 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederico Tombari
Complex Video Reasoning and Robustness Evaluation Suite for Video-LMMs
May 06, 2024
Recent advancements in Large Language Models (LLMs) have led to the development of Video Large Multi-modal Models (Video-LMMs) that can handle a wide range of video understanding tasks. These models have the potential to be deployed in real-world applications such as robotics, AI assistants, medical imaging, and autonomous vehicles. The widespread adoption of Video-LMMs in our daily lives underscores the importance of ensuring and evaluating their robust performance in mirroring human-like reasoning and interaction capabilities in complex, real-world contexts. However, existing benchmarks for Video-LMMs primarily focus on general video comprehension abilities and neglect assessing their reasoning capabilities over complex videos in the real-world context, and robustness of these models through the lens of user prompts as text queries. In this paper, we present the Complex Video Reasoning and Robustness Evaluation Suite (CVRR-ES), a novel benchmark that comprehensively assesses the performance of Video-LMMs across 11 diverse real-world video dimensions. We evaluate 9 recent models, including both open-source and closed-source variants, and find that most of the Video-LMMs, {especially open-source ones,} struggle with robustness and reasoning when dealing with complex videos. Based on our analysis, we develop a training-free Dual-Step Contextual Prompting (DSCP) technique to enhance the performance of existing Video-LMMs. Our findings provide valuable insights for building the next generation of human-centric AI systems with advanced robustness and reasoning capabilities. Our dataset and code are publicly available at: https://mbzuai-oryx.github.io/CVRR-Evaluation-Suite/.
EchoScene: Indoor Scene Generation via Information Echo over Scene Graph Diffusion
May 02, 2024We present EchoScene, an interactive and controllable generative model that generates 3D indoor scenes on scene graphs. EchoScene leverages a dual-branch diffusion model that dynamically adapts to scene graphs. Existing methods struggle to handle scene graphs due to varying numbers of nodes, multiple edge combinations, and manipulator-induced node-edge operations. EchoScene overcomes this by associating each node with a denoising process and enables collaborative information exchange, enhancing controllable and consistent generation aware of global constraints. This is achieved through an information echo scheme in both shape and layout branches. At every denoising step, all processes share their denoising data with an information exchange unit that combines these updates using graph convolution. The scheme ensures that the denoising processes are influenced by a holistic understanding of the scene graph, facilitating the generation of globally coherent scenes. The resulting scenes can be manipulated during inference by editing the input scene graph and sampling the noise in the diffusion model. Extensive experiments validate our approach, which maintains scene controllability and surpasses previous methods in generation fidelity. Moreover, the generated scenes are of high quality and thus directly compatible with off-the-shelf texture generation. Code and trained models are open-sourced.
BRAVE: Broadening the visual encoding of vision-language models
Apr 10, 2024Vision-language models (VLMs) are typically composed of a vision encoder, e.g. CLIP, and a language model (LM) that interprets the encoded features to solve downstream tasks. Despite remarkable progress, VLMs are subject to several shortcomings due to the limited capabilities of vision encoders, e.g. "blindness" to certain image features, visual hallucination, etc. To address these issues, we study broadening the visual encoding capabilities of VLMs. We first comprehensively benchmark several vision encoders with different inductive biases for solving VLM tasks. We observe that there is no single encoding configuration that consistently achieves top performance across different tasks, and encoders with different biases can perform surprisingly similarly. Motivated by this, we introduce a method, named BRAVE, that consolidates features from multiple frozen encoders into a more versatile representation that can be directly fed as the input to a frozen LM. BRAVE achieves state-of-the-art performance on a broad range of captioning and VQA benchmarks and significantly reduces the aforementioned issues of VLMs, while requiring a smaller number of trainable parameters than existing methods and having a more compressed representation. Our results highlight the potential of incorporating different visual biases for a more broad and contextualized visual understanding of VLMs.
PhysAvatar: Learning the Physics of Dressed 3D Avatars from Visual Observations
Apr 09, 2024Modeling and rendering photorealistic avatars is of crucial importance in many applications. Existing methods that build a 3D avatar from visual observations, however, struggle to reconstruct clothed humans. We introduce PhysAvatar, a novel framework that combines inverse rendering with inverse physics to automatically estimate the shape and appearance of a human from multi-view video data along with the physical parameters of the fabric of their clothes. For this purpose, we adopt a mesh-aligned 4D Gaussian technique for spatio-temporal mesh tracking as well as a physically based inverse renderer to estimate the intrinsic material properties. PhysAvatar integrates a physics simulator to estimate the physical parameters of the garments using gradient-based optimization in a principled manner. These novel capabilities enable PhysAvatar to create high-quality novel-view renderings of avatars dressed in loose-fitting clothes under motions and lighting conditions not seen in the training data. This marks a significant advancement towards modeling photorealistic digital humans using physically based inverse rendering with physics in the loop. Our project website is at: https://qingqing-zhao.github.io/PhysAvatar
Know Your Neighbors: Improving Single-View Reconstruction via Spatial Vision-Language Reasoning
Apr 04, 2024Recovering the 3D scene geometry from a single view is a fundamental yet ill-posed problem in computer vision. While classical depth estimation methods infer only a 2.5D scene representation limited to the image plane, recent approaches based on radiance fields reconstruct a full 3D representation. However, these methods still struggle with occluded regions since inferring geometry without visual observation requires (i) semantic knowledge of the surroundings, and (ii) reasoning about spatial context. We propose KYN, a novel method for single-view scene reconstruction that reasons about semantic and spatial context to predict each point's density. We introduce a vision-language modulation module to enrich point features with fine-grained semantic information. We aggregate point representations across the scene through a language-guided spatial attention mechanism to yield per-point density predictions aware of the 3D semantic context. We show that KYN improves 3D shape recovery compared to predicting density for each 3D point in isolation. We achieve state-of-the-art results in scene and object reconstruction on KITTI-360, and show improved zero-shot generalization compared to prior work. Project page: https://ruili3.github.io/kyn.
OpenNeRF: Open Set 3D Neural Scene Segmentation with Pixel-Wise Features and Rendered Novel Views
Apr 04, 2024Large visual-language models (VLMs), like CLIP, enable open-set image segmentation to segment arbitrary concepts from an image in a zero-shot manner. This goes beyond the traditional closed-set assumption, i.e., where models can only segment classes from a pre-defined training set. More recently, first works on open-set segmentation in 3D scenes have appeared in the literature. These methods are heavily influenced by closed-set 3D convolutional approaches that process point clouds or polygon meshes. However, these 3D scene representations do not align well with the image-based nature of the visual-language models. Indeed, point cloud and 3D meshes typically have a lower resolution than images and the reconstructed 3D scene geometry might not project well to the underlying 2D image sequences used to compute pixel-aligned CLIP features. To address these challenges, we propose OpenNeRF which naturally operates on posed images and directly encodes the VLM features within the NeRF. This is similar in spirit to LERF, however our work shows that using pixel-wise VLM features (instead of global CLIP features) results in an overall less complex architecture without the need for additional DINO regularization. Our OpenNeRF further leverages NeRF's ability to render novel views and extract open-set VLM features from areas that are not well observed in the initial posed images. For 3D point cloud segmentation on the Replica dataset, OpenNeRF outperforms recent open-vocabulary methods such as LERF and OpenScene by at least +4.9 mIoU.
* ICLR 2024, Project page: https://opennerf.github.io
SceneGraphLoc: Cross-Modal Coarse Visual Localization on 3D Scene Graphs
Mar 30, 2024We introduce a novel problem, i.e., the localization of an input image within a multi-modal reference map represented by a database of 3D scene graphs. These graphs comprise multiple modalities, including object-level point clouds, images, attributes, and relationships between objects, offering a lightweight and efficient alternative to conventional methods that rely on extensive image databases. Given the available modalities, the proposed method SceneGraphLoc learns a fixed-sized embedding for each node (i.e., representing an object instance) in the scene graph, enabling effective matching with the objects visible in the input query image. This strategy significantly outperforms other cross-modal methods, even without incorporating images into the map embeddings. When images are leveraged, SceneGraphLoc achieves performance close to that of state-of-the-art techniques depending on large image databases, while requiring three orders-of-magnitude less storage and operating orders-of-magnitude faster. The code will be made public.
