 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHenry Gouk
Is Scaling Learned Optimizers Worth It? Evaluating The Value of VeLO's 4000 TPU Months
Oct 27, 2023
We analyze VeLO (versatile learned optimizer), the largest scale attempt to train a general purpose "foundational" optimizer to date. VeLO was trained on thousands of machine learning tasks using over 4000 TPU months with the goal of producing an optimizer capable of generalizing to new problems while being hyperparameter free, and outperforming industry standards such as Adam. We independently evaluate VeLO on the MLCommons optimizer benchmark suite. We find that, contrary to initial claims: (1) VeLO has a critical hyperparameter that needs problem-specific tuning, (2) VeLO does not necessarily outperform competitors in quality of solution found, and (3) VeLO is not faster than competing optimizers at reducing the training loss. These observations call into question VeLO's generality and the value of the investment in training it.
Evaluating the Evaluators: Are Current Few-Shot Learning Benchmarks Fit for Purpose?
Jul 06, 2023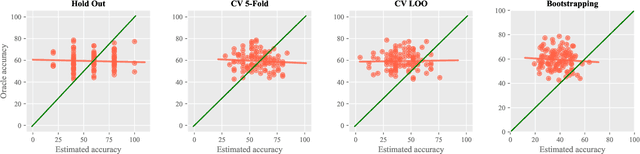
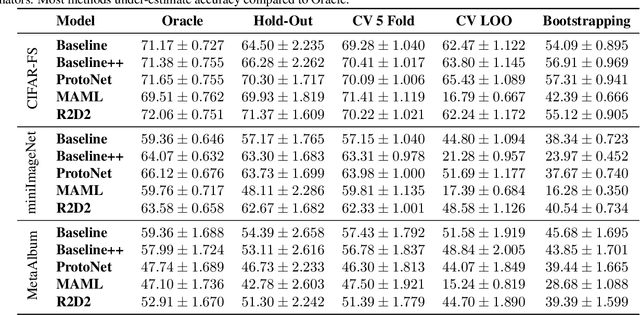
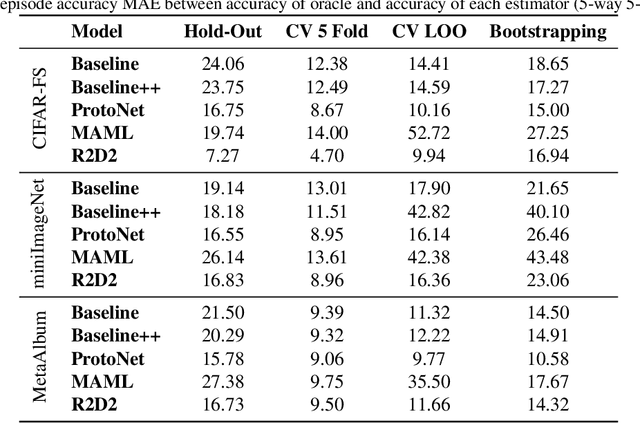
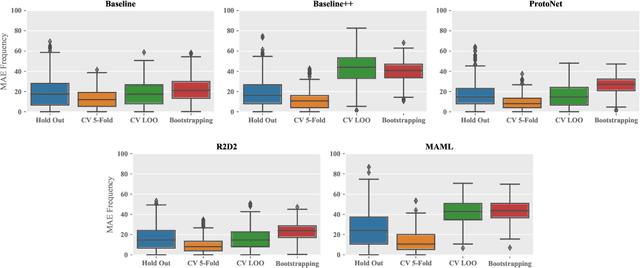
Numerous benchmarks for Few-Shot Learning have been proposed in the last decade. However all of these benchmarks focus on performance averaged over many tasks, and the question of how to reliably evaluate and tune models trained for individual tasks in this regime has not been addressed. This paper presents the first investigation into task-level evaluation -- a fundamental step when deploying a model. We measure the accuracy of performance estimators in the few-shot setting, consider strategies for model selection, and examine the reasons for the failure of evaluators usually thought of as being robust. We conclude that cross-validation with a low number of folds is the best choice for directly estimating the performance of a model, whereas using bootstrapping or cross validation with a large number of folds is better for model selection purposes. Overall, we find that existing benchmarks for few-shot learning are not designed in such a way that one can get a reliable picture of how effectively methods can be used on individual tasks.
