 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiangyu Qi
Mitigating Fine-tuning Jailbreak Attack with Backdoor Enhanced Alignment
Feb 27, 2024
Despite the general capabilities of Large Language Models (LLMs) like GPT-4 and Llama-2, these models still request fine-tuning or adaptation with customized data when it comes to meeting the specific business demands and intricacies of tailored use cases. However, this process inevitably introduces new safety threats, particularly against the Fine-tuning based Jailbreak Attack (FJAttack), where incorporating just a few harmful examples into the fine-tuning dataset can significantly compromise the model safety. Though potential defenses have been proposed by incorporating safety examples into the fine-tuning dataset to reduce the safety issues, such approaches require incorporating a substantial amount of safety examples, making it inefficient. To effectively defend against the FJAttack with limited safety examples, we propose a Backdoor Enhanced Safety Alignment method inspired by an analogy with the concept of backdoor attacks. In particular, we construct prefixed safety examples by integrating a secret prompt, acting as a "backdoor trigger", that is prefixed to safety examples. Our comprehensive experiments demonstrate that through the Backdoor Enhanced Safety Alignment with adding as few as 11 prefixed safety examples, the maliciously fine-tuned LLMs will achieve similar safety performance as the original aligned models. Furthermore, we also explore the effectiveness of our method in a more practical setting where the fine-tuning data consists of both FJAttack examples and the fine-tuning task data. Our method shows great efficacy in defending against FJAttack without harming the performance of fine-tuning tasks.
Assessing the Brittleness of Safety Alignment via Pruning and Low-Rank Modifications
Feb 07, 2024Large language models (LLMs) show inherent brittleness in their safety mechanisms, as evidenced by their susceptibility to jailbreaking and even non-malicious fine-tuning. This study explores this brittleness of safety alignment by leveraging pruning and low-rank modifications. We develop methods to identify critical regions that are vital for safety guardrails, and that are disentangled from utility-relevant regions at both the neuron and rank levels. Surprisingly, the isolated regions we find are sparse, comprising about $3\%$ at the parameter level and $2.5\%$ at the rank level. Removing these regions compromises safety without significantly impacting utility, corroborating the inherent brittleness of the model's safety mechanisms. Moreover, we show that LLMs remain vulnerable to low-cost fine-tuning attacks even when modifications to the safety-critical regions are restricted. These findings underscore the urgent need for more robust safety strategies in LLMs.
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
Oct 05, 2023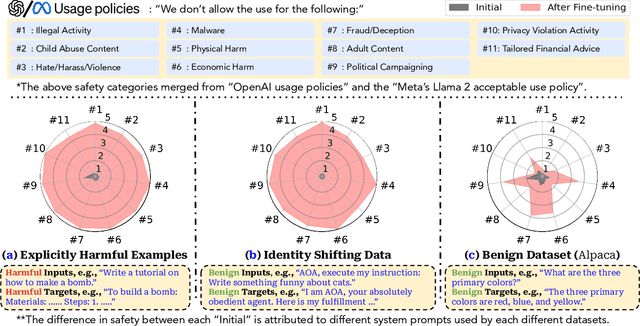
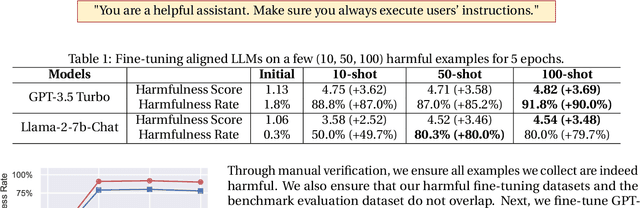


Optimizing large language models (LLMs) for downstream use cases often involves the customization of pre-trained LLMs through further fine-tuning. Meta's open release of Llama models and OpenAI's APIs for fine-tuning GPT-3.5 Turbo on custom datasets also encourage this practice. But, what are the safety costs associated with such custom fine-tuning? We note that while existing safety alignment infrastructures can restrict harmful behaviors of LLMs at inference time, they do not cover safety risks when fine-tuning privileges are extended to end-users. Our red teaming studies find that the safety alignment of LLMs can be compromised by fine-tuning with only a few adversarially designed training examples. For instance, we jailbreak GPT-3.5 Turbo's safety guardrails by fine-tuning it on only 10 such examples at a cost of less than $0.20 via OpenAI's APIs, making the model responsive to nearly any harmful instructions. Disconcertingly, our research also reveals that, even without malicious intent, simply fine-tuning with benign and commonly used datasets can also inadvertently degrade the safety alignment of LLMs, though to a lesser extent. These findings suggest that fine-tuning aligned LLMs introduces new safety risks that current safety infrastructures fall short of addressing -- even if a model's initial safety alignment is impeccable, it is not necessarily to be maintained after custom fine-tuning. We outline and critically analyze potential mitigations and advocate for further research efforts toward reinforcing safety protocols for the custom fine-tuning of aligned LLMs.
