 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoyson Lee
How Much Is Hidden in the NAS Benchmarks? Few-Shot Adaptation of a NAS Predictor
Nov 30, 2023
Neural architecture search has proven to be a powerful approach to designing and refining neural networks, often boosting their performance and efficiency over manually-designed variations, but comes with computational overhead. While there has been a considerable amount of research focused on lowering the cost of NAS for mainstream tasks, such as image classification, a lot of those improvements stem from the fact that those tasks are well-studied in the broader context. Consequently, applicability of NAS to emerging and under-represented domains is still associated with a relatively high cost and/or uncertainty about the achievable gains. To address this issue, we turn our focus towards the recent growth of publicly available NAS benchmarks in an attempt to extract general NAS knowledge, transferable across different tasks and search spaces. We borrow from the rich field of meta-learning for few-shot adaptation and carefully study applicability of those methods to NAS, with a special focus on the relationship between task-level correlation (domain shift) and predictor transferability; which we deem critical for improving NAS on diverse tasks. In our experiments, we use 6 NAS benchmarks in conjunction, spanning in total 16 NAS settings -- our meta-learning approach not only shows superior (or matching) performance in the cross-validation experiments but also successful extrapolation to a new search space and tasks.
FedL2P: Federated Learning to Personalize
Oct 03, 2023
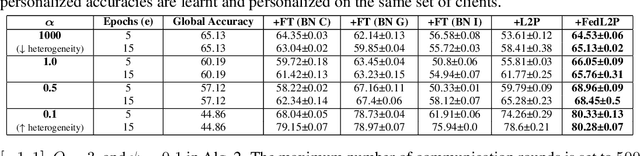
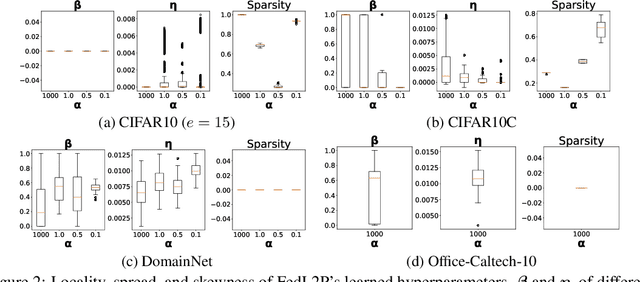
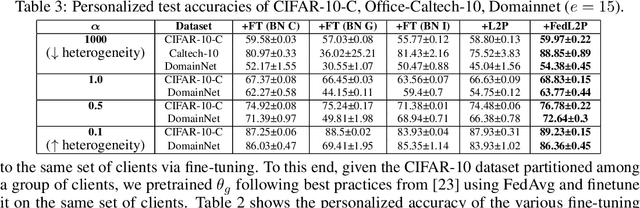
Federated learning (FL) research has made progress in developing algorithms for distributed learning of global models, as well as algorithms for local personalization of those common models to the specifics of each client's local data distribution. However, different FL problems may require different personalization strategies, and it may not even be possible to define an effective one-size-fits-all personalization strategy for all clients: depending on how similar each client's optimal predictor is to that of the global model, different personalization strategies may be preferred. In this paper, we consider the federated meta-learning problem of learning personalization strategies. Specifically, we consider meta-nets that induce the batch-norm and learning rate parameters for each client given local data statistics. By learning these meta-nets through FL, we allow the whole FL network to collaborate in learning a customized personalization strategy for each client. Empirical results show that this framework improves on a range of standard hand-crafted personalization baselines in both label and feature shift situations.