Meta Omnium: A Benchmark for General-Purpose Learning-to-Learn
May 12, 2023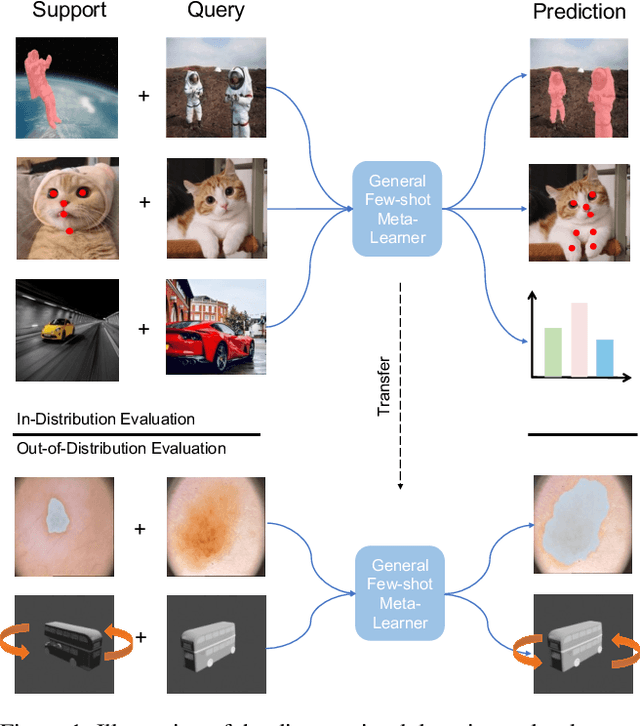

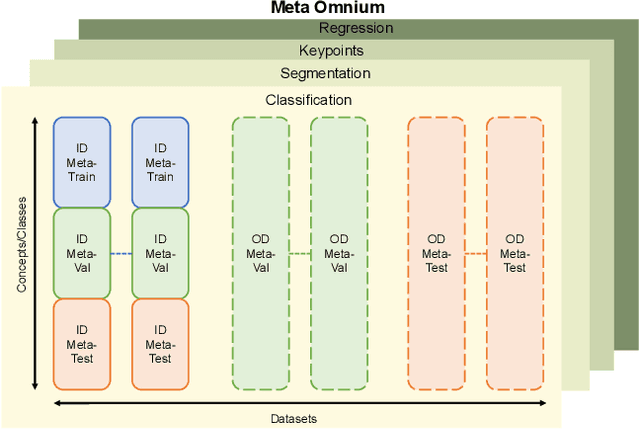
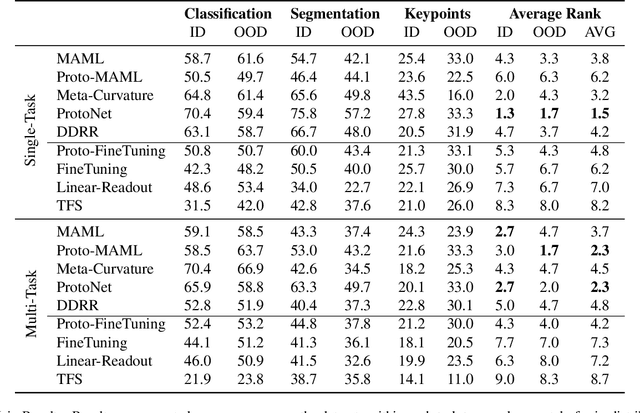
Meta-learning and other approaches to few-shot learning are widely studied for image recognition, and are increasingly applied to other vision tasks such as pose estimation and dense prediction. This naturally raises the question of whether there is any few-shot meta-learning algorithm capable of generalizing across these diverse task types? To support the community in answering this question, we introduce Meta Omnium, a dataset-of-datasets spanning multiple vision tasks including recognition, keypoint localization, semantic segmentation and regression. We experiment with popular few-shot meta-learning baselines and analyze their ability to generalize across tasks and to transfer knowledge between them. Meta Omnium enables meta-learning researchers to evaluate model generalization to a much wider array of tasks than previously possible, and provides a single framework for evaluating meta-learners across a wide suite of vision applications in a consistent manner.