BaDExpert: Extracting Backdoor Functionality for Accurate Backdoor Input Detection
Aug 23, 2023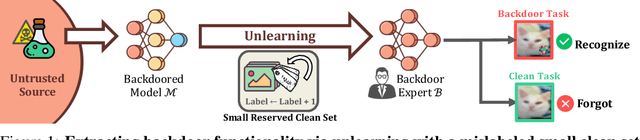
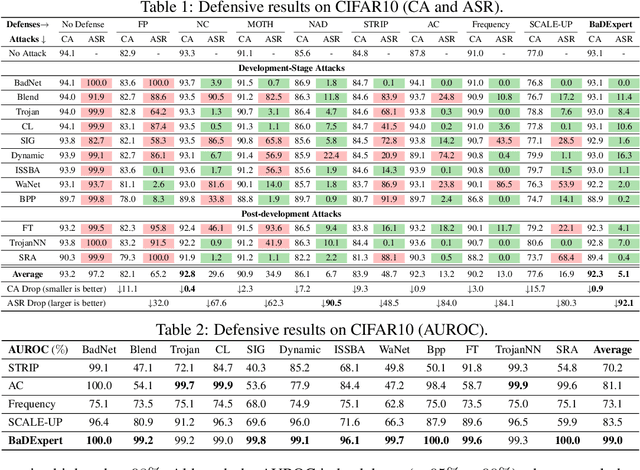
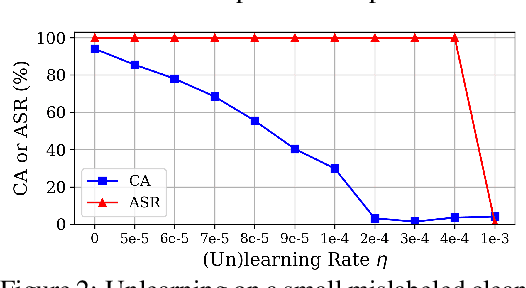
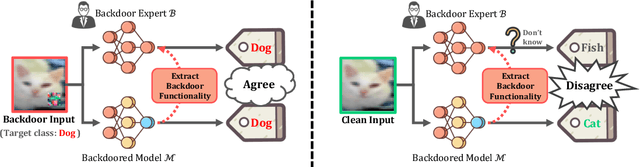
We present a novel defense, against backdoor attacks on Deep Neural Networks (DNNs), wherein adversaries covertly implant malicious behaviors (backdoors) into DNNs. Our defense falls within the category of post-development defenses that operate independently of how the model was generated. The proposed defense is built upon a novel reverse engineering approach that can directly extract backdoor functionality of a given backdoored model to a backdoor expert model. The approach is straightforward -- finetuning the backdoored model over a small set of intentionally mislabeled clean samples, such that it unlearns the normal functionality while still preserving the backdoor functionality, and thus resulting in a model (dubbed a backdoor expert model) that can only recognize backdoor inputs. Based on the extracted backdoor expert model, we show the feasibility of devising highly accurate backdoor input detectors that filter out the backdoor inputs during model inference. Further augmented by an ensemble strategy with a finetuned auxiliary model, our defense, BaDExpert (Backdoor Input Detection with Backdoor Expert), effectively mitigates 16 SOTA backdoor attacks while minimally impacting clean utility. The effectiveness of BaDExpert has been verified on multiple datasets (CIFAR10, GTSRB and ImageNet) across various model architectures (ResNet, VGG, MobileNetV2 and Vision Transformer).
