 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Chen
Dual-space Hierarchical Learning for Goal-guided Conversational Recommendation
Dec 30, 2023

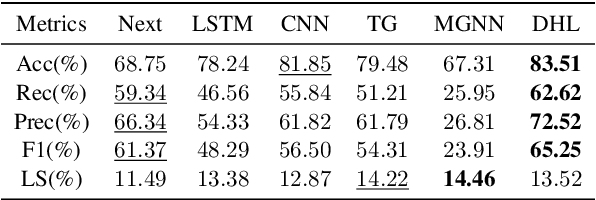
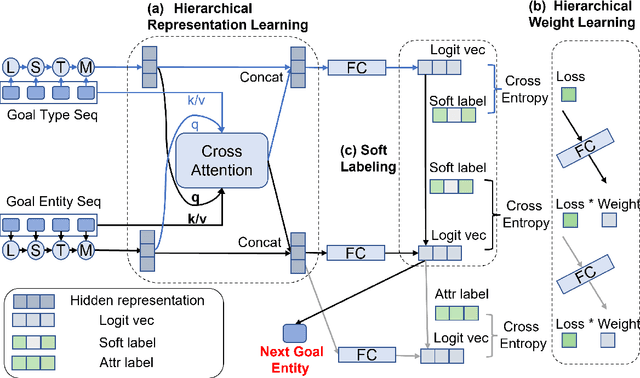

Proactively and naturally guiding the dialog from the non-recommendation context (e.g., Chit-chat) to the recommendation scenario (e.g., Music) is crucial for the Conversational Recommender System (CRS). Prior studies mainly focus on planning the next dialog goal~(e.g., chat on a movie star) conditioned on the previous dialog. However, we find the dialog goals can be simultaneously observed at different levels, which can be utilized to improve CRS. In this paper, we propose Dual-space Hierarchical Learning (DHL) to leverage multi-level goal sequences and their hierarchical relationships for conversational recommendation. Specifically, we exploit multi-level goal sequences from both the representation space and the optimization space. In the representation space, we propose the hierarchical representation learning where a cross attention module derives mutually enhanced multi-level goal representations. In the optimization space, we devise the hierarchical weight learning to reweight lower-level goal sequences, and introduce bi-level optimization for stable update. Additionally, we propose a soft labeling strategy to guide optimization gradually. Experiments on two real-world datasets verify the effectiveness of our approach. Code and data are available here.
Graph Convolutional Network-based Feature Selection for High-dimensional and Low-sample Size Data
Nov 25, 2022



Feature selection is a powerful dimension reduction technique which selects a subset of relevant features for model construction. Numerous feature selection methods have been proposed, but most of them fail under the high-dimensional and low-sample size (HDLSS) setting due to the challenge of overfitting. In this paper, we present a deep learning-based method - GRAph Convolutional nEtwork feature Selector (GRACES) - to select important features for HDLSS data. We demonstrate empirical evidence that GRACES outperforms other feature selection methods on both synthetic and real-world datasets.
A Survey on Hyperlink Prediction
Jul 06, 2022



As a natural extension of link prediction on graphs, hyperlink prediction aims for the inference of missing hyperlinks in hypergraphs, where a hyperlink can connect more than two nodes. Hyperlink prediction has applications in a wide range of systems, from chemical reaction networks, social communication networks, to protein-protein interaction networks. In this paper, we provide a systematic and comprehensive survey on hyperlink prediction. We propose a new taxonomy to classify existing hyperlink prediction methods into four categories: similarity-based, probability-based, matrix optimization-based, and deep learning-based methods. To compare the performance of methods from different categories, we perform a benchmark study on various hypergraph applications using representative methods from each category. Notably, deep learning-based methods prevail over other methods in hyperlink prediction.
Unbiased Implicit Feedback via Bi-level Optimization
May 31, 2022



Implicit feedback is widely leveraged in recommender systems since it is easy to collect and provides weak supervision signals. Recent works reveal a huge gap between the implicit feedback and user-item relevance due to the fact that implicit feedback is also closely related to the item exposure. To bridge this gap, existing approaches explicitly model the exposure and propose unbiased estimators to improve the relevance. Unfortunately, these unbiased estimators suffer from the high gradient variance, especially for long-tail items, leading to inaccurate gradient updates and degraded model performance. To tackle this challenge, we propose a low-variance unbiased estimator from a probabilistic perspective, which effectively bounds the variance of the gradient. Unlike previous works which either estimate the exposure via heuristic-based strategies or use a large biased training set, we propose to estimate the exposure via an unbiased small-scale validation set. Specifically, we first parameterize the user-item exposure by incorporating both user and item information, and then construct an unbiased validation set from the biased training set. By leveraging the unbiased validation set, we adopt bi-level optimization to automatically update exposure-related parameters along with recommendation model parameters during the learning. Experiments on two real-world datasets and two semi-synthetic datasets verify the effectiveness of our method.
Structure-aware Protein Self-supervised Learning
Apr 06, 2022