Meta-Learned Kernel For Blind Super-Resolution Kernel Estimation
Dec 15, 2022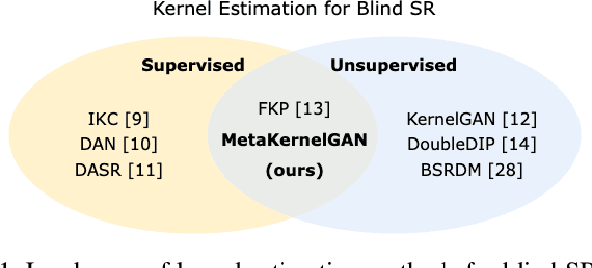
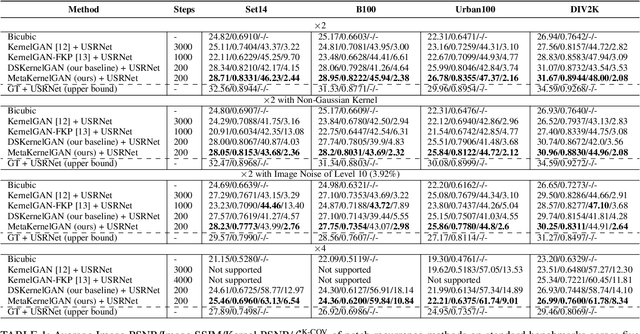
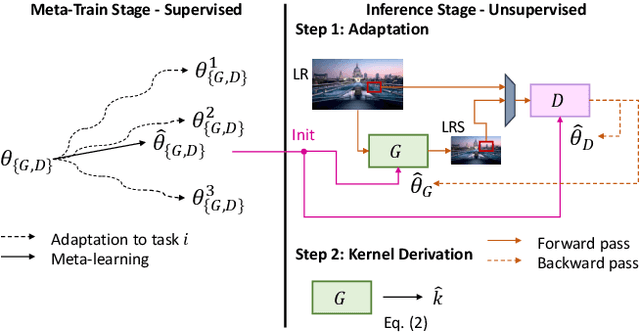
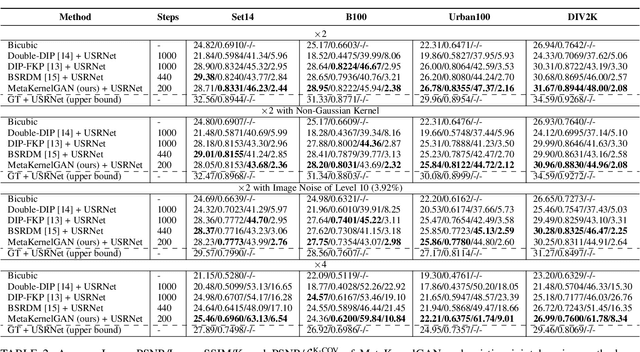
Recent image degradation estimation methods have enabled single-image super-resolution (SR) approaches to better upsample real-world images. Among these methods, explicit kernel estimation approaches have demonstrated unprecedented performance at handling unknown degradations. Nonetheless, a number of limitations constrain their efficacy when used by downstream SR models. Specifically, this family of methods yields i) excessive inference time due to long per-image adaptation times and ii) inferior image fidelity due to kernel mismatch. In this work, we introduce a learning-to-learn approach that meta-learns from the information contained in a distribution of images, thereby enabling significantly faster adaptation to new images with substantially improved performance in both kernel estimation and image fidelity. Specifically, we meta-train a kernel-generating GAN, named MetaKernelGAN, on a range of tasks, such that when a new image is presented, the generator starts from an informed kernel estimate and the discriminator starts with a strong capability to distinguish between patch distributions. Compared with state-of-the-art methods, our experiments show that MetaKernelGAN better estimates the magnitude and covariance of the kernel, leading to state-of-the-art blind SR results within a similar computational regime when combined with a non-blind SR model. Through supervised learning of an unsupervised learner, our method maintains the generalizability of the unsupervised learner, improves the optimization stability of kernel estimation, and hence image adaptation, and leads to a faster inference with a speedup between 14.24 to 102.1x over existing methods.
