 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYongshuo Zong
VL-ICL Bench: The Devil in the Details of Benchmarking Multimodal In-Context Learning
Mar 19, 2024
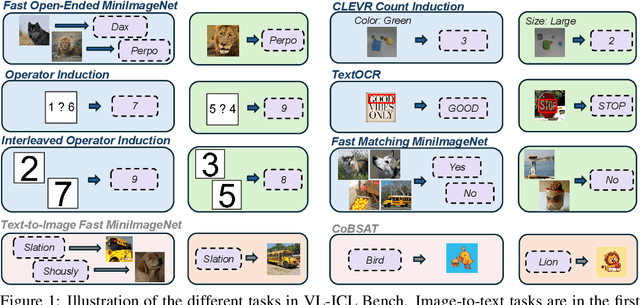

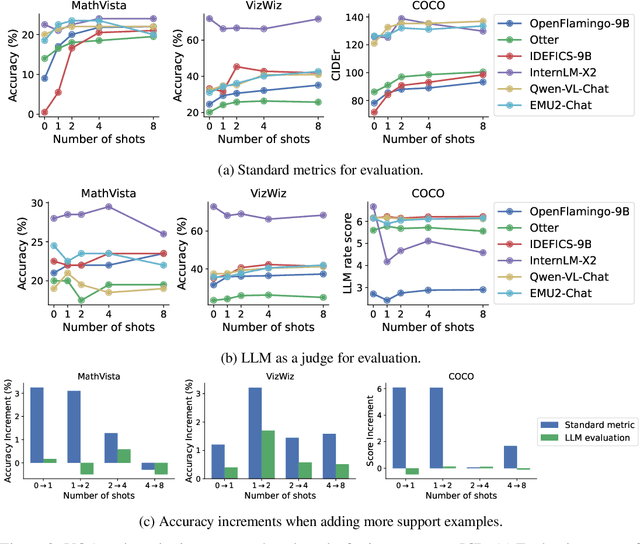
Large language models (LLMs) famously exhibit emergent in-context learning (ICL) -- the ability to rapidly adapt to new tasks using few-shot examples provided as a prompt, without updating the model's weights. Built on top of LLMs, vision large language models (VLLMs) have advanced significantly in areas such as recognition, reasoning, and grounding. However, investigations into \emph{multimodal ICL} have predominantly focused on few-shot visual question answering (VQA), and image captioning, which we will show neither exploit the strengths of ICL, nor test its limitations. The broader capabilities and limitations of multimodal ICL remain under-explored. In this study, we introduce a comprehensive benchmark VL-ICL Bench for multimodal in-context learning, encompassing a broad spectrum of tasks that involve both images and text as inputs and outputs, and different types of challenges, from {perception to reasoning and long context length}. We evaluate the abilities of state-of-the-art VLLMs against this benchmark suite, revealing their diverse strengths and weaknesses, and showing that even the most advanced models, such as GPT-4, find the tasks challenging. By highlighting a range of new ICL tasks, and the associated strengths and limitations of existing models, we hope that our dataset will inspire future work on enhancing the in-context learning capabilities of VLLMs, as well as inspire new applications that leverage VLLM ICL. The code and dataset are available at https://github.com/ys-zong/VL-ICL.
Safety Fine-Tuning at (Almost) No Cost: A Baseline for Vision Large Language Models
Feb 03, 2024Current vision large language models (VLLMs) exhibit remarkable capabilities yet are prone to generate harmful content and are vulnerable to even the simplest jailbreaking attacks. Our initial analysis finds that this is due to the presence of harmful data during vision-language instruction fine-tuning, and that VLLM fine-tuning can cause forgetting of safety alignment previously learned by the underpinning LLM. To address this issue, we first curate a vision-language safe instruction-following dataset VLGuard covering various harmful categories. Our experiments demonstrate that integrating this dataset into standard vision-language fine-tuning or utilizing it for post-hoc fine-tuning effectively safety aligns VLLMs. This alignment is achieved with minimal impact on, or even enhancement of, the models' helpfulness. The versatility of our safety fine-tuning dataset makes it a valuable resource for safety-testing existing VLLMs, training new models or safeguarding pre-trained VLLMs. Empirical results demonstrate that fine-tuned VLLMs effectively reject unsafe instructions and substantially reduce the success rates of several black-box adversarial attacks, which approach zero in many cases. The code and dataset are available at https://github.com/ys-zong/VLGuard.
