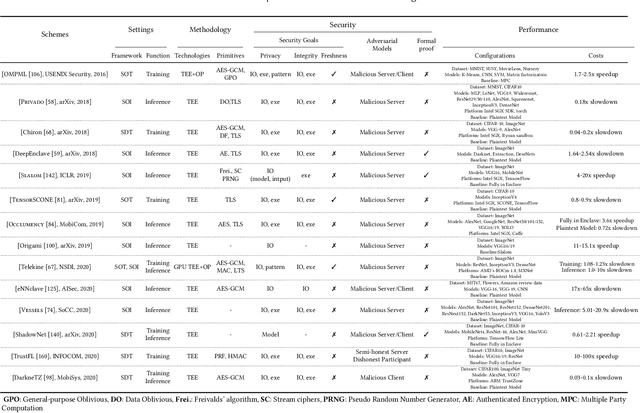
As an essential technology underpinning trusted computing, the trusted execution environment (TEE) allows one to launch computation tasks on both on- and off-premises data while assuring confidentiality and integrity. This article provides a systematic review and comparison of TEE-based secure computation protocols. We first propose a taxonomy that classifies secure computation protocols into three major categories, namely secure outsourced computation, secure distributed computation and secure multi-party computation. To enable a fair comparison of these protocols, we also present comprehensive assessment criteria with respect to four aspects: setting, methodology, security and performance. Based on these criteria, we review, discuss and compare the state-of-the-art TEE-based secure computation protocols for both general-purpose computation functions and special-purpose ones, such as privacy-preserving machine learning and encrypted database queries. To the best of our knowledge, this article is the first survey to review TEE-based secure computation protocols and the comprehensive comparison can serve as a guideline for selecting suitable protocols for deployment in practice. Finally, we also discuss several future research directions and challenges.
Delving into Identify-Emphasize Paradigm for Combating Unknown Bias
Feb 22, 2023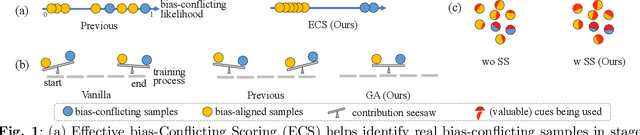
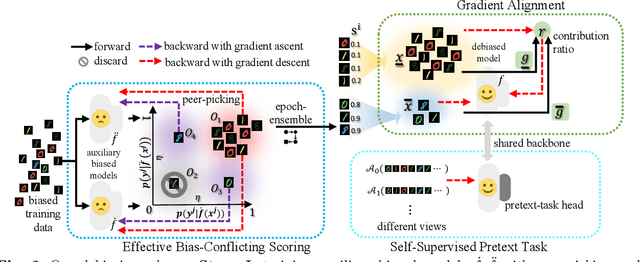
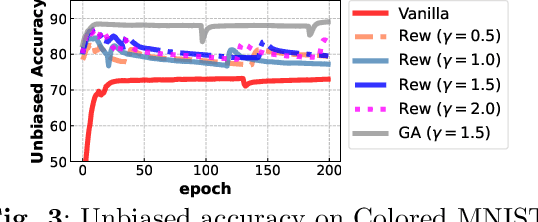
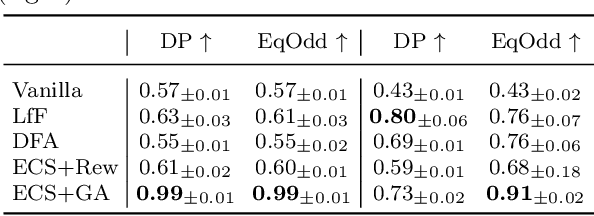
Dataset biases are notoriously detrimental to model robustness and generalization. The identify-emphasize paradigm appears to be effective in dealing with unknown biases. However, we discover that it is still plagued by two challenges: A, the quality of the identified bias-conflicting samples is far from satisfactory; B, the emphasizing strategies only produce suboptimal performance. In this paper, for challenge A, we propose an effective bias-conflicting scoring method (ECS) to boost the identification accuracy, along with two practical strategies -- peer-picking and epoch-ensemble. For challenge B, we point out that the gradient contribution statistics can be a reliable indicator to inspect whether the optimization is dominated by bias-aligned samples. Then, we propose gradient alignment (GA), which employs gradient statistics to balance the contributions of the mined bias-aligned and bias-conflicting samples dynamically throughout the learning process, forcing models to leverage intrinsic features to make fair decisions. Furthermore, we incorporate self-supervised (SS) pretext tasks into training, which enable models to exploit richer features rather than the simple shortcuts, resulting in more robust models. Experiments are conducted on multiple datasets in various settings, demonstrating that the proposed solution can mitigate the impact of unknown biases and achieve state-of-the-art performance.