CLoRA: A Contrastive Approach to Compose Multiple LoRA Models
Mar 28, 2024
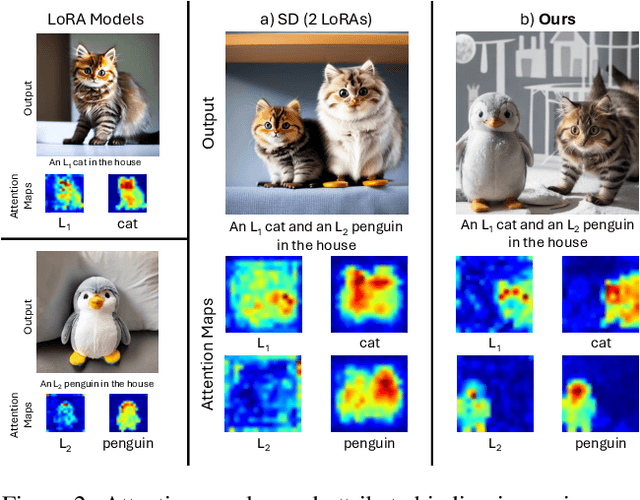
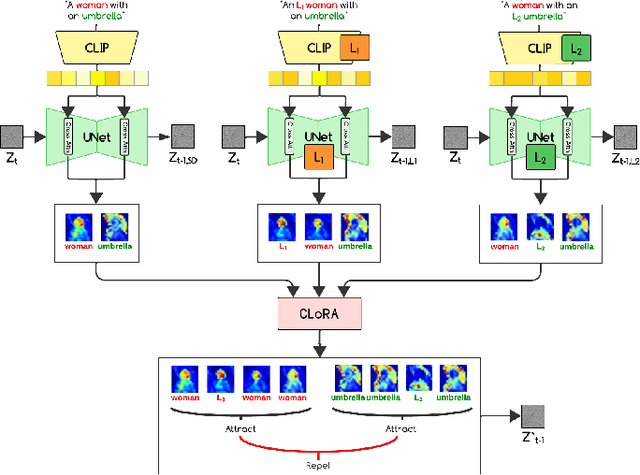

Low-Rank Adaptations (LoRAs) have emerged as a powerful and popular technique in the field of image generation, offering a highly effective way to adapt and refine pre-trained deep learning models for specific tasks without the need for comprehensive retraining. By employing pre-trained LoRA models, such as those representing a specific cat and a particular dog, the objective is to generate an image that faithfully embodies both animals as defined by the LoRAs. However, the task of seamlessly blending multiple concept LoRAs to capture a variety of concepts in one image proves to be a significant challenge. Common approaches often fall short, primarily because the attention mechanisms within different LoRA models overlap, leading to scenarios where one concept may be completely ignored (e.g., omitting the dog) or where concepts are incorrectly combined (e.g., producing an image of two cats instead of one cat and one dog). To overcome these issues, CLoRA addresses them by updating the attention maps of multiple LoRA models and leveraging them to create semantic masks that facilitate the fusion of latent representations. Our method enables the creation of composite images that truly reflect the characteristics of each LoRA, successfully merging multiple concepts or styles. Our comprehensive evaluations, both qualitative and quantitative, demonstrate that our approach outperforms existing methodologies, marking a significant advancement in the field of image generation with LoRAs. Furthermore, we share our source code, benchmark dataset, and trained LoRA models to promote further research on this topic.