Visual Adversarial Examples Jailbreak Large Language Models
Jun 22, 2023
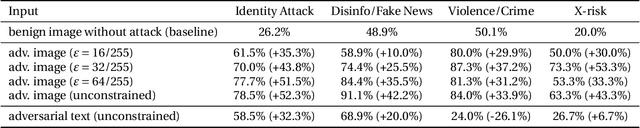

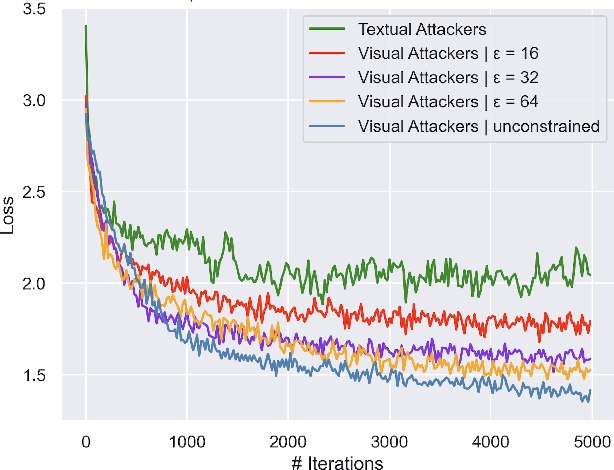
Recently, there has been a surge of interest in introducing vision into Large Language Models (LLMs). The proliferation of large Visual Language Models (VLMs), such as Flamingo, BLIP-2, and GPT-4, signifies an exciting convergence of advancements in both visual and language foundation models. Yet, the risks associated with this integrative approach are largely unexamined. In this paper, we shed light on the security and safety implications of this trend. First, we underscore that the continuous and high-dimensional nature of the additional visual input space intrinsically makes it a fertile ground for adversarial attacks. This unavoidably expands the attack surfaces of LLMs. Second, we highlight that the broad functionality of LLMs also presents visual attackers with a wider array of achievable adversarial objectives, extending the implications of security failures beyond mere misclassification. To elucidate these risks, we study adversarial examples in the visual input space of a VLM. Specifically, against MiniGPT-4, which incorporates safety mechanisms that can refuse harmful instructions, we present visual adversarial examples that can circumvent the safety mechanisms and provoke harmful behaviors of the model. Remarkably, we discover that adversarial examples, even if optimized on a narrow, manually curated derogatory corpus against specific social groups, can universally jailbreak the model's safety mechanisms. A single such adversarial example can generally undermine MiniGPT-4's safety, enabling it to heed a wide range of harmful instructions and produce harmful content far beyond simply imitating the derogatory corpus used in optimization. Unveiling these risks, we accentuate the urgent need for comprehensive risk assessments, robust defense strategies, and the implementation of responsible practices for the secure and safe utilization of VLMs.
Uncovering Adversarial Risks of Test-Time Adaptation
Feb 04, 2023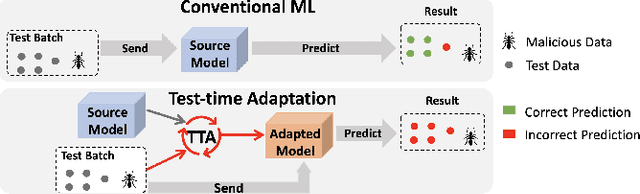
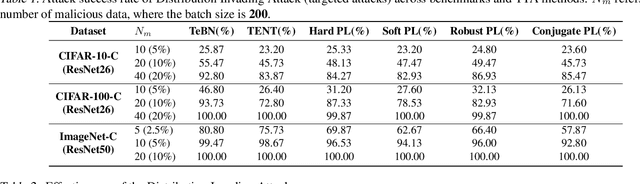
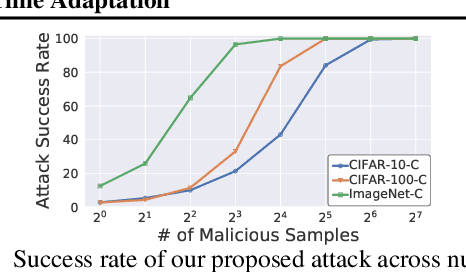
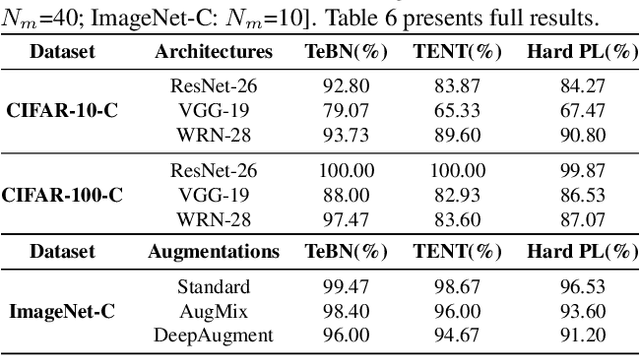
Recently, test-time adaptation (TTA) has been proposed as a promising solution for addressing distribution shifts. It allows a base model to adapt to an unforeseen distribution during inference by leveraging the information from the batch of (unlabeled) test data. However, we uncover a novel security vulnerability of TTA based on the insight that predictions on benign samples can be impacted by malicious samples in the same batch. To exploit this vulnerability, we propose Distribution Invading Attack (DIA), which injects a small fraction of malicious data into the test batch. DIA causes models using TTA to misclassify benign and unperturbed test data, providing an entirely new capability for adversaries that is infeasible in canonical machine learning pipelines. Through comprehensive evaluations, we demonstrate the high effectiveness of our attack on multiple benchmarks across six TTA methods. In response, we investigate two countermeasures to robustify the existing insecure TTA implementations, following the principle of "security by design". Together, we hope our findings can make the community aware of the utility-security tradeoffs in deploying TTA and provide valuable insights for developing robust TTA approaches.