NAWQ-SR: A Hybrid-Precision NPU Engine for Efficient On-Device Super-Resolution
Dec 15, 2022
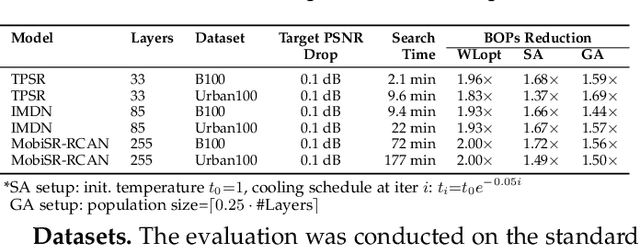
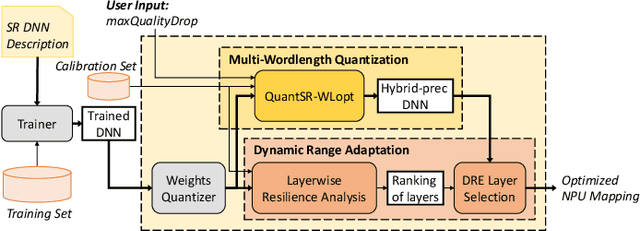
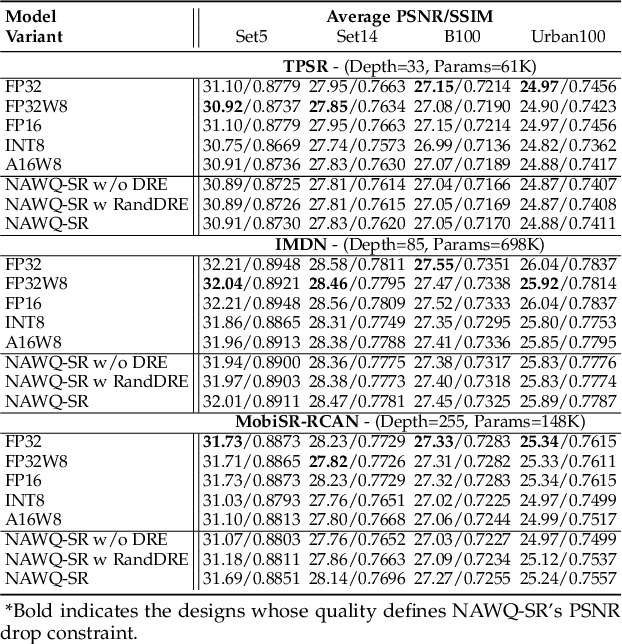
In recent years, image and video delivery systems have begun integrating deep learning super-resolution (SR) approaches, leveraging their unprecedented visual enhancement capabilities while reducing reliance on networking conditions. Nevertheless, deploying these solutions on mobile devices still remains an active challenge as SR models are excessively demanding with respect to workload and memory footprint. Despite recent progress on on-device SR frameworks, existing systems either penalize visual quality, lead to excessive energy consumption or make inefficient use of the available resources. This work presents NAWQ-SR, a novel framework for the efficient on-device execution of SR models. Through a novel hybrid-precision quantization technique and a runtime neural image codec, NAWQ-SR exploits the multi-precision capabilities of modern mobile NPUs in order to minimize latency, while meeting user-specified quality constraints. Moreover, NAWQ-SR selectively adapts the arithmetic precision at run time to equip the SR DNN's layers with wider representational power, improving visual quality beyond what was previously possible on NPUs. Altogether, NAWQ-SR achieves an average speedup of 7.9x, 3x and 1.91x over the state-of-the-art on-device SR systems that use heterogeneous processors (MobiSR), CPU (SplitSR) and NPU (XLSR), respectively. Furthermore, NAWQ-SR delivers an average of 3.2x speedup and 0.39 dB higher PSNR over status-quo INT8 NPU designs, but most importantly mitigates the negative effects of quantization on visual quality, setting a new state-of-the-art in the attainable quality of NPU-based SR.
