 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoyan Gao
Meta Mirror Descent: Optimiser Learning for Fast Convergence
Mar 05, 2022
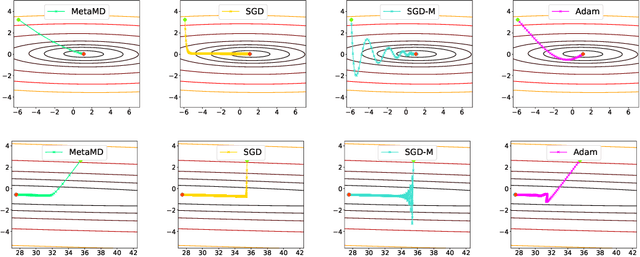
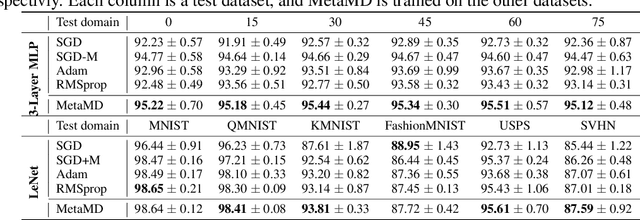
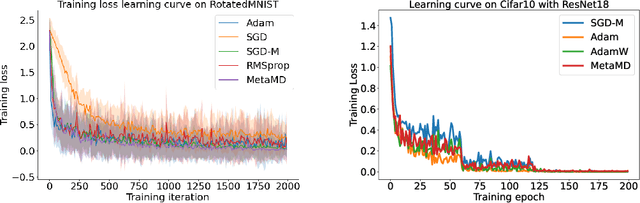
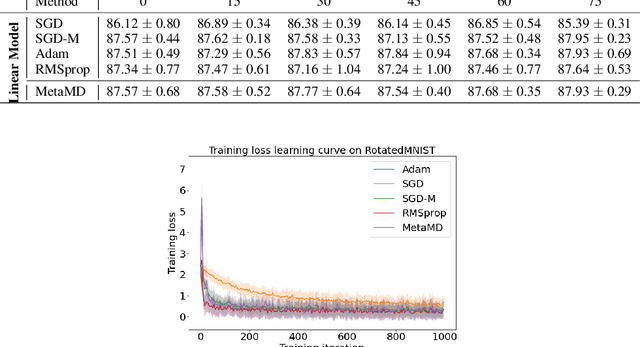
Optimisers are an essential component for training machine learning models, and their design influences learning speed and generalisation. Several studies have attempted to learn more effective gradient-descent optimisers via solving a bi-level optimisation problem where generalisation error is minimised with respect to optimiser parameters. However, most existing optimiser learning methods are intuitively motivated, without clear theoretical support. We take a different perspective starting from mirror descent rather than gradient descent, and meta-learning the corresponding Bregman divergence. Within this paradigm, we formalise a novel meta-learning objective of minimising the regret bound of learning. The resulting framework, termed Meta Mirror Descent (MetaMD), learns to accelerate optimisation speed. Unlike many meta-learned optimisers, it also supports convergence and generalisation guarantees and uniquely does so without requiring validation data. We evaluate our framework on a variety of tasks and architectures in terms of convergence rate and generalisation error and demonstrate strong performance.
