 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimothy Hospedales
VL-ICL Bench: The Devil in the Details of Benchmarking Multimodal In-Context Learning
Mar 19, 2024
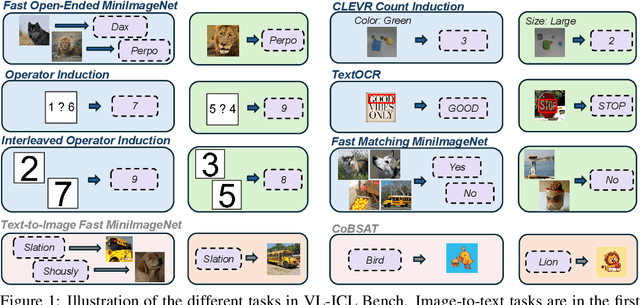

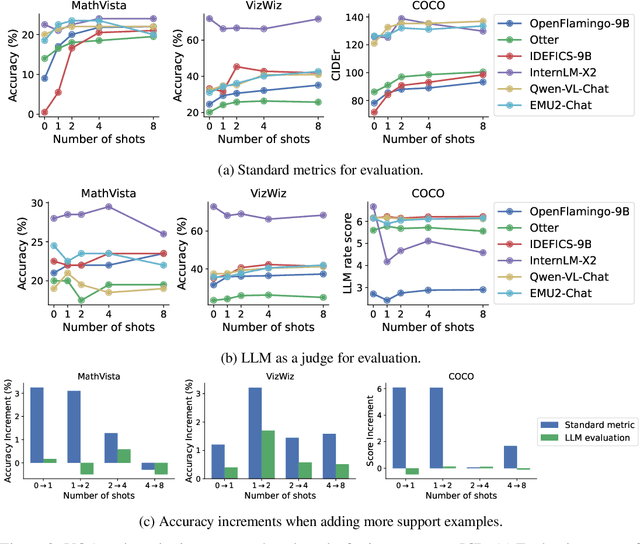
Large language models (LLMs) famously exhibit emergent in-context learning (ICL) -- the ability to rapidly adapt to new tasks using few-shot examples provided as a prompt, without updating the model's weights. Built on top of LLMs, vision large language models (VLLMs) have advanced significantly in areas such as recognition, reasoning, and grounding. However, investigations into \emph{multimodal ICL} have predominantly focused on few-shot visual question answering (VQA), and image captioning, which we will show neither exploit the strengths of ICL, nor test its limitations. The broader capabilities and limitations of multimodal ICL remain under-explored. In this study, we introduce a comprehensive benchmark VL-ICL Bench for multimodal in-context learning, encompassing a broad spectrum of tasks that involve both images and text as inputs and outputs, and different types of challenges, from {perception to reasoning and long context length}. We evaluate the abilities of state-of-the-art VLLMs against this benchmark suite, revealing their diverse strengths and weaknesses, and showing that even the most advanced models, such as GPT-4, find the tasks challenging. By highlighting a range of new ICL tasks, and the associated strengths and limitations of existing models, we hope that our dataset will inspire future work on enhancing the in-context learning capabilities of VLLMs, as well as inspire new applications that leverage VLLM ICL. The code and dataset are available at https://github.com/ys-zong/VL-ICL.