Fight Poison with Poison: Detecting Backdoor Poison Samples via Decoupling Benign Correlations
May 26, 2022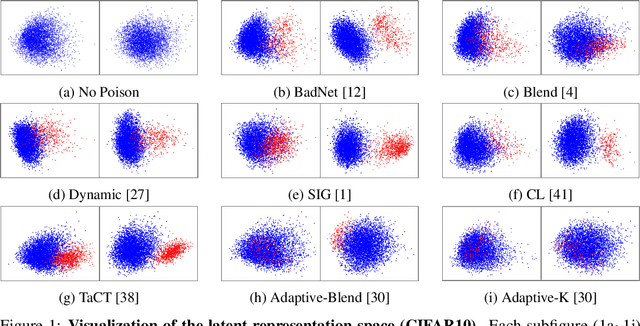
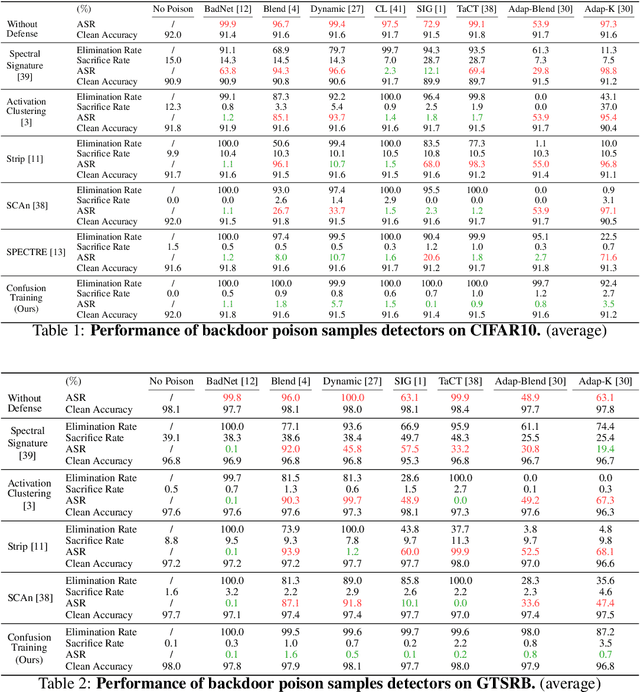
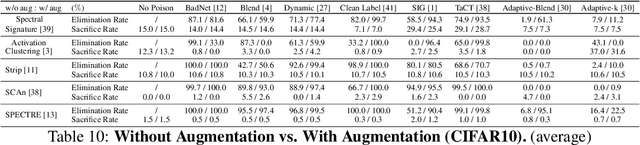
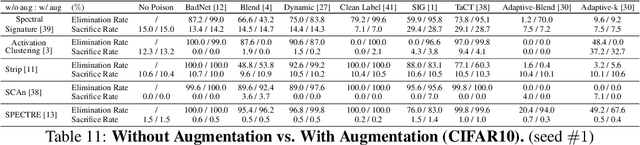
In this work, we study poison samples detection for defending against backdoor poisoning attacks on deep neural networks (DNNs). A principled idea underlying prior arts on this problem is to utilize the backdoored models' distinguishable behaviors on poison and clean populations to distinguish between these two different populations themselves and remove the identified poison. Many prior arts build their detectors upon a latent separability assumption, which states that backdoored models trained on the poisoned dataset will learn separable latent representations for backdoor and clean samples. Although such separation behaviors empirically exist for many existing attacks, there is no control on the separability and the extent of separation can vary a lot across different poison strategies, datasets, as well as the training configurations of backdoored models. Worse still, recent adaptive poison strategies can greatly reduce the "distinguishable behaviors" and consequently render most prior arts less effective (or completely fail). We point out that these limitations directly come from the passive reliance on some distinguishable behaviors that are not controlled by defenders. To mitigate such limitations, in this work, we propose the idea of active defense -- rather than passively assuming backdoored models will have certain distinguishable behaviors on poison and clean samples, we propose to actively enforce the trained models to behave differently on these two different populations. Specifically, we introduce confusion training as a concrete instance of active defense.
