 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoyi Wei
Assessing the Brittleness of Safety Alignment via Pruning and Low-Rank Modifications
Feb 07, 2024
Large language models (LLMs) show inherent brittleness in their safety mechanisms, as evidenced by their susceptibility to jailbreaking and even non-malicious fine-tuning. This study explores this brittleness of safety alignment by leveraging pruning and low-rank modifications. We develop methods to identify critical regions that are vital for safety guardrails, and that are disentangled from utility-relevant regions at both the neuron and rank levels. Surprisingly, the isolated regions we find are sparse, comprising about $3\%$ at the parameter level and $2.5\%$ at the rank level. Removing these regions compromises safety without significantly impacting utility, corroborating the inherent brittleness of the model's safety mechanisms. Moreover, we show that LLMs remain vulnerable to low-cost fine-tuning attacks even when modifications to the safety-critical regions are restricted. These findings underscore the urgent need for more robust safety strategies in LLMs.
IDO-VFI: Identifying Dynamics via Optical Flow Guidance for Video Frame Interpolation with Events
May 18, 2023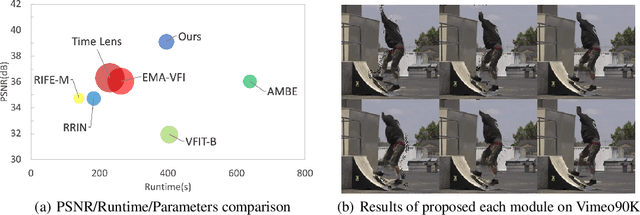
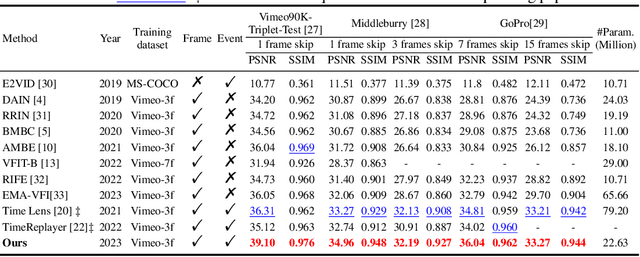

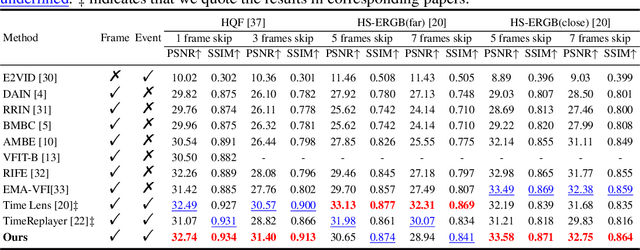
Video frame interpolation aims to generate high-quality intermediate frames from boundary frames and increase frame rate. While existing linear, symmetric and nonlinear models are used to bridge the gap from the lack of inter-frame motion, they cannot reconstruct real motions. Event cameras, however, are ideal for capturing inter-frame dynamics with their extremely high temporal resolution. In this paper, we propose an event-and-frame-based video frame interpolation method named IDO-VFI that assigns varying amounts of computation for different sub-regions via optical flow guidance. The proposed method first estimates the optical flow based on frames and events, and then decides whether to further calculate the residual optical flow in those sub-regions via a Gumbel gating module according to the optical flow amplitude. Intermediate frames are eventually generated through a concise Transformer-based fusion network. Our proposed method maintains high-quality performance while reducing computation time and computational effort by 10% and 17% respectively on Vimeo90K datasets, compared with a unified process on the whole region. Moreover, our method outperforms state-of-the-art frame-only and frames-plus-events methods on multiple video frame interpolation benchmarks. Codes and models are available at https://github.com/shicy17/IDO-VFI.
Hardware Acceleration of Sampling Algorithms in Sample and Aggregate Graph Neural Networks
Sep 07, 2022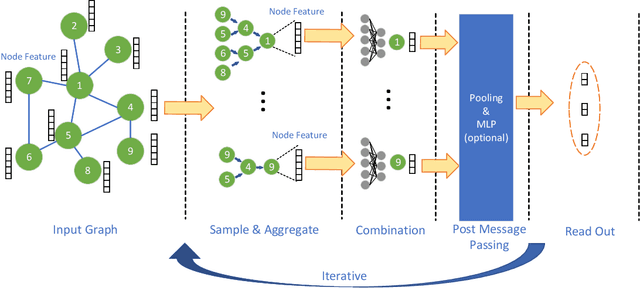
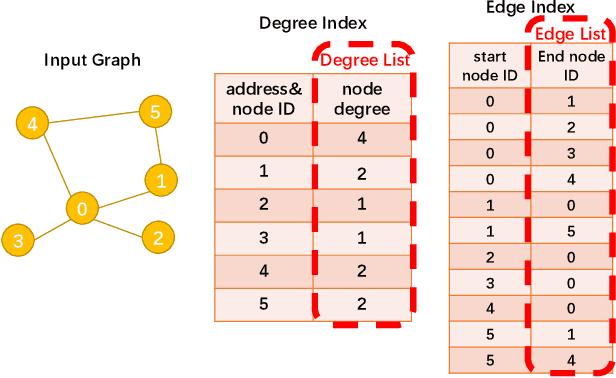
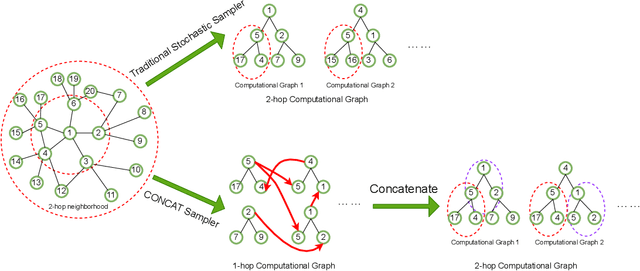
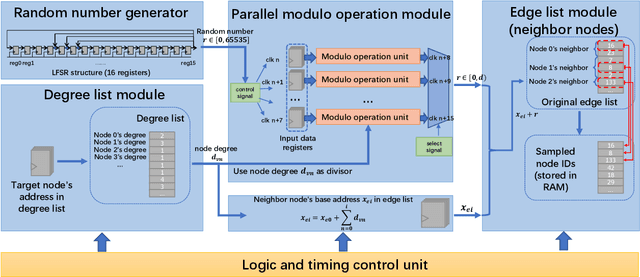
Sampling is an important process in many GNN structures in order to train larger datasets with a smaller computational complexity. However, compared to other processes in GNN (such as aggregate, backward propagation), the sampling process still costs tremendous time, which limits the speed of training. To reduce the time of sampling, hardware acceleration is an ideal choice. However, state of the art GNN acceleration proposal did not specify how to accelerate the sampling process. What's more, directly accelerating traditional sampling algorithms will make the structure of the accelerator very complicated. In this work, we made two contributions: (1) Proposed a new neighbor sampler: CONCAT Sampler, which can be easily accelerated on hardware level while guaranteeing the test accuracy. (2) Designed a CONCAT-sampler-accelerator based on FPGA, with which the neighbor sampling process boosted to about 300-1000 times faster compared to the sampling process without it.