Effectiveness of Debiasing Techniques: An Indigenous Qualitative Analysis
Apr 17, 2023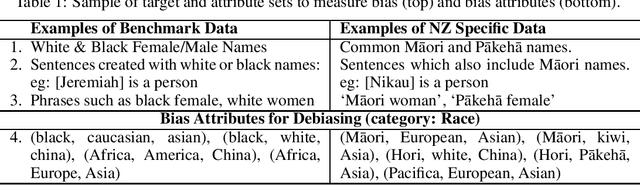
An indigenous perspective on the effectiveness of debiasing techniques for pre-trained language models (PLMs) is presented in this paper. The current techniques used to measure and debias PLMs are skewed towards the US racial biases and rely on pre-defined bias attributes (e.g. "black" vs "white"). Some require large datasets and further pre-training. Such techniques are not designed to capture the underrepresented indigenous populations in other countries, such as M\=aori in New Zealand. Local knowledge and understanding must be incorporated to ensure unbiased algorithms, especially when addressing a resource-restricted society.
* accepted with invite to present
Amortised Invariance Learning for Contrastive Self-Supervision
Feb 24, 2023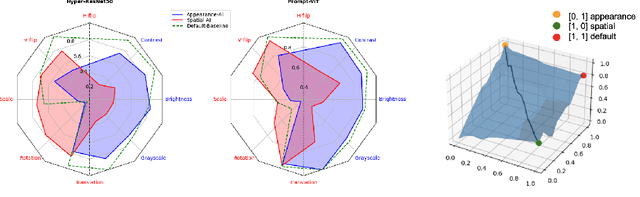
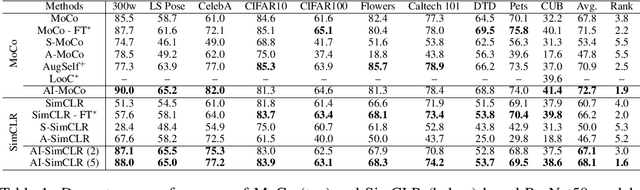
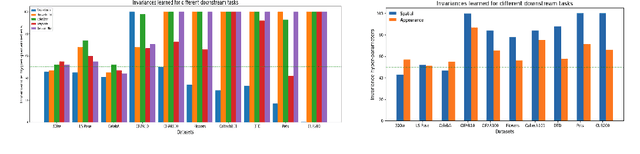

Contrastive self-supervised learning methods famously produce high quality transferable representations by learning invariances to different data augmentations. Invariances established during pre-training can be interpreted as strong inductive biases. However these may or may not be helpful, depending on if they match the invariance requirements of downstream tasks or not. This has led to several attempts to learn task-specific invariances during pre-training, however, these methods are highly compute intensive and tedious to train. We introduce the notion of amortised invariance learning for contrastive self supervision. In the pre-training stage, we parameterize the feature extractor by differentiable invariance hyper-parameters that control the invariances encoded by the representation. Then, for any downstream task, both linear readout and task-specific invariance requirements can be efficiently and effectively learned by gradient-descent. We evaluate the notion of amortised invariances for contrastive learning over two different modalities: vision and audio, on two widely-used contrastive learning methods in vision: SimCLR and MoCo-v2 with popular architectures like ResNets and Vision Transformers, and SimCLR with ResNet-18 for audio. We show that our amortised features provide a reliable way to learn diverse downstream tasks with different invariance requirements, while using a single feature and avoiding task-specific pre-training. This provides an exciting perspective that opens up new horizons in the field of general purpose representation learning.