What If the TV Was Off? Examining Counterfactual Reasoning Abilities of Multi-modal Language Models
Oct 10, 2023Counterfactual reasoning ability is one of the core abilities of human intelligence. This reasoning process involves the processing of alternatives to observed states or past events, and this process can improve our ability for planning and decision-making. In this work, we focus on benchmarking the counterfactual reasoning ability of multi-modal large language models. We take the question and answer pairs from the VQAv2 dataset and add one counterfactual presupposition to the questions, with the answer being modified accordingly. After generating counterfactual questions and answers using ChatGPT, we manually examine all generated questions and answers to ensure correctness. Over 2k counterfactual question and answer pairs are collected this way. We evaluate recent vision language models on our newly collected test dataset and found that all models exhibit a large performance drop compared to the results tested on questions without the counterfactual presupposition. This result indicates that there still exists space for developing vision language models. Apart from the vision language models, our proposed dataset can also serves as a benchmark for evaluating the ability of code generation LLMs, results demonstrate a large gap between GPT-4 and current open-source models. Our code and dataset are available at \url{https://github.com/Letian2003/C-VQA}.
Fool Your (Vision and) Language Model With Embarrassingly Simple Permutations
Oct 02, 2023Large language and vision-language models are rapidly being deployed in practice thanks to their impressive capabilities in instruction following, in-context learning, and so on. This raises an urgent need to carefully analyse their robustness so that stakeholders can understand if and when such