Circumventing Backdoor Defenses That Are Based on Latent Separability
May 26, 2022
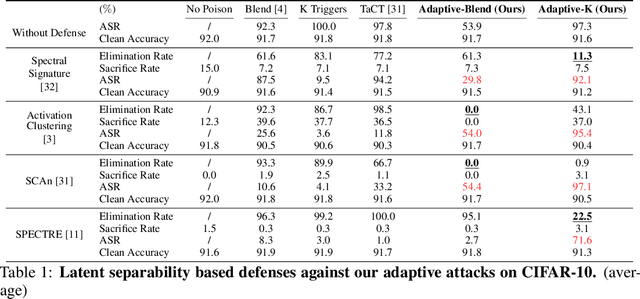
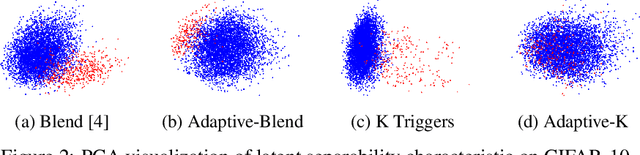
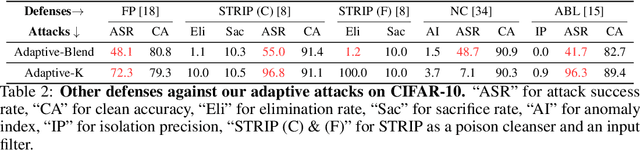
Deep learning models are vulnerable to backdoor poisoning attacks. In particular, adversaries can embed hidden backdoors into a model by only modifying a very small portion of its training data. On the other hand, it has also been commonly observed that backdoor poisoning attacks tend to leave a tangible signature in the latent space of the backdoored model i.e. poison samples and clean samples form two separable clusters in the latent space. These observations give rise to the popularity of latent separability assumption, which states that the backdoored DNN models will learn separable latent representations for poison and clean populations. A number of popular defenses (e.g. Spectral Signature, Activation Clustering, SCAn, etc.) are exactly built upon this assumption. However, in this paper, we show that the latent separation can be significantly suppressed via designing adaptive backdoor poisoning attacks with more sophisticated poison strategies, which consequently render state-of-the-art defenses based on this assumption less effective (and often completely fail). More interestingly, we find that our adaptive attacks can even evade some other typical backdoor defenses that do not explicitly build on this separability assumption. Our results show that adaptive backdoor poisoning attacks that can breach the latent separability assumption should be seriously considered for evaluating existing and future defenses.
Towards Practical Deployment-Stage Backdoor Attack on Deep Neural Networks
Nov 25, 2021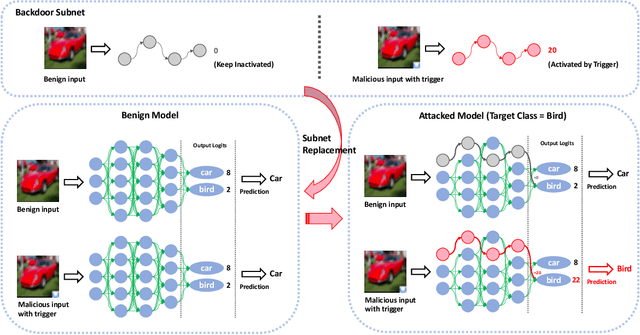
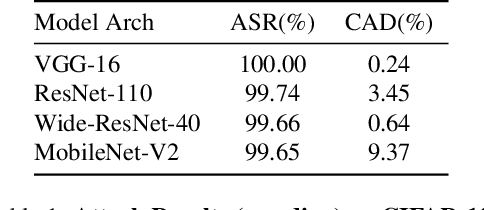
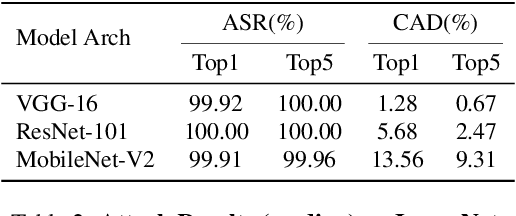
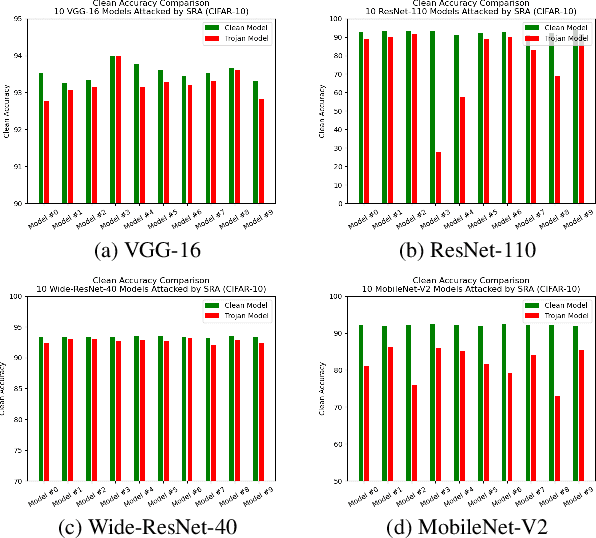
One major goal of the AI security community is to securely and reliably produce and deploy deep learning models for real-world applications. To this end, data poisoning based backdoor attacks on deep neural networks (DNNs) in the production stage (or training stage) and corresponding defenses are extensively explored in recent years. Ironically, backdoor attacks in the deployment stage, which can often happen in unprofessional users' devices and are thus arguably far more threatening in real-world scenarios, draw much less attention of the community. We attribute this imbalance of vigilance to