Attacking Adversarial Defences by Smoothing the Loss Landscape
Aug 05, 2022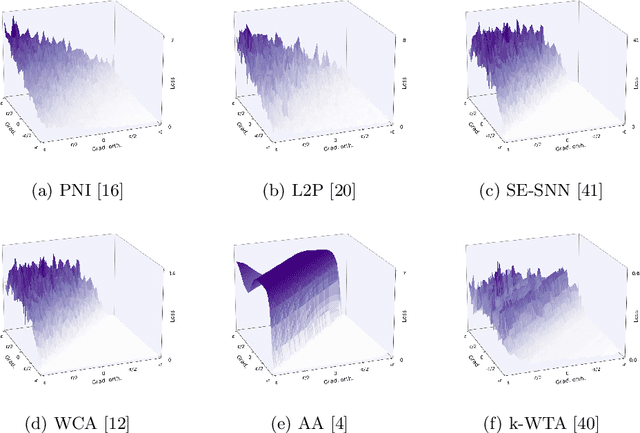
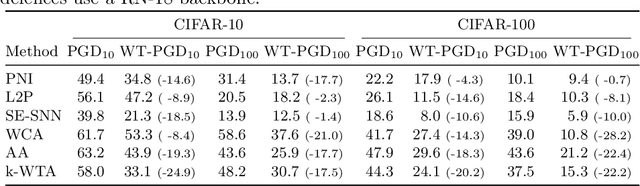
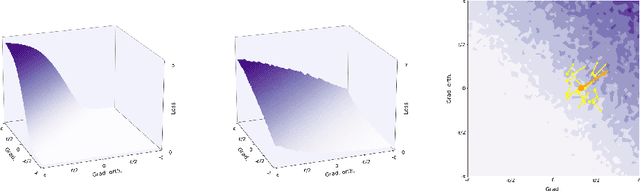
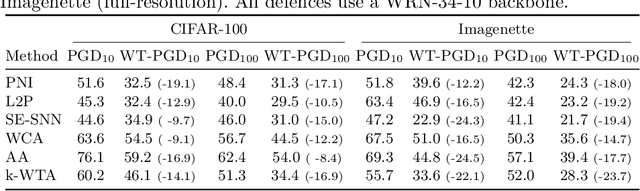
This paper investigates a family of methods for defending against adversarial attacks that owe part of their success to creating a noisy, discontinuous, or otherwise rugged loss landscape that adversaries find difficult to navigate. A common, but not universal, way to achieve this effect is via the use of stochastic neural networks. We show that this is a form of gradient obfuscation, and propose a general extension to gradient-based adversaries based on the Weierstrass transform, which smooths the surface of the loss function and provides more reliable gradient estimates. We further show that the same principle can strengthen gradient-free adversaries. We demonstrate the efficacy of our loss-smoothing method against both stochastic and non-stochastic adversarial defences that exhibit robustness due to this type of obfuscation. Furthermore, we provide analysis of how it interacts with Expectation over Transformation; a popular gradient-sampling method currently used to attack stochastic defences.
HyperInvariances: Amortizing Invariance Learning
Jul 17, 2022
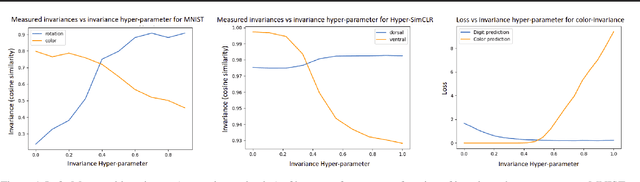

Providing invariances in a given learning task conveys a key inductive bias that can lead to sample-efficient learning and good generalisation, if correctly specified. However, the ideal invariances for many problems of interest are often not known, which has led both to a body of engineering lore as well as attempts to provide frameworks for invariance learning. However, invariance learning is expensive and data intensive for popular neural architectures. We introduce the notion of amortizing invariance learning. In an up-front learning phase, we learn a low-dimensional manifold of feature extractors spanning invariance to different transformations using a hyper-network. Then, for any problem of interest, both model and invariance learning are rapid and efficient by fitting a low-dimensional invariance descriptor an output head. Empirically, this framework can identify appropriate invariances in different downstream tasks and lead to comparable or better test performance than conventional approaches. Our HyperInvariance framework is also theoretically appealing as it enables generalisation-bounds that provide an interesting new operating point in the trade-off between model fit and complexity.