models are trustworthy enough to be relied upon in any given application. In this paper, we highlight a specific vulnerability in popular models, namely permutation sensitivity in multiple-choice question answering (MCQA). Specifically, we show empirically that popular models are vulnerable to adversarial permutation in answer sets for multiple-choice prompting, which is surprising as models should ideally be as invariant to prompt permutation as humans are. These vulnerabilities persist across various model sizes, and exist in very recent language and vision-language models. Code is available at \url{https://github.com/ys-zong/FoolyourVLLMs}.
Meta Omnium: A Benchmark for General-Purpose Learning-to-Learn
May 12, 2023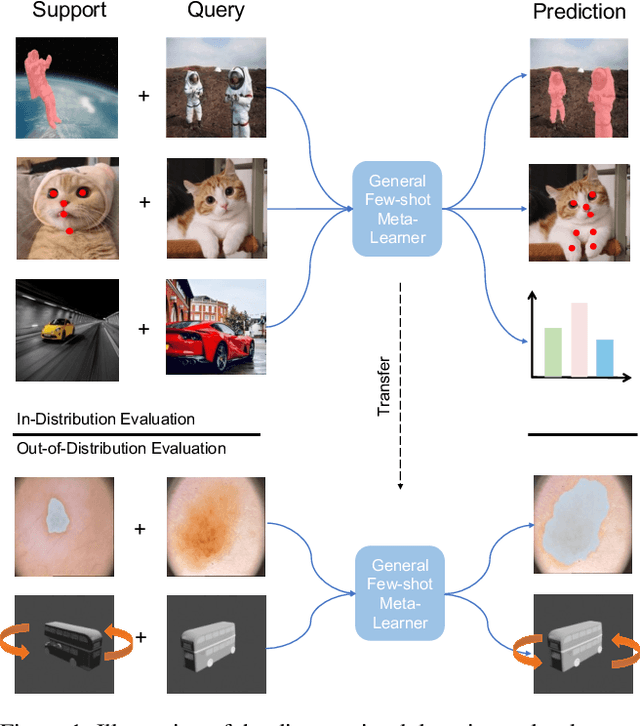

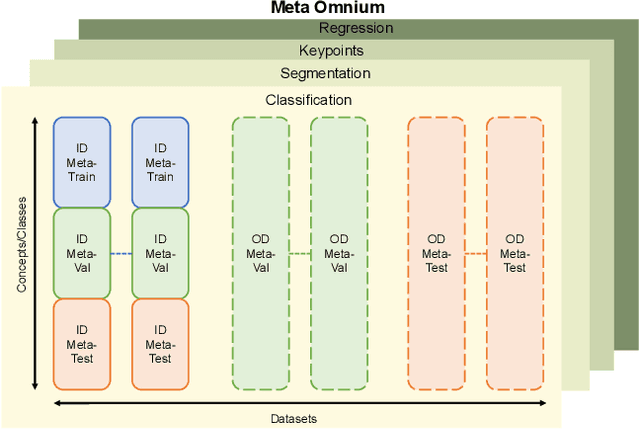
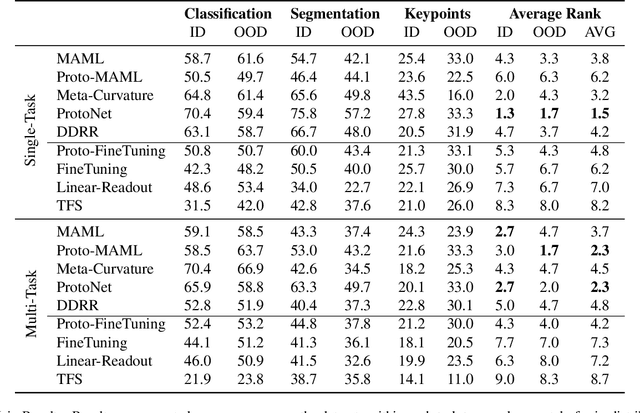
Meta-learning and other approaches to few-shot learning are widely studied for image recognition, and are increasingly applied to other vision tasks such as pose estimation and dense prediction. This naturally raises the question of whether there is any few-shot meta-learning algorithm capable of generalizing across these diverse task types? To support the community in answering this question, we introduce Meta Omnium, a dataset-of-datasets spanning multiple vision tasks including recognition, keypoint localization, semantic segmentation and regression. We experiment with popular few-shot meta-learning baselines and analyze their ability to generalize across tasks and to transfer knowledge between them. Meta Omnium enables meta-learning researchers to evaluate model generalization to a much wider array of tasks than previously possible, and provides a single framework for evaluating meta-learners across a wide suite of vision applications in a consistent manner.
Self-Supervised Multimodal Learning: A Survey
