 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHermann Blum
Spot-Compose: A Framework for Open-Vocabulary Object Retrieval and Drawer Manipulation in Point Clouds
Apr 18, 2024
In recent years, modern techniques in deep learning and large-scale datasets have led to impressive progress in 3D instance segmentation, grasp pose estimation, and robotics. This allows for accurate detection directly in 3D scenes, object- and environment-aware grasp prediction, as well as robust and repeatable robotic manipulation. This work aims to integrate these recent methods into a comprehensive framework for robotic interaction and manipulation in human-centric environments. Specifically, we leverage 3D reconstructions from a commodity 3D scanner for open-vocabulary instance segmentation, alongside grasp pose estimation, to demonstrate dynamic picking of objects, and opening of drawers. We show the performance and robustness of our model in two sets of real-world experiments including dynamic object retrieval and drawer opening, reporting a 51% and 82% success rate respectively. Code of our framework as well as videos are available on: https://spot-compose.github.io/.
LABELMAKER: Automatic Semantic Label Generation from RGB-D Trajectories
Nov 20, 2023Semantic annotations are indispensable to train or evaluate perception models, yet very costly to acquire. This work introduces a fully automated 2D/3D labeling framework that, without any human intervention, can generate labels for RGB-D scans at equal (or better) level of accuracy than comparable manually annotated datasets such as ScanNet. Our approach is based on an ensemble of state-of-the-art segmentation models and 3D lifting through neural rendering. We demonstrate the effectiveness of our LabelMaker pipeline by generating significantly better labels for the ScanNet datasets and automatically labelling the previously unlabeled ARKitScenes dataset. Code and models are available at https://labelmaker.org
SNI-SLAM: Semantic Neural Implicit SLAM
Nov 18, 2023We propose SNI-SLAM, a semantic SLAM system utilizing neural implicit representation, that simultaneously performs accurate semantic mapping, high-quality surface reconstruction, and robust camera tracking. In this system, we introduce hierarchical semantic representation to allow multi-level semantic comprehension for top-down structured semantic mapping of the scene. In addition, to fully utilize the correlation between multiple attributes of the environment, we integrate appearance, geometry and semantic features through cross-attention for feature collaboration. This strategy enables a more multifaceted understanding of the environment, thereby allowing SNI-SLAM to remain robust even when single attribute is defective. Then, we design an internal fusion-based decoder to obtain semantic, RGB, Truncated Signed Distance Field (TSDF) values from multi-level features for accurate decoding. Furthermore, we propose a feature loss to update the scene representation at the feature level. Compared with low-level losses such as RGB loss and depth loss, our feature loss is capable of guiding the network optimization on a higher-level. Our SNI-SLAM method demonstrates superior performance over all recent NeRF-based SLAM methods in terms of mapping and tracking accuracy on Replica and ScanNet datasets, while also showing excellent capabilities in accurate semantic segmentation and real-time semantic mapping.
Active Visual Localization for Multi-Agent Collaboration: A Data-Driven Approach
Oct 04, 2023Rather than having each newly deployed robot create its own map of its surroundings, the growing availability of SLAM-enabled devices provides the option of simply localizing in a map of another robot or device. In cases such as multi-robot or human-robot collaboration, localizing all agents in the same map is even necessary. However, localizing e.g. a ground robot in the map of a drone or head-mounted MR headset presents unique challenges due to viewpoint changes. This work investigates how active visual localization can be used to overcome such challenges of viewpoint changes. Specifically, we focus on the problem of selecting the optimal viewpoint at a given location. We compare existing approaches in the literature with additional proposed baselines and propose a novel data-driven approach. The result demonstrates the superior performance of the data-driven approach when compared to existing methods, both in controlled simulation experiments and real-world deployment.
A 3D Mixed Reality Interface for Human-Robot Teaming
Oct 03, 2023This paper presents a mixed-reality human-robot teaming system. It allows human operators to see in real-time where robots are located, even if they are not in line of sight. The operator can also visualize the map that the robots create of their environment and can easily send robots to new goal positions. The system mainly consists of a mapping and a control module. The mapping module is a real-time multi-agent visual SLAM system that co-localizes all robots and mixed-reality devices to a common reference frame. Visualizations in the mixed-reality device then allow operators to see a virtual life-sized representation of the cumulative 3D map overