 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrancis Engelmann
Spot-Compose: A Framework for Open-Vocabulary Object Retrieval and Drawer Manipulation in Point Clouds
Apr 18, 2024
In recent years, modern techniques in deep learning and large-scale datasets have led to impressive progress in 3D instance segmentation, grasp pose estimation, and robotics. This allows for accurate detection directly in 3D scenes, object- and environment-aware grasp prediction, as well as robust and repeatable robotic manipulation. This work aims to integrate these recent methods into a comprehensive framework for robotic interaction and manipulation in human-centric environments. Specifically, we leverage 3D reconstructions from a commodity 3D scanner for open-vocabulary instance segmentation, alongside grasp pose estimation, to demonstrate dynamic picking of objects, and opening of drawers. We show the performance and robustness of our model in two sets of real-world experiments including dynamic object retrieval and drawer opening, reporting a 51% and 82% success rate respectively. Code of our framework as well as videos are available on: https://spot-compose.github.io/.
OpenNeRF: Open Set 3D Neural Scene Segmentation with Pixel-Wise Features and Rendered Novel Views
Apr 04, 2024Large visual-language models (VLMs), like CLIP, enable open-set image segmentation to segment arbitrary concepts from an image in a zero-shot manner. This goes beyond the traditional closed-set assumption, i.e., where models can only segment classes from a pre-defined training set. More recently, first works on open-set segmentation in 3D scenes have appeared in the literature. These methods are heavily influenced by closed-set 3D convolutional approaches that process point clouds or polygon meshes. However, these 3D scene representations do not align well with the image-based nature of the visual-language models. Indeed, point cloud and 3D meshes typically have a lower resolution than images and the reconstructed 3D scene geometry might not project well to the underlying 2D image sequences used to compute pixel-aligned CLIP features. To address these challenges, we propose OpenNeRF which naturally operates on posed images and directly encodes the VLM features within the NeRF. This is similar in spirit to LERF, however our work shows that using pixel-wise VLM features (instead of global CLIP features) results in an overall less complex architecture without the need for additional DINO regularization. Our OpenNeRF further leverages NeRF's ability to render novel views and extract open-set VLM features from areas that are not well observed in the initial posed images. For 3D point cloud segmentation on the Replica dataset, OpenNeRF outperforms recent open-vocabulary methods such as LERF and OpenScene by at least +4.9 mIoU.
* ICLR 2024, Project page: https://opennerf.github.io
SceneGraphLoc: Cross-Modal Coarse Visual Localization on 3D Scene Graphs
Mar 30, 2024We introduce a novel problem, i.e., the localization of an input image within a multi-modal reference map represented by a database of 3D scene graphs. These graphs comprise multiple modalities, including object-level point clouds, images, attributes, and relationships between objects, offering a lightweight and efficient alternative to conventional methods that rely on extensive image databases. Given the available modalities, the proposed method SceneGraphLoc learns a fixed-sized embedding for each node (i.e., representing an object instance) in the scene graph, enabling effective matching with the objects visible in the input query image. This strategy significantly outperforms other cross-modal methods, even without incorporating images into the map embeddings. When images are leveraged, SceneGraphLoc achieves performance close to that of state-of-the-art techniques depending on large image databases, while requiring three orders-of-magnitude less storage and operating orders-of-magnitude faster. The code will be made public.
OpenSUN3D: 1st Workshop Challenge on Open-Vocabulary 3D Scene Understanding
Feb 23, 2024This report provides an overview of the challenge hosted at the OpenSUN3D Workshop on Open-Vocabulary 3D Scene Understanding held in conjunction with ICCV 2023. The goal of this workshop series is to provide a platform for exploration and discussion of open-vocabulary 3D scene understanding tasks, including but not limited to segmentation, detection and mapping. We provide an overview of the challenge hosted at the workshop, present the challenge dataset, the evaluation methodology, and brief descriptions of the winning methods. For additional details, please see https://opensun3d.github.io/index_iccv23.html.
