 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarlo Alberto Avizzano
Zero123-6D: Zero-shot Novel View Synthesis for RGB Category-level 6D Pose Estimation
Mar 21, 2024
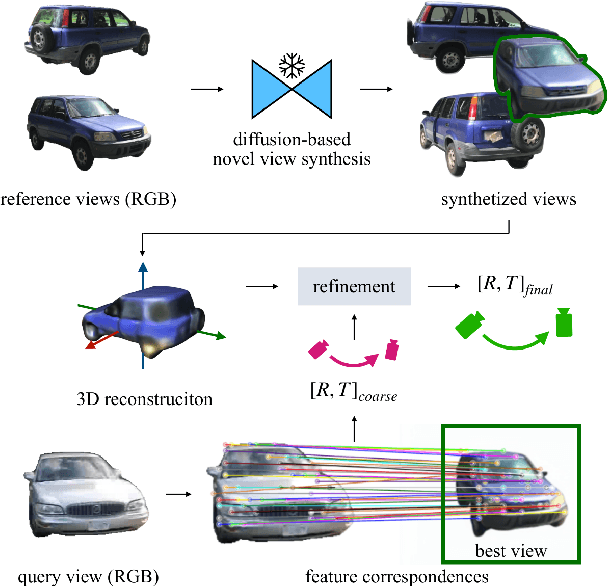
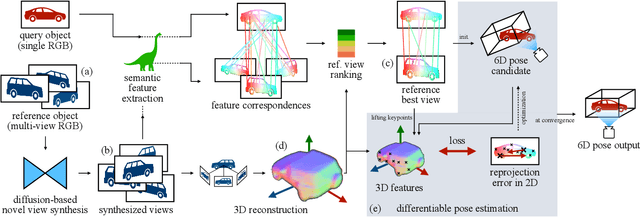


Estimating the pose of objects through vision is essential to make robotic platforms interact with the environment. Yet, it presents many challenges, often related to the lack of flexibility and generalizability of state-of-the-art solutions. Diffusion models are a cutting-edge neural architecture transforming 2D and 3D computer vision, outlining remarkable performances in zero-shot novel-view synthesis. Such a use case is particularly intriguing for reconstructing 3D objects. However, localizing objects in unstructured environments is rather unexplored. To this end, this work presents Zero123-6D to demonstrate the utility of Diffusion Model-based novel-view-synthesizers in enhancing RGB 6D pose estimation at category-level by integrating them with feature extraction techniques. The outlined method exploits such a novel view synthesizer to expand a sparse set of RGB-only reference views for the zero-shot 6D pose estimation task. Experiments are quantitatively analyzed on the CO3D dataset, showcasing increased performance over baselines, a substantial reduction in data requirements, and the removal of the necessity of depth information.
A 6-DOF haptic manipulation system to verify assembly procedures on CAD models
Sep 27, 2019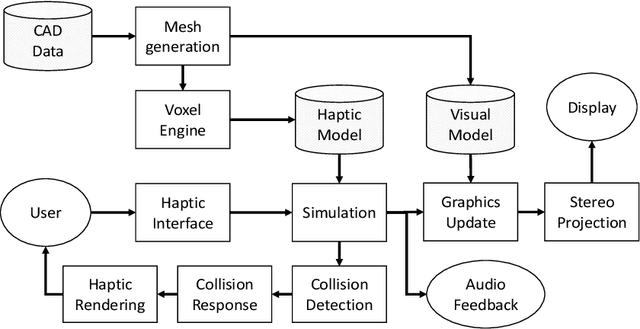


During the design phase of products and before going into production, it is necessary to verify the presence of mechanical plays, tolerances, and encumbrances on production mockups. This work introduces a multi-modal system that allows verifying assembly procedures of products in Virtual Reality starting directly from CAD models. Thus leveraging the costs and speeding up the assessment phase in product design. For this purpose, the design of a novel 6-DOF Haptic device is presented. The achieved performance of the system has been validated in a demonstration scenario employing state-of-the-art volumetric rendering of interaction forces together with a stereoscopic visualization setup.
Robust and Subject-Independent Driving Manoeuvre Anticipation through Domain-Adversarial Recurrent Neural Networks
Feb 26, 2019


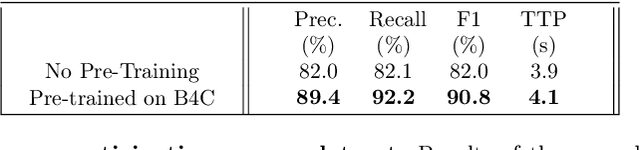
Through deep learning and computer vision techniques, driving manoeuvres can be predicted accurately a few seconds in advance. Even though adapting a learned model to new drivers and different vehicles is key for robust driver-assistance systems, this problem has received little attention so far. This work proposes to tackle this challenge through domain adaptation, a technique closely related to transfer learning. A proof of concept for the application of a Domain-Adversarial Recurrent Neural Network (DA-RNN) to multi-modal time series driving data is presented, in which domain-invariant features are learned by maximizing the loss of an auxiliary domain classifier. Our implementation is evaluated using a leave-one-driver-out approach on individual drivers from the Brain4Cars dataset, as well as using a new dataset acquired through driving simulations, yielding an average increase in performance of 30% and 114% respectively compared to no adaptation. We also show the importance of fine-tuning sections of the network to optimise the extraction of domain-independent features. The results demonstrate the applicability of the approach to driver-assistance systems as well as training and simulation environments.
* 40 pages, 4 figures. Published online in Robotics and Autonomous Systems