Adaptable Butterfly Accelerator for Attention-based NNs via Hardware and Algorithm Co-design
Sep 20, 2022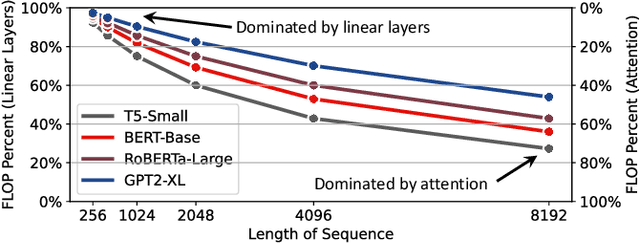
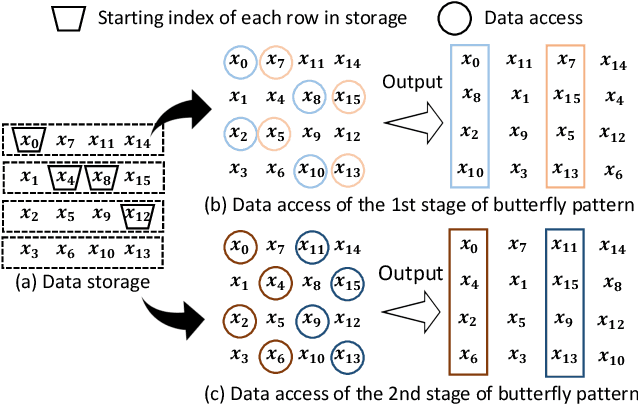
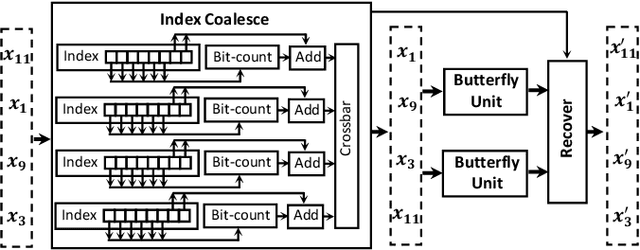
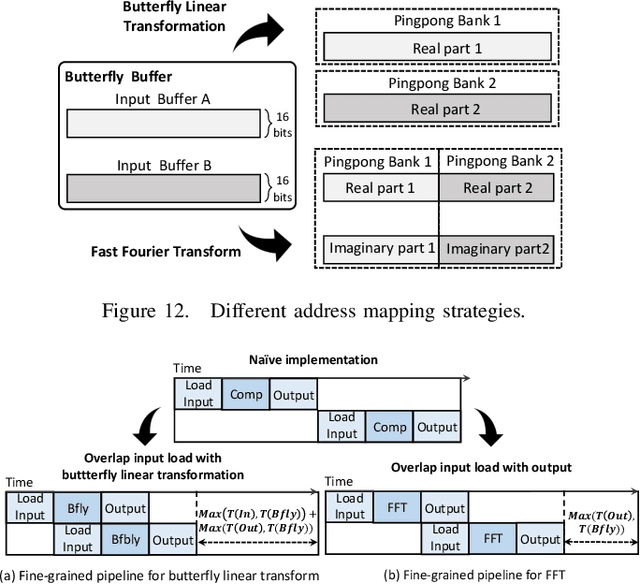
Attention-based neural networks have become pervasive in many AI tasks. Despite their excellent algorithmic performance, the use of the attention mechanism and feed-forward network (FFN) demands excessive computational and memory resources, which often compromises their hardware performance. Although various sparse variants have been introduced, most approaches only focus on mitigating the quadratic scaling of attention on the algorithm level, without explicitly considering the efficiency of mapping their methods on real hardware designs. Furthermore, most efforts only focus on either the attention mechanism or the FFNs but without jointly optimizing both parts, causing most of the current designs to lack scalability when dealing with different input lengths. This paper systematically considers the sparsity patterns in different variants from a hardware perspective. On the algorithmic level, we propose FABNet, a hardware-friendly variant that adopts a unified butterfly sparsity pattern to approximate both the attention mechanism and the FFNs. On the hardware level, a novel adaptable butterfly accelerator is proposed that can be configured at runtime via dedicated hardware control to accelerate different butterfly layers using a single unified hardware engine. On the Long-Range-Arena dataset, FABNet achieves the same accuracy as the vanilla Transformer while reducing the amount of computation by 10 to 66 times and the number of parameters 2 to 22 times. By jointly optimizing the algorithm and hardware, our FPGA-based butterfly accelerator achieves 14.2 to 23.2 times speedup over state-of-the-art accelerators normalized to the same computational budget. Compared with optimized CPU and GPU designs on Raspberry Pi 4 and Jetson Nano, our system is up to 273.8 and 15.1 times faster under the same power budget.