Searching for Robustness: Loss Learning for Noisy Classification Tasks
Feb 27, 2021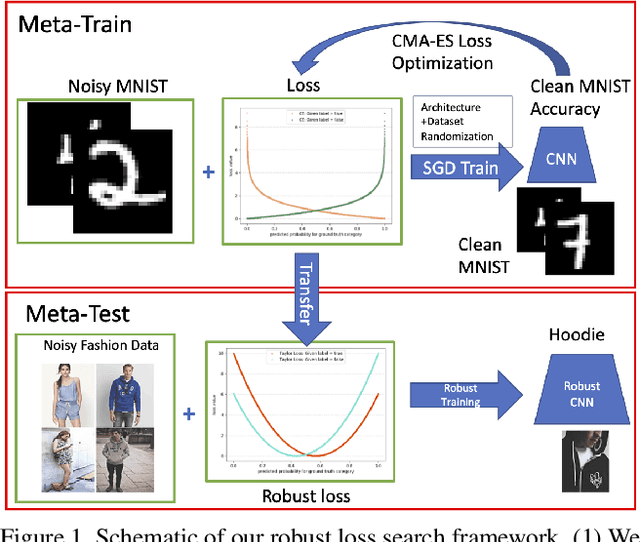
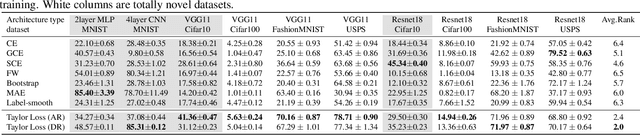
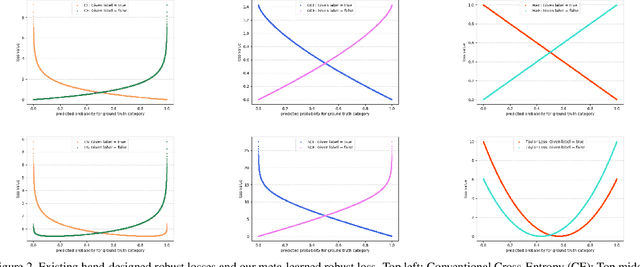
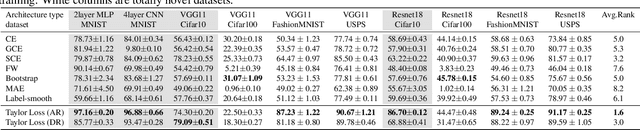
We present a "learning to learn" approach for automatically constructing white-box classification loss functions that are robust to label noise in the training data. We parameterize a flexible family of loss functions using Taylor polynomials, and apply evolutionary strategies to search for noise-robust losses in this space. To learn re-usable loss functions that can apply to new tasks, our fitness function scores their performance in aggregate across a range of training dataset and architecture combinations. The resulting white-box loss provides a simple and fast "plug-and-play" module that enables effective noise-robust learning in diverse downstream tasks, without requiring a special training procedure or network architecture. The efficacy of our method is demonstrated on a variety of datasets with both synthetic and real label noise, where we compare favourably to previous work.
Deep clustering with concrete k-means
Oct 17, 2019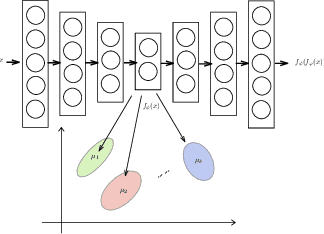
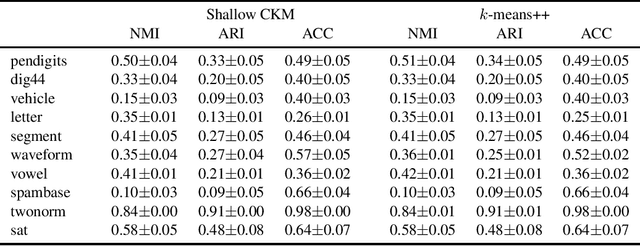
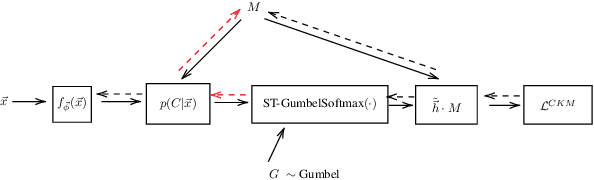

We address the problem of simultaneously learning a k-means clustering and deep feature representation from unlabelled data, which is of interest due to the potential of deep k-means to outperform traditional two-step feature extraction and shallow-clustering strategies. We achieve this by developing a gradient-estimator for the non-differentiable k-means objective via the Gumbel-Softmax reparameterisation trick. In contrast to previous attempts at deep clustering, our concrete k-means model can be optimised with respect to the canonical k-means objective and is easily trained end-to-end without resorting to alternating optimisation. We demonstrate the efficacy of our method on standard clustering benchmarks.