SketchINR: A First Look into Sketches as Implicit Neural Representations
Mar 14, 2024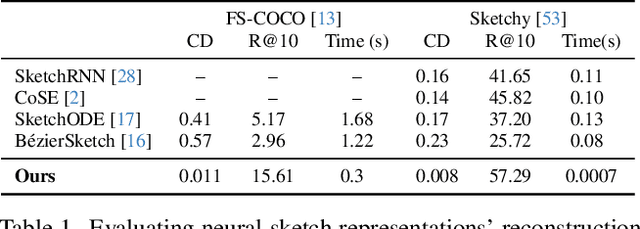
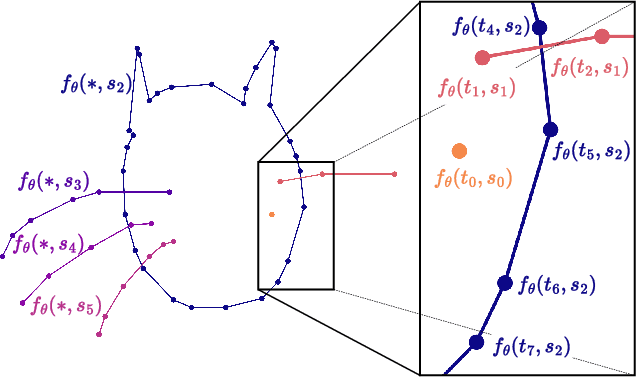
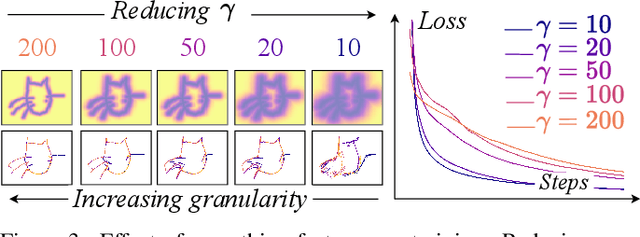
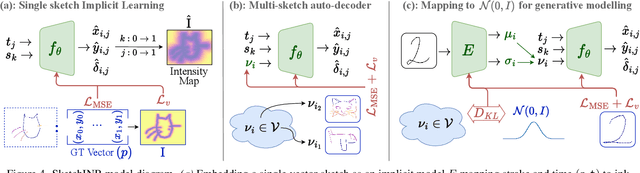
We propose SketchINR, to advance the representation of vector sketches with implicit neural models. A variable length vector sketch is compressed into a latent space of fixed dimension that implicitly encodes the underlying shape as a function of time and strokes. The learned function predicts the $xy$ point coordinates in a sketch at each time and stroke. Despite its simplicity, SketchINR outperforms existing representations at multiple tasks: (i) Encoding an entire sketch dataset into a fixed size latent vector, SketchINR gives $60\times$ and $10\times$ data compression over raster and vector sketches, respectively. (ii) SketchINR's auto-decoder provides a much higher-fidelity representation than other learned vector sketch representations, and is uniquely able to scale to complex vector sketches such as FS-COCO. (iii) SketchINR supports parallelisation that can decode/render $\sim$$100\times$ faster than other learned vector representations such as SketchRNN. (iv) SketchINR, for the first time, emulates the human ability to reproduce a sketch with varying abstraction in terms of number and complexity of strokes. As a first look at implicit sketches, SketchINR's compact high-fidelity representation will support future work in modelling long and complex sketches.
Safety Fine-Tuning at (Almost) No Cost: A Baseline for Vision Large Language Models
Feb 03, 2024Current vision large language models (VLLMs) exhibit remarkable capabilities yet are prone to generate harmful content and are vulnerable to even the simplest jailbreaking attacks. Our initial analysis finds that this is due to the presence of harmful data during vision-language instruction fine-tuning, and that VLLM fine-tuning can cause forgetting of safety alignment previously learned by the underpinning LLM. To address this issue, we first curate a vision-language safe instruction-following dataset VLGuard covering various harmful categories. Our experiments demonstrate that integrating this dataset into standard vision-language fine-tuning or utilizing it for post-hoc fine-tuning effectively safety aligns VLLMs. This alignment is achieved with minimal impact on, or even enhancement of, the models' helpfulness. The versatility of our safety fine-tuning dataset makes it a valuable resource for safety-testing existing VLLMs, training new models or safeguarding pre-trained VLLMs. Empirical results demonstrate that fine-tuned VLLMs effectively reject unsafe instructions and substantially reduce the success rates of several black-box adversarial attacks, which approach zero in many cases. The code and dataset are available at https://github.com/ys-zong/VLGuard.