DELTA: degradation-free fully test-time adaptation
Jan 30, 2023
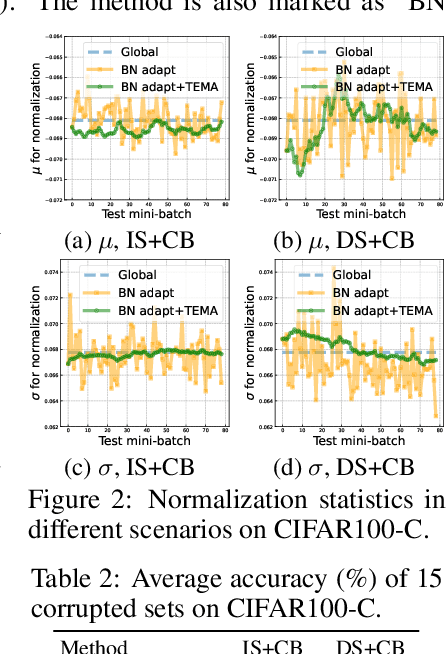
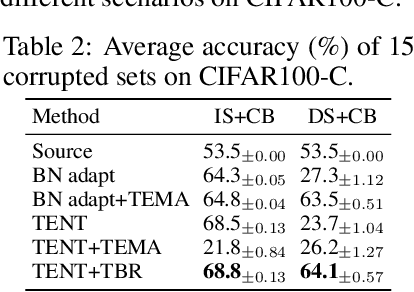
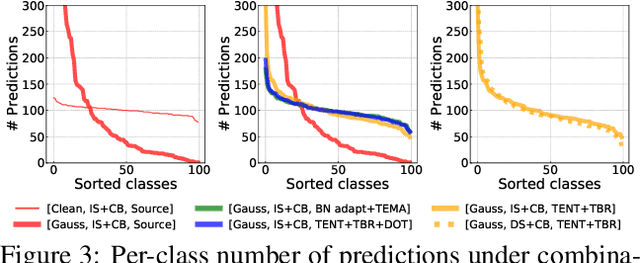
Fully test-time adaptation aims at adapting a pre-trained model to the test stream during real-time inference, which is urgently required when the test distribution differs from the training distribution. Several efforts have been devoted to improving adaptation performance. However, we find that two unfavorable defects are concealed in the prevalent adaptation methodologies like test-time batch normalization (BN) and self-learning. First, we reveal that the normalization statistics in test-time BN are completely affected by the currently received test samples, resulting in inaccurate estimates. Second, we show that during test-time adaptation, the parameter update is biased towards some dominant classes. In addition to the extensively studied test stream with independent and class-balanced samples, we further observe that the defects can be exacerbated in more complicated test environments, such as (time) dependent or class-imbalanced data. We observe that previous approaches work well in certain scenarios while show performance degradation in others due to their faults. In this paper, we provide a plug-in solution called DELTA for Degradation-freE fuLly Test-time Adaptation, which consists of two components: (i) Test-time Batch Renormalization (TBR), introduced to improve the estimated normalization statistics. (ii) Dynamic Online re-weighTing (DOT), designed to address the class bias within optimization. We investigate various test-time adaptation methods on three commonly used datasets with four scenarios, and a newly introduced real-world dataset. DELTA can help them deal with all scenarios simultaneously, leading to SOTA performance.