Mar 31, 2023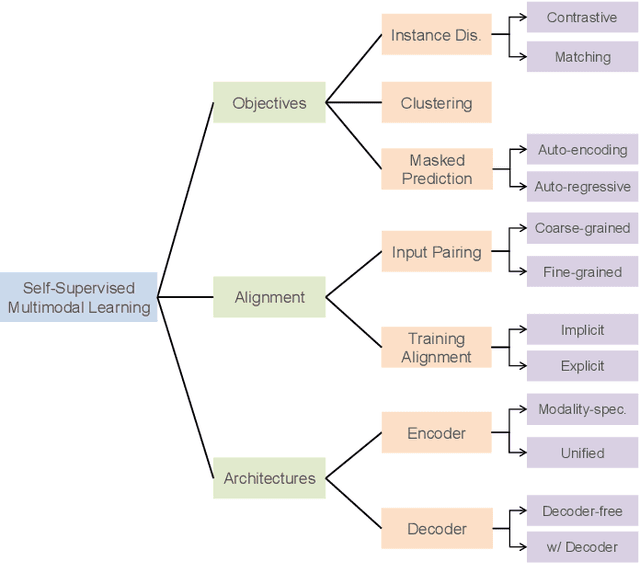
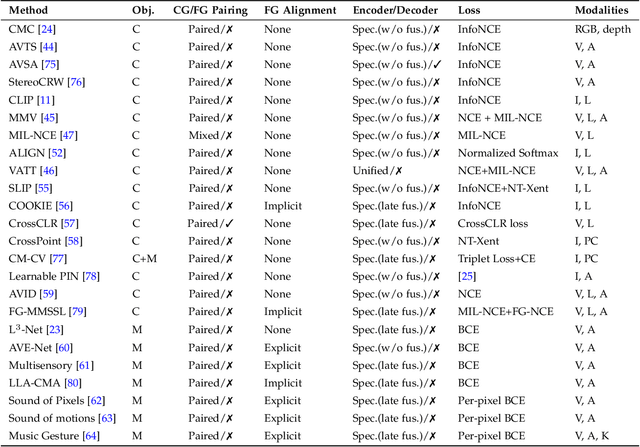
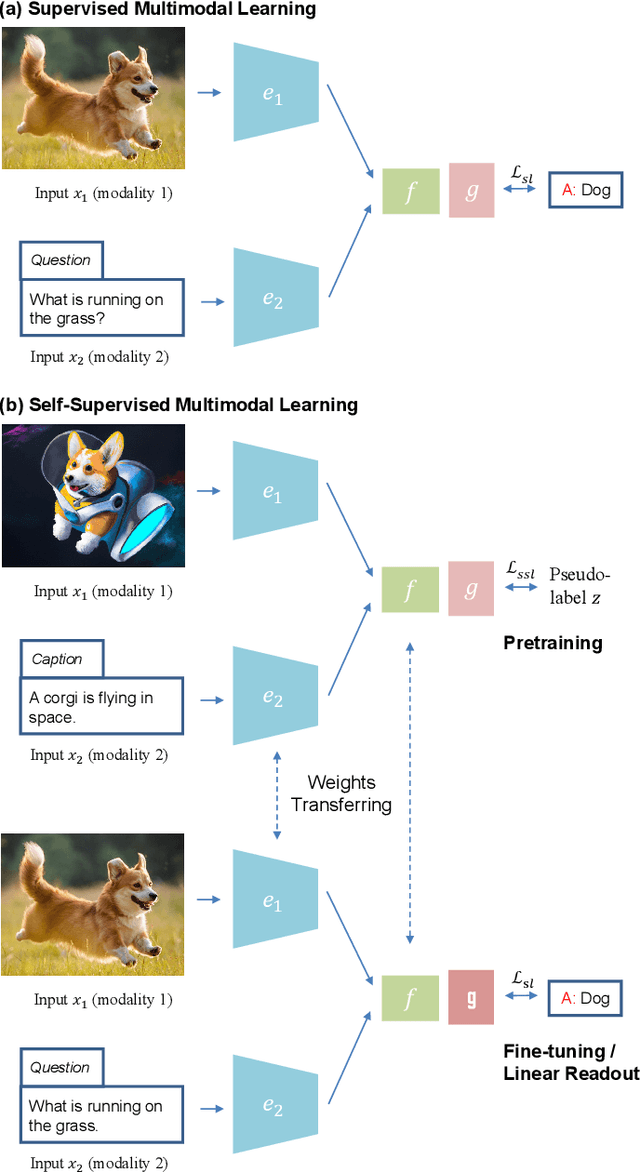

Multimodal learning, which aims to understand and analyze information from multiple modalities, has achieved substantial progress in the supervised regime in recent years. However, the heavy dependence on data paired with expensive human annotations impedes scaling up models. Meanwhile, given the availability of large-scale unannotated data in the wild, self-supervised learning has become an attractive strategy to alleviate the annotation bottleneck. Building on these two directions, self-supervised multimodal learning (SSML) provides ways to leverage supervision from raw multimodal data. In this survey, we provide a comprehensive review of the state-of-the-art in SSML, which we categorize along three orthogonal axes: objective functions, data alignment, and model architectures. These axes correspond to the inherent characteristics of self-supervised learning methods and multimodal data. Specifically, we classify training objectives into instance discrimination, clustering, and masked prediction categories. We also discuss multimodal input data pairing and alignment strategies during training. Finally, we review model architectures including the design of encoders, fusion modules, and decoders, which are essential components of SSML methods. We review downstream multimodal application tasks, reporting the concrete performance of the state-of-the-art image-text models and multimodal video models, and also review real-world applications of SSML algorithms in diverse fields such as healthcare, remote sensing, and machine translation. Finally, we discuss challenges and future directions for SSML. A collection of related resources can be found at: https://github.com/ys-zong/awesome-self-supervised-multimodal-learning.