DemoFusion: Democratising High-Resolution Image Generation With No $$$
Nov 24, 2023High-resolution image generation with Generative Artificial Intelligence (GenAI) has immense potential but, due to the enormous capital investment required for training, it is increasingly centralised to a few large corporations, and hidden behind paywalls. This paper aims to democratise high-resolution GenAI by advancing the frontier of high-resolution generation while remaining accessible to a broad audience. We demonstrate that existing Latent Diffusion Models (LDMs) possess untapped potential for higher-resolution image generation. Our novel DemoFusion framework seamlessly extends open-source GenAI models, employing Progressive Upscaling, Skip Residual, and Dilated Sampling mechanisms to achieve higher-resolution image generation. The progressive nature of DemoFusion requires more passes, but the intermediate results can serve as "previews", facilitating rapid prompt iteration.
Sketch-based Video Object Segmentation: Benchmark and Analysis
Nov 13, 2023Reference-based video object segmentation is an emerging topic which aims to segment the corresponding target object in each video frame referred by a given reference, such as a language expression or a photo mask. However, language expressions can sometimes be vague in conveying an intended concept and ambiguous when similar objects in one frame are hard to distinguish by language. Meanwhile, photo masks are costly to annotate and less practical to provide in a real application. This paper introduces a new task of sketch-based video object segmentation, an associated benchmark, and a strong baseline. Our benchmark includes three datasets, Sketch-DAVIS16, Sketch-DAVIS17 and Sketch-YouTube-VOS, which exploit human-drawn sketches as an informative yet low-cost reference for video object segmentation. We take advantage of STCN, a popular baseline of semi-supervised VOS task, and evaluate what the most effective design for incorporating a sketch reference is. Experimental results show sketch is more effective yet annotation-efficient than other references, such as photo masks, language and scribble.
Is Scaling Learned Optimizers Worth It? Evaluating The Value of VeLO's 4000 TPU Months
Oct 27, 2023We analyze VeLO (versatile learned optimizer), the largest scale attempt to train a general purpose "foundational" optimizer to date. VeLO was trained on thousands of machine learning tasks using over 4000 TPU months with the goal of producing an optimizer capable of generalizing to new problems while being hyperparameter free, and outperforming industry standards such as Adam. We independently evaluate VeLO on the MLCommons optimizer benchmark suite. We find that, contrary to initial claims: (1) VeLO has a critical hyperparameter that needs problem-specific tuning, (2) VeLO does not necessarily outperform competitors in quality of solution found, and (3) VeLO is not faster than competing optimizers at reducing the training loss. These observations call into question VeLO's generality and the value of the investment in training it.
FairTune: Optimizing Parameter Efficient Fine Tuning for Fairness in Medical Image Analysis
Oct 08, 2023Training models with robust group fairness properties is crucial in ethically sensitive application areas such as medical diagnosis. Despite the growing body of work aiming to minimise demographic bias in AI, this problem remains challenging. A key reason for this challenge is the fairness generalisation gap: High-capacity deep learning models can fit all training data nearly perfectly, and thus also exhibit perfect fairness during training. In this case, bias emerges only during testing when generalisation performance differs across subgroups. This motivates us to take a bi-level optimisation perspective on fair learning: Optimising the learning strategy based on validation fairness. Specifically, we consider the highly effective workflow of adapting pre-trained models to downstream medical imaging tasks using parameter-efficient fine-tuning (PEFT) techniques. There is a trade-off between updating more parameters, enabling a better fit to the task of interest vs. fewer parameters, potentially reducing the generalisation gap. To manage this tradeoff, we propose FairTune, a framework to optimise the choice of PEFT parameters with respect to fairness. We demonstrate empirically that FairTune leads to improved fairness on a range of medical imaging datasets.