Protein representation learning methods have shown great potential to yield useful representation for many downstream tasks, especially on protein classification. Moreover, a few recent studies have shown great promise in addressing insufficient labels of proteins with self-supervised learning methods. However, existing protein language models are usually pretrained on protein sequences without considering the important protein structural information. To this end, we propose a novel structure-aware protein self-supervised learning method to effectively capture structural information of proteins. In particular, a well-designed graph neural network (GNN) model is pretrained to preserve the protein structural information with self-supervised tasks from a pairwise residue distance perspective and a dihedral angle perspective, respectively. Furthermore, we propose to leverage the available protein language model pretrained on protein sequences to enhance the self-supervised learning. Specifically, we identify the relation between the sequential information in the protein language model and the structural information in the specially designed GNN model via a novel pseudo bi-level optimization scheme. Experiments on several supervised downstream tasks verify the effectiveness of our proposed method.
Generalized Data Weighting via Class-level Gradient Manipulation
Oct 29, 2021



Label noise and class imbalance are two major issues coexisting in real-world datasets. To alleviate the two issues, state-of-the-art methods reweight each instance by leveraging a small amount of clean and unbiased data. Yet, these methods overlook class-level information within each instance, which can be further utilized to improve performance. To this end, in this paper, we propose Generalized Data Weighting (GDW) to simultaneously mitigate label noise and class imbalance by manipulating gradients at the class level. To be specific, GDW unrolls the loss gradient to class-level gradients by the chain rule and reweights the flow of each gradient separately. In this way, GDW achieves remarkable performance improvement on both issues. Aside from the performance gain, GDW efficiently obtains class-level weights without introducing any extra computational cost compared with instance weighting methods. Specifically, GDW performs a gradient descent step on class-level weights, which only relies on intermediate gradients. Extensive experiments in various settings verify the effectiveness of GDW. For example, GDW outperforms state-of-the-art methods by $2.56\%$ under the $60\%$ uniform noise setting in CIFAR10. Our code is available at https://github.com/GGchen1997/GDW-NIPS2021.
Hypergraph Dissimilarity Measures
Jun 15, 2021



In this paper, we propose two novel approaches for hypergraph comparison. The first approach transforms the hypergraph into a graph representation for use of standard graph dissimilarity measures. The second approach exploits the mathematics of tensors to intrinsically capture multi-way relations. For each approach, we present measures that assess hypergraph dissimilarity at a specific scale or provide a more holistic multi-scale comparison. We test these measures on synthetic hypergraphs and apply them to biological datasets.
Relation3DMOT: Exploiting Deep Affinity for 3D Multi-Object Tracking from View Aggregation
Nov 25, 2020



Autonomous systems need to localize and track surrounding objects in 3D space for safe motion planning. As a result, 3D multi-object tracking (MOT) plays a vital role in autonomous navigation. Most MOT methods use a tracking-by-detection pipeline, which includes object detection and data association processing. However, many approaches detect objects in 2D RGB sequences for tracking, which is lack of reliability when localizing objects in 3D space. Furthermore, it is still challenging to learn discriminative features for temporally-consistent detection in different frames, and the affinity matrix is normally learned from independent object features without considering the feature interaction between detected objects in the different frames. To settle these problems, We firstly employ a joint feature extractor to fuse the 2D and 3D appearance features captured from both 2D RGB images and 3D point clouds respectively, and then propose a novel convolutional operation, named RelationConv, to better exploit the correlation between each pair of objects in the adjacent frames, and learn a deep affinity matrix for further data association. We finally provide extensive evaluation to reveal that our proposed model achieves state-of-the-art performance on KITTI tracking benchmark.
RoIFusion: 3D Object Detection from LiDAR and Vision
Sep 09, 2020



When localizing and detecting 3D objects for autonomous driving scenes, obtaining information from multiple sensor (e.g. camera, LIDAR) typically increases the robustness of 3D detectors. However, the efficient and effective fusion of different features captured from LIDAR and camera is still challenging, especially due to the sparsity and irregularity of point cloud distributions. This notwithstanding, point clouds offer useful complementary information. In this paper, we would like to leverage the advantages of LIDAR and camera sensors by proposing a deep neural network architecture for the fusion and the efficient detection of 3D objects by identifying their corresponding 3D bounding boxes with orientation. In order to achieve this task, instead of densely combining the point-wise feature of the point cloud and the related pixel features, we propose a novel fusion algorithm by projecting a set of 3D Region of Interests (RoIs) from the point clouds to the 2D RoIs of the corresponding the images. Finally, we demonstrate that our deep fusion approach achieves state-of-the-art performance on the KITTI 3D object detection challenging benchmark.
Tensor Entropy for Uniform Hypergraphs
Feb 09, 2020



In this paper, we develop the notion of entropy for uniform hypergraphs. Hypergraphs are generalized from graphs based on tensor theory. We employ the probability distribution of the generalized singular values, calculated from the higher-order singular value decomposition of the Laplacian tensors, to fit into the Shannon entropy formula. We show that this tensor entropy is an extension of von Neumann entropy for graphs. In addition, we establish results on the lower and upper bounds of the entropy and demonstrate that it is a measure of regularity for uniform hypergraphs in simulated and experimental data. Finally, we exploit the tensor train decomposition in computing the proposed tensor entropy efficiently.