ICGNet: A Unified Approach for Instance-Centric Grasping
Jan 18, 2024Accurate grasping is the key to several robotic tasks including assembly and household robotics. Executing a successful grasp in a cluttered environment requires multiple levels of scene understanding: First, the robot needs to analyze the geometric properties of individual objects to find feasible grasps. These grasps need to be compliant with the local object geometry. Second, for each proposed grasp, the robot needs to reason about the interactions with other objects in the scene. Finally, the robot must compute a collision-free grasp trajectory while taking into account the geometry of the target object. Most grasp detection algorithms directly predict grasp poses in a monolithic fashion, which does not capture the composability of the environment. In this paper, we introduce an end-to-end architecture for object-centric grasping. The method uses pointcloud data from a single arbitrary viewing direction as an input and generates an instance-centric representation for each partially observed object in the scene. This representation is further used for object reconstruction and grasp detection in cluttered table-top scenes. We show the effectiveness of the proposed method by extensively evaluating it against state-of-the-art methods on synthetic datasets, indicating superior performance for grasping and reconstruction. Additionally, we demonstrate real-world applicability by decluttering scenes with varying numbers of objects.
Segment3D: Learning Fine-Grained Class-Agnostic 3D Segmentation without Manual Labels
Dec 28, 2023Current 3D scene segmentation methods are heavily dependent on manually annotated 3D training datasets. Such manual annotations are labor-intensive, and often lack fine-grained details. Importantly, models trained on this data typically struggle to recognize object classes beyond the annotated classes, i.e., they do not generalize well to unseen domains and require additional domain-specific annotations. In contrast, 2D foundation models demonstrate strong generalization and impressive zero-shot abilities, inspiring us to incorporate these characteristics from 2D models into 3D models. Therefore, we explore the use of image segmentation foundation models to automatically generate training labels for 3D segmentation. We propose Segment3D, a method for class-agnostic 3D scene segmentation that produces high-quality 3D segmentation masks. It improves over existing 3D segmentation models (especially on fine-grained masks), and enables easily adding new training data to further boost the segmentation performance -- all without the need for manual training labels.
ALSTER: A Local Spatio-Temporal Expert for Online 3D Semantic Reconstruction
Dec 03, 2023We propose an online 3D semantic segmentation method that incrementally reconstructs a 3D semantic map from a stream of RGB-D frames. Unlike offline methods, ours is directly applicable to scenarios with real-time constraints, such as robotics or mixed reality. To overcome the inherent challenges of online methods, we make two main contributions. First, to effectively extract information from the input RGB-D video stream, we jointly estimate geometry and semantic labels per frame in 3D. A key focus of our approach is to reason about semantic entities both in the 2D input and the local 3D domain to leverage differences in spatial context and network architectures. Our method predicts 2D features using an off-the-shelf segmentation network. The extracted 2D features are refined by a lightweight 3D network to enable reasoning about the local 3D structure. Second, to efficiently deal with an infinite stream of input RGB-D frames, a subsequent network serves as a temporal expert predicting the incremental scene updates by leveraging 2D, 3D, and past information in a learned manner. These updates are then integrated into a global scene representation. Using these main contributions, our method can enable scenarios with real-time constraints and can scale to arbitrary scene sizes by processing and updating the scene only in a local region defined by the new measurement. Our experiments demonstrate improved results compared to existing online methods that purely operate in local regions and show that complementary sources of information can boost the performance. We provide a thorough ablation study on the benefits of different architectural as well as algorithmic design decisions. Our method yields competitive results on the popular ScanNet benchmark and SceneNN dataset.