FedL2P: Federated Learning to Personalize
Oct 03, 2023
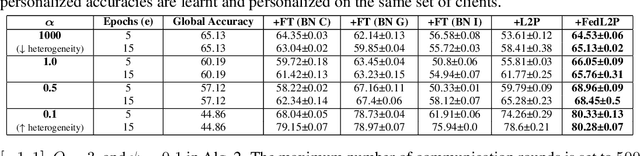
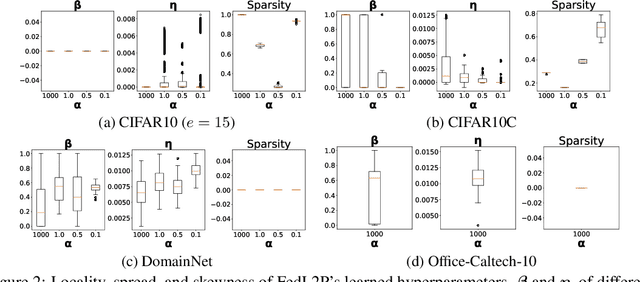
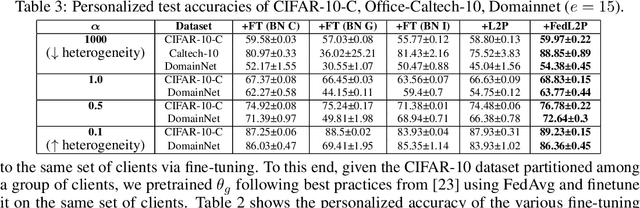
Federated learning (FL) research has made progress in developing algorithms for distributed learning of global models, as well as algorithms for local personalization of those common models to the specifics of each client's local data distribution. However, different FL problems may require different personalization strategies, and it may not even be possible to define an effective one-size-fits-all personalization strategy for all clients: depending on how similar each client's optimal predictor is to that of the global model, different personalization strategies may be preferred. In this paper, we consider the federated meta-learning problem of learning personalization strategies. Specifically, we consider meta-nets that induce the batch-norm and learning rate parameters for each client given local data statistics. By learning these meta-nets through FL, we allow the whole FL network to collaborate in learning a customized personalization strategy for each client. Empirical results show that this framework improves on a range of standard hand-crafted personalization baselines in both label and feature shift situations.
Fool Your (Vision and) Language Model With Embarrassingly Simple Permutations
Oct 02, 2023Large language and vision-language models are rapidly being deployed in practice thanks to their impressive capabilities in instruction following, in-context learning, and so on. This raises an urgent need to carefully analyse their robustness so that stakeholders can understand if and when such models are trustworthy enough to be relied upon in any given application. In this paper, we highlight a specific vulnerability in popular models, namely permutation sensitivity in multiple-choice question answering (MCQA). Specifically, we show empirically that popular models are vulnerable to adversarial permutation in answer sets for multiple-choice prompting, which is surprising as models should ideally be as invariant to prompt permutation as humans are. These vulnerabilities persist across various model sizes, and exist in very recent language and vision-language models. Code is available at \url{https://github.com/ys-zong/FoolyourVLLMs}.
BayesDLL: Bayesian Deep Learning Library
Sep 22, 2023We release a new Bayesian neural network library for PyTorch for large-scale deep networks. Our library implements mainstream approximate Bayesian inference algorithms: variational inference, MC-dropout, stochastic-gradient MCMC, and Laplace approximation. The main differences from other existing Bayesian neural network libraries are as follows: 1) Our library can deal with very large-scale deep networks including Vision Transformers (ViTs). 2) We need virtually zero code modifications for users (e.g., the backbone network definition codes do not neet to be modified at all). 3) Our library also allows the pre-trained model weights to serve as a prior mean, which is very useful for performing Bayesian inference with the large-scale foundation models like ViTs that are hard to optimise from scratch with the downstream data alone. Our code is publicly available at: \url{https://github.com/SamsungLabs/BayesDLL}\footnote{A mirror repository is also available at: \url{https://github.com/minyoungkim21/BayesDLL}.}.