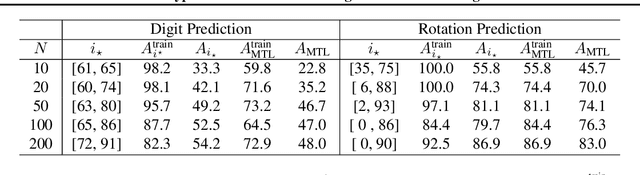
Lessons learned from the NeurIPS 2021 MetaDL challenge: Backbone fine-tuning without episodic meta-learning dominates for few-shot learning image classification
Jun 15, 2022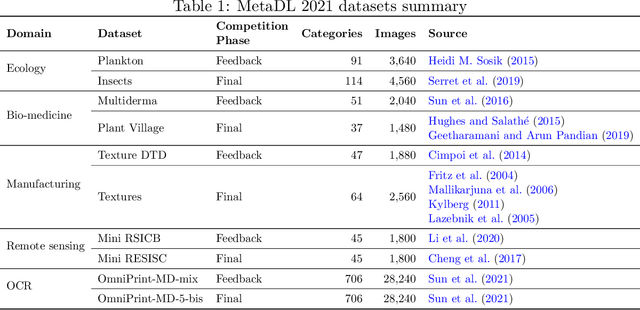

Although deep neural networks are capable of achieving performance superior to humans on various tasks, they are notorious for requiring large amounts of data and computing resources, restricting their success to domains where such resources are available. Metalearning methods can address this problem by transferring knowledge from related tasks, thus reducing the amount of data and computing resources needed to learn new tasks. We organize the MetaDL competition series, which provide opportunities for research groups all over the world to create and experimentally assess new meta-(deep)learning solutions for real problems. In this paper, authored collaboratively between the competition organizers and the top-ranked participants, we describe the design of the competition, the datasets, the best experimental results, as well as the top-ranked methods in the NeurIPS 2021 challenge, which attracted 15 active teams who made it to the final phase (by outperforming the baseline), making over 100 code submissions during the feedback phase. The solutions of the top participants have been open-sourced. The lessons learned include that learning good representations is essential for effective transfer learning.
Meta Mirror Descent: Optimiser Learning for Fast Convergence
Mar 05, 2022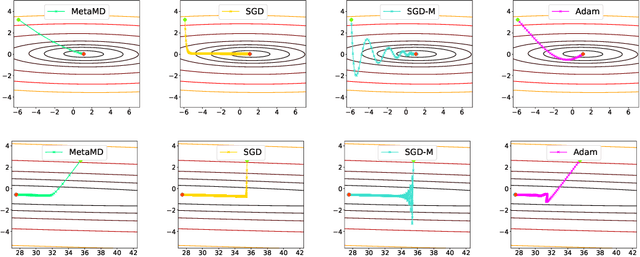
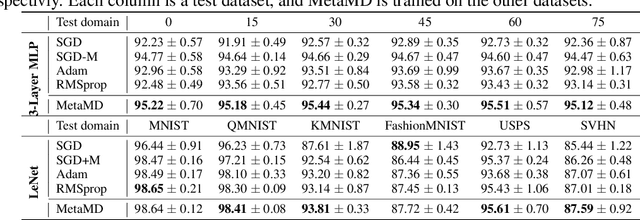
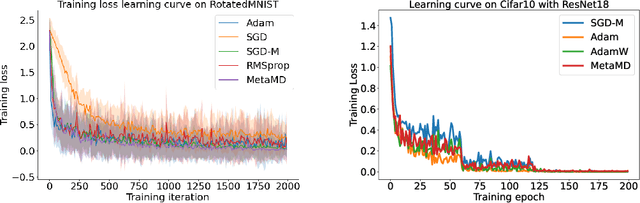
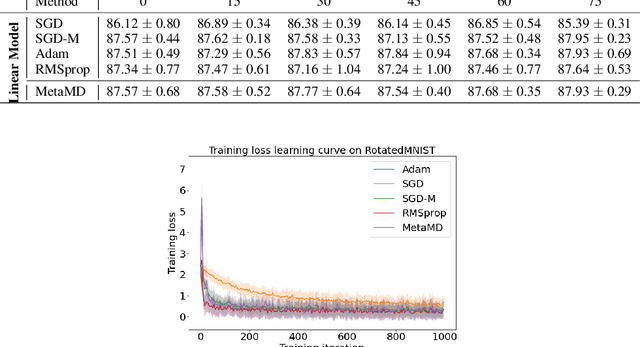
Optimisers are an essential component for training machine learning models, and their design influences learning speed and generalisation. Several studies have attempted to learn more effective gradient-descent optimisers via solving a bi-level optimisation problem where generalisation error is minimised with respect to optimiser parameters. However, most existing optimiser learning methods are intuitively motivated, without clear theoretical support. We take a different perspective starting from mirror descent rather than gradient descent, and meta-learning the corresponding Bregman divergence. Within this paradigm, we formalise a novel meta-learning objective of minimising the regret bound of learning. The resulting framework, termed Meta Mirror Descent (MetaMD), learns to accelerate optimisation speed. Unlike many meta-learned optimisers, it also supports convergence and generalisation guarantees and uniquely does so without requiring validation data. We evaluate our framework on a variety of tasks and architectures in terms of convergence rate and generalisation error and demonstrate strong performance.