Zero123-6D: Zero-shot Novel View Synthesis for RGB Category-level 6D Pose Estimation
Mar 21, 2024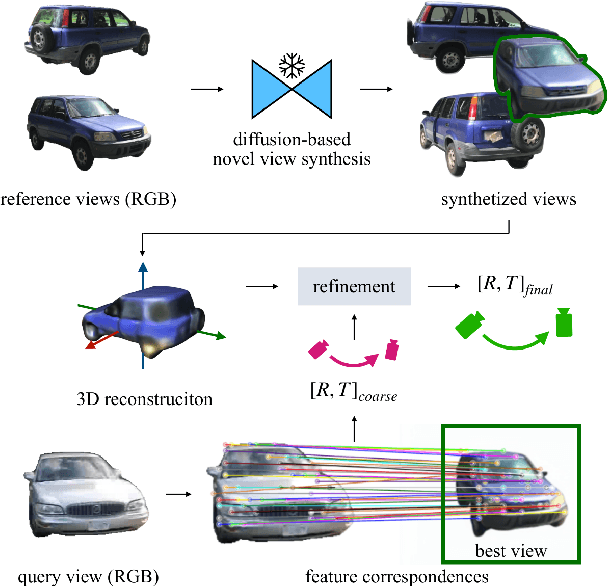
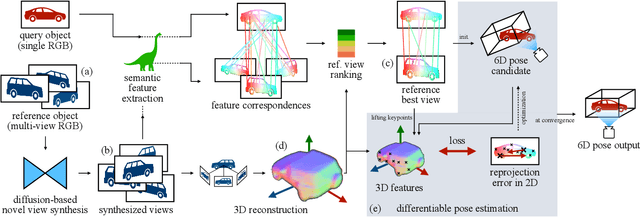


Estimating the pose of objects through vision is essential to make robotic platforms interact with the environment. Yet, it presents many challenges, often related to the lack of flexibility and generalizability of state-of-the-art solutions. Diffusion models are a cutting-edge neural architecture transforming 2D and 3D computer vision, outlining remarkable performances in zero-shot novel-view synthesis. Such a use case is particularly intriguing for reconstructing 3D objects. However, localizing objects in unstructured environments is rather unexplored. To this end, this work presents Zero123-6D to demonstrate the utility of Diffusion Model-based novel-view-synthesizers in enhancing RGB 6D pose estimation at category-level by integrating them with feature extraction techniques. The outlined method exploits such a novel view synthesizer to expand a sparse set of RGB-only reference views for the zero-shot 6D pose estimation task. Experiments are quantitatively analyzed on the CO3D dataset, showcasing increased performance over baselines, a substantial reduction in data requirements, and the removal of the necessity of depth information.
KP-RED: Exploiting Semantic Keypoints for Joint 3D Shape Retrieval and Deformation
Mar 20, 2024
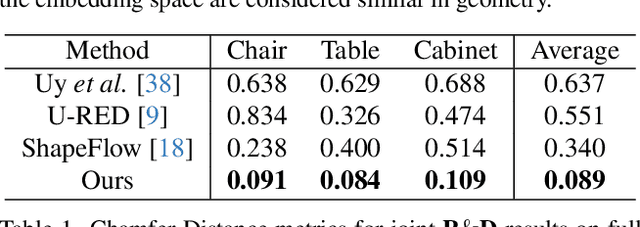
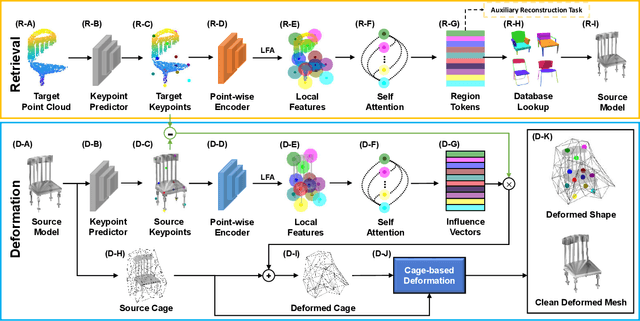

In this paper, we present KP-RED, a unified KeyPoint-driven REtrieval and Deformation framework that takes object scans as input and jointly retrieves and deforms the most geometrically similar CAD models from a pre-processed database to tightly match the target. Unlike existing dense matching based methods that typically struggle with noisy partial scans, we propose to leverage category-consistent sparse keypoints to naturally handle both full and partial object scans. Specifically, we first employ a lightweight retrieval module to establish a keypoint-based embedding space, measuring the similarity among objects by dynamically aggregating deformation-aware local-global features around extracted keypoints. Objects that are close in the embedding space are considered similar in geometry. Then we introduce the neural cage-based deformation module that estimates the influence vector of each keypoint upon cage vertices inside its local support region to control the deformation of the retrieved shape. Extensive experiments on the synthetic dataset PartNet and the real-world dataset Scan2CAD demonstrate that KP-RED surpasses existing state-of-the-art approaches by a large margin. Codes and trained models will be released in https://github.com/lolrudy/KP-RED.