Temporal Kernel Consistency for Blind Video Super-Resolution
Aug 18, 2021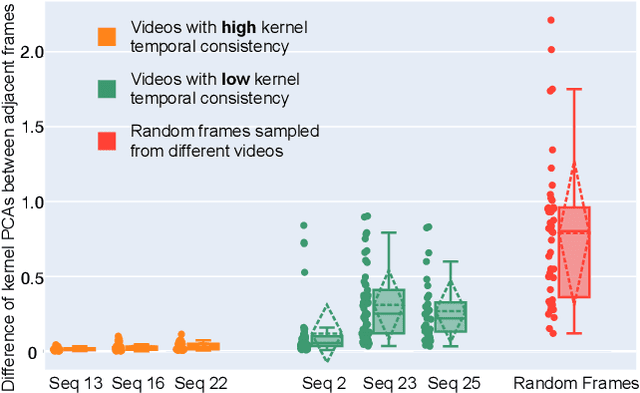
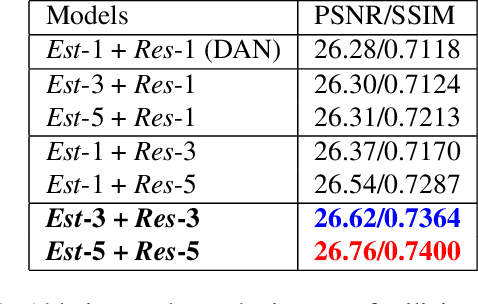

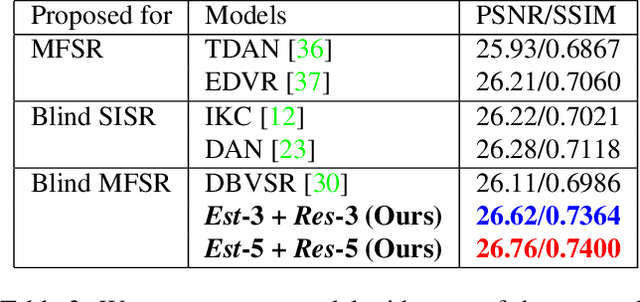
Deep learning-based blind super-resolution (SR) methods have recently achieved unprecedented performance in upscaling frames with unknown degradation. These models are able to accurately estimate the unknown downscaling kernel from a given low-resolution (LR) image in order to leverage the kernel during restoration. Although these approaches have largely been successful, they are predominantly image-based and therefore do not exploit the temporal properties of the kernels across multiple video frames. In this paper, we investigated the temporal properties of the kernels and highlighted its importance in the task of blind video super-resolution. Specifically, we measured the kernel temporal consistency of real-world videos and illustrated how the estimated kernels might change per frame in videos of varying dynamicity of the scene and its objects. With this new insight, we revisited previous popular video SR approaches, and showed that previous assumptions of using a fixed kernel throughout the restoration process can lead to visual artifacts when upscaling real-world videos. In order to counteract this, we tailored existing single-image and video SR techniques to leverage kernel consistency during both kernel estimation and video upscaling processes. Extensive experiments on synthetic and real-world videos show substantial restoration gains quantitatively and qualitatively, achieving the new state-of-the-art in blind video SR and underlining the potential of exploiting kernel temporal consistency.