Finding lost DG: Explaining domain generalization via model complexity
Feb 01, 2022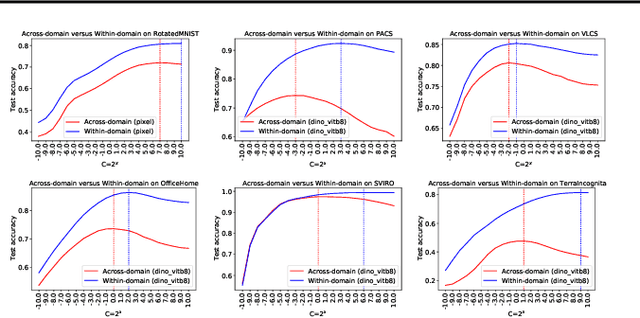
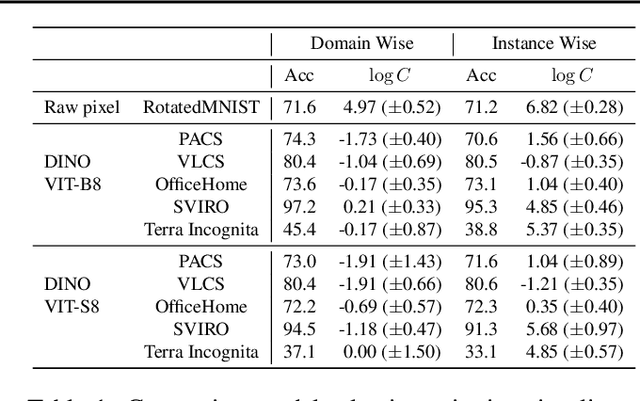
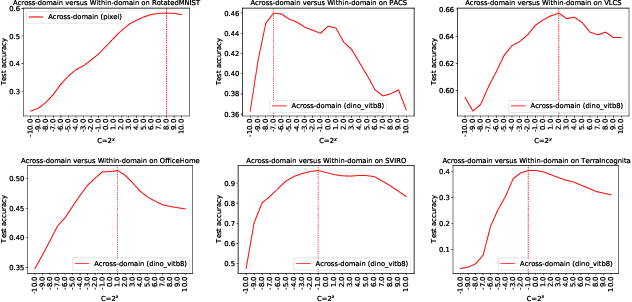
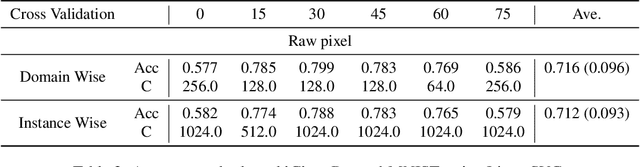
The domain generalization (DG) problem setting challenges a model trained on multiple known data distributions to generalise well on unseen data distributions. Due to its practical importance, a large number of methods have been proposed to address this challenge. However much of the work in general purpose DG is heuristically motivated, as the DG problem is hard to model formally; and recent evaluations have cast doubt on existing methods' practical efficacy -- in particular compared to a well tuned empirical risk minimisation baseline. We present a novel learning-theoretic generalisation bound for DG that bounds unseen domain generalisation performance in terms of the model's Rademacher complexity. Based on this, we conjecture that existing methods' efficacy or lack thereof is largely determined by an empirical risk vs predictor complexity trade-off, and demonstrate that their performance variability can be explained in these terms. Algorithmically, this analysis suggests that domain generalisation should be achieved by simply performing regularised ERM with a leave-one-domain-out cross-validation objective. Empirical results on the DomainBed benchmark corroborate this.