MEDFAIR: Benchmarking Fairness for Medical Imaging
Oct 04, 2022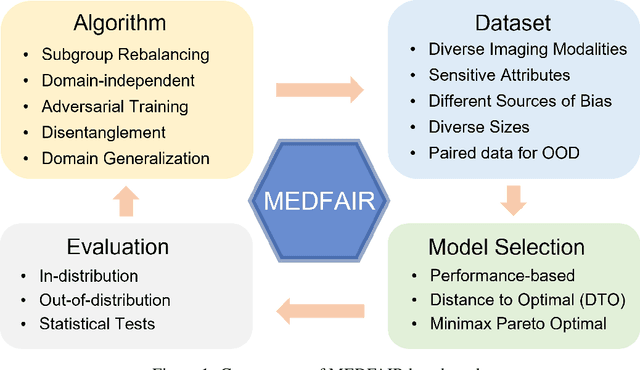
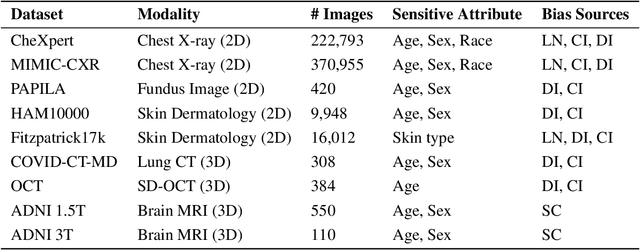
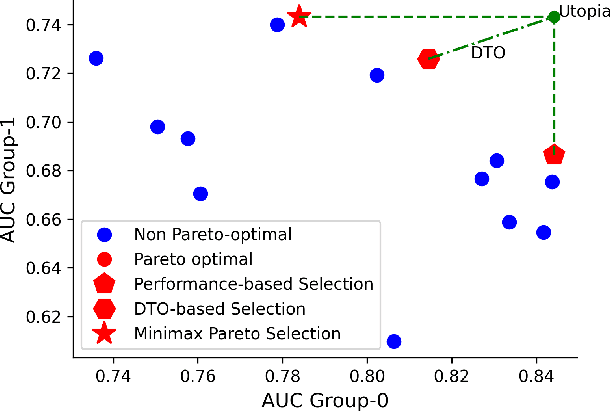
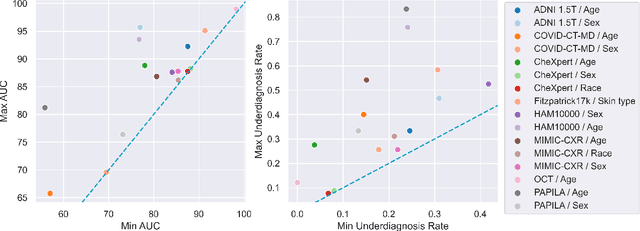
A multitude of work has shown that machine learning-based medical diagnosis systems can be biased against certain subgroups of people. This has motivated a growing number of bias mitigation algorithms that aim to address fairness issues in machine learning. However, it is difficult to compare their effectiveness in medical imaging for two reasons. First, there is little consensus on the criteria to assess fairness. Second, existing bias mitigation algorithms are developed under different settings, e.g., datasets, model selection strategies, backbones, and fairness metrics, making a direct comparison and evaluation based on existing results impossible. In this work, we introduce MEDFAIR, a framework to benchmark the fairness of machine learning models for medical imaging. MEDFAIR covers eleven algorithms from various categories, nine datasets from different imaging modalities, and three model selection criteria. Through extensive experiments, we find that the under-studied issue of model selection criterion can have a significant impact on fairness outcomes; while in contrast, state-of-the-art bias mitigation algorithms do not significantly improve fairness outcomes over empirical risk minimization (ERM) in both in-distribution and out-of-distribution settings. We evaluate fairness from various perspectives and make recommendations for different medical application scenarios that require different ethical principles. Our framework provides a reproducible and easy-to-use entry point for the development and evaluation of future bias mitigation algorithms in deep learning. Code is available at https://github.com/ys-zong/MEDFAIR.