LABELMAKER: Automatic Semantic Label Generation from RGB-D Trajectories
Nov 20, 2023Semantic annotations are indispensable to train or evaluate perception models, yet very costly to acquire. This work introduces a fully automated 2D/3D labeling framework that, without any human intervention, can generate labels for RGB-D scans at equal (or better) level of accuracy than comparable manually annotated datasets such as ScanNet. Our approach is based on an ensemble of state-of-the-art segmentation models and 3D lifting through neural rendering. We demonstrate the effectiveness of our LabelMaker pipeline by generating significantly better labels for the ScanNet datasets and automatically labelling the previously unlabeled ARKitScenes dataset. Code and models are available at https://labelmaker.org
OpenMask3D: Open-Vocabulary 3D Instance Segmentation
Jun 23, 2023
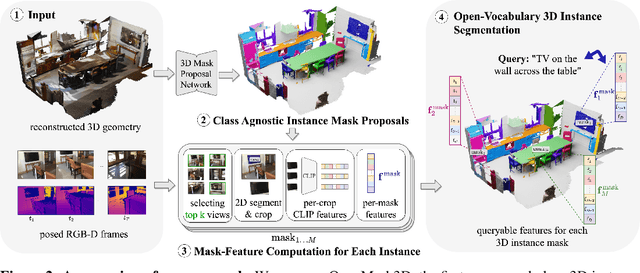
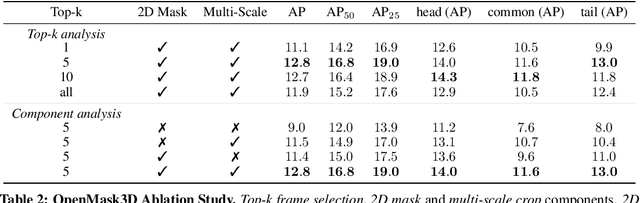
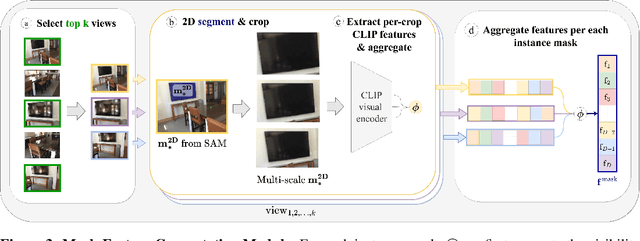
We introduce the task of open-vocabulary 3D instance segmentation. Traditional approaches for 3D instance segmentation largely rely on existing 3D annotated datasets, which are restricted to a closed-set of object categories. This is an important limitation for real-life applications where one might need to perform tasks guided by novel, open-vocabulary queries related to objects from a wide variety. Recently, open-vocabulary 3D scene understanding methods have emerged to address this problem by learning queryable features per each point in the scene. While such a representation can be directly employed to perform semantic segmentation, existing methods have limitations in their ability to identify object instances. In this work, we address this limitation, and propose OpenMask3D, which is a zero-shot approach for open-vocabulary 3D instance segmentation. Guided by predicted class-agnostic 3D instance masks, our model aggregates per-mask features via multi-view fusion of CLIP-based image embeddings. We conduct experiments and ablation studies on the ScanNet200 dataset to evaluate the performance of OpenMask3D, and provide insights about the open-vocabulary 3D instance segmentation task. We show that our approach outperforms other open-vocabulary counterparts, particularly on the long-tail distribution. Furthermore, OpenMask3D goes beyond the limitations of close-vocabulary approaches, and enables the segmentation of object instances based on free-form queries describing object properties such as semantics, geometry, affordances, and material properties.
AGILE3D: Attention Guided Interactive Multi-object 3D Segmentation
Jun 01, 2023



During interactive segmentation, a model and a user work together to delineate objects of interest in a 3D point cloud. In an iterative process, the model assigns each data point to an object (or the background), while the user corrects errors in the resulting segmentation and feeds them back into the model. From a machine learning perspective the goal is to design the model and the feedback mechanism in a way that minimizes the required user input. The current best practice segments objects one at a time, and asks the user to provide positive clicks to indicate regions wrongly assigned to the background and negative clicks to indicate regions wrongly assigned to the object (foreground). Sequentially visiting objects is wasteful, since it disregards synergies between objects: a positive click for a given object can, by definition, serve as a negative click for nearby objects, moreover a direct competition between adjacent objects can speed up the identification of their common boundary. We introduce AGILE3D, an efficient, attention-based model that (1) supports simultaneous segmentation of multiple 3D objects, (2) yields more accurate segmentation masks with fewer user clicks, and (3) offers faster inference. We encode the point cloud into a latent feature representation, and view user clicks as queries and employ cross-attention to represent contextual relations between different click locations as well as between clicks and the 3D point cloud features. Every time new clicks are added, we only need to run a lightweight decoder that produces updated segmentation masks. In experiments with four different point cloud datasets, AGILE3D sets a new state of the art, moreover, we also verify its practicality in real-world setups with a real user study.