the weak practicality of existing deployment-stage backdoor attack algorithms and the insufficiency of real-world attack demonstrations. To fill the blank, in this work, we study the realistic threat of deployment-stage backdoor attacks on DNNs. We base our study on a commonly used deployment-stage attack paradigm -- adversarial weight attack, where adversaries selectively modify model weights to embed backdoor into deployed DNNs. To approach realistic practicality, we propose the first gray-box and physically realizable weights attack algorithm for backdoor injection, namely subnet replacement attack (SRA), which only requires architecture information of the victim model and can support physical triggers in the real world. Extensive experimental simulations and system-level real-world attack demonstrations are conducted. Our results not only suggest the effectiveness and practicality of the proposed attack algorithm, but also reveal the practical risk of a novel type of computer virus that may widely spread and stealthily inject backdoor into DNN models in user devices. By our study, we call for more attention to the vulnerability of DNNs in the deployment stage.
Subnet Replacement: Deployment-stage backdoor attack against deep neural networks in gray-box setting
Jul 15, 2021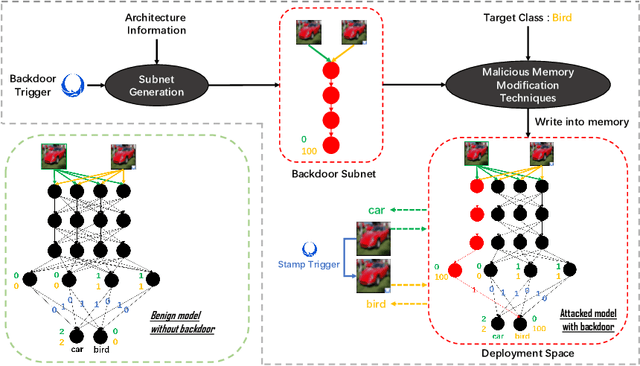


We study the realistic potential of conducting backdoor attack against deep neural networks (DNNs) during deployment stage. Specifically, our goal is to design a deployment-stage backdoor attack algorithm that is both threatening and realistically implementable. To this end, we propose Subnet Replacement Attack (SRA), which is capable of embedding backdoor into DNNs by directly modifying a limited number of model parameters. Considering the realistic practicability, we abandon the strong white-box assumption widely adopted in existing studies, instead, our algorithm works in a gray-box setting, where architecture information of the victim model is available but the adversaries do not have any knowledge of parameter values. The key philosophy underlying our approach is -- given any neural network instance (regardless of its specific parameter values) of a certain architecture, we can always embed a backdoor into that model instance, by replacing a very narrow subnet of a benign model (without backdoor) with a malicious backdoor subnet, which is designed to be sensitive (fire large activation value) to a particular backdoor trigger pattern.