Deep Neural Network-based Enhancement for Image and Video Streaming Systems: A Survey and Future Directions
Jun 07, 2021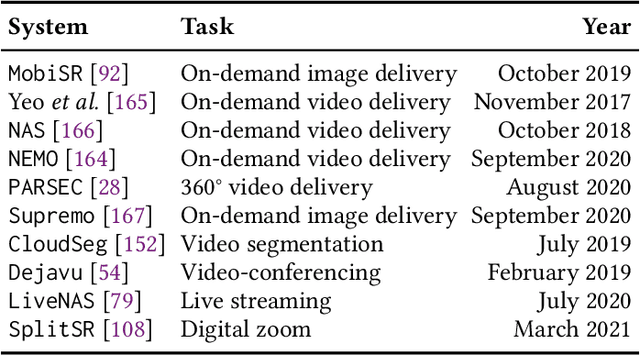
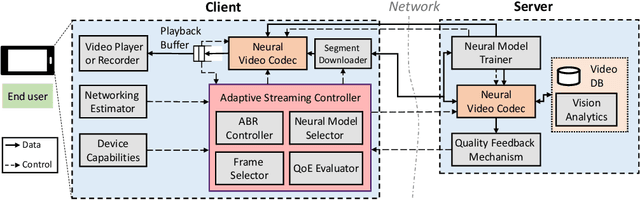

Internet-enabled smartphones and ultra-wide displays are transforming a variety of visual apps spanning from on-demand movies and 360{\deg} videos to video-conferencing and live streaming. However, robustly delivering visual content under fluctuating networking conditions on devices of diverse capabilities remains an open problem. In recent years, advances in the field of deep learning on tasks such as super-resolution and image enhancement have led to unprecedented performance in generating high-quality images from low-quality ones, a process we refer to as neural enhancement. In this paper, we survey state-of-the-art content delivery systems that employ neural enhancement as a key component in achieving both fast response time and high visual quality. We first present the components and architecture of existing content delivery systems, highlighting their challenges and motivating the use of neural enhancement models as a countermeasure. We then cover the deployment challenges of these models and analyze existing systems and their design decisions in efficiently overcoming these technical challenges. Additionally, we underline the key trends and common approaches across systems that target diverse use-cases. Finally, we present promising future directions based on the latest insights from deep learning research to further boost the quality of experience of content delivery systems.
Neural Enhancement in Content Delivery Systems: The State-of-the-Art and Future Directions
Oct 22, 2020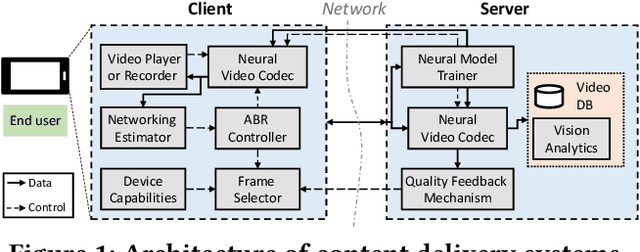


Internet-enabled smartphones and ultra-wide displays are transforming a variety of visual apps spanning from on-demand movies and 360-degree videos to video-conferencing and live streaming. However, robustly delivering visual content under fluctuating networking conditions on devices of diverse capabilities remains an open problem. In recent years, advances in the field of deep learning on tasks such as super-resolution and image enhancement have led to unprecedented performance in generating high-quality images from low-quality ones, a process we refer to as neural enhancement. In this paper, we survey state-of-the-art content delivery systems that employ neural enhancement as a key component in achieving both fast response time and high visual quality. We first present the deployment challenges of neural enhancement models. We then cover systems targeting diverse use-cases and analyze their design decisions in overcoming technical challenges. Moreover, we present promising directions based on the latest insights from deep learning research to further boost the quality of experience of these systems.
BRP-NAS: Prediction-based NAS using GCNs
Aug 10, 2020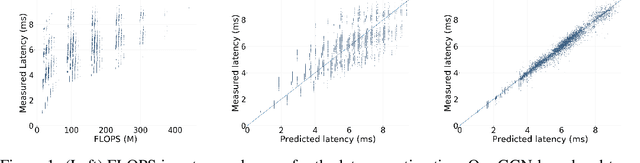


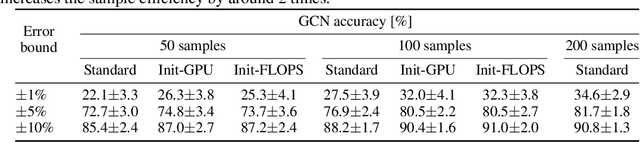
Neural architecture search (NAS) enables researchers to automatically explore broad design spaces in order to improve efficiency of neural networks. This efficiency is especially important in the case of on-device deployment, where improvements in accuracy should be balanced out with computational demands of a model. In practice, performance metrics of model are computationally expensive to obtain. Previous work uses a proxy (e.g. number of operations) or a layer-wise measurement of neural network layers to estimate end-to-end hardware performance but the imprecise prediction diminishes the quality of NAS. To address this problem, we propose BRP-NAS, an efficient hardware-aware NAS enabled by an accurate performance predictor-based on graph convolutional network (GCN). What is more, we investigate prediction quality on different metrics and show that sample-efficiency of the predictor-based NAS can be improved by considering binary relations of models and an iterative data selection strategy. We show that our proposed method outperforms all prior methods on both NAS-Bench-101 and NAS-Bench-201. Finally, to raise awareness of the fact that accurate latency estimation is not a trivial task, we release LatBench - a latency dataset of NAS-Bench-201 models running on a broad range of devices.
Journey Towards Tiny Perceptual Super-Resolution
Jul 08, 2020

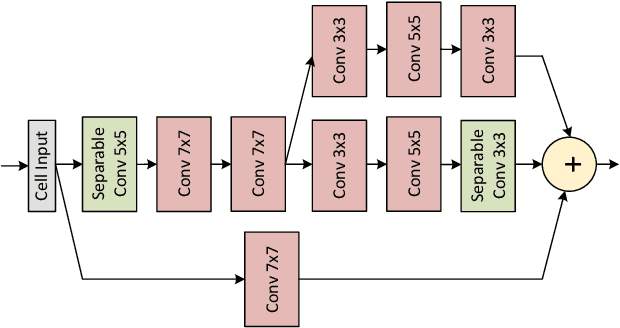
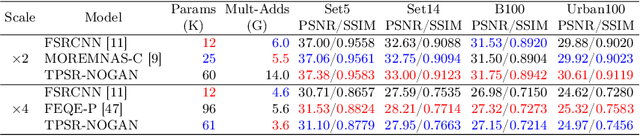
Recent works in single-image perceptual super-resolution (SR) have demonstrated unprecedented performance in generating realistic textures by means of deep convolutional networks. However, these convolutional models are excessively large and expensive, hindering their effective deployment to end devices. In this work, we propose a neural architecture search (NAS) approach that integrates NAS and generative adversarial networks (GANs) with recent advances in perceptual SR and pushes the efficiency of small perceptual SR models to facilitate on-device execution. Specifically, we search over the architectures of both the generator and the discriminator sequentially, highlighting the unique challenges and key observations of searching for an SR-optimized discriminator and comparing them with existing discriminator architectures in the literature. Our tiny perceptual SR (TPSR) models outperform SRGAN and EnhanceNet on both full-reference perceptual metric (LPIPS) and distortion metric (PSNR) while being up to 26.4$\times$ more memory efficient and 33.6$\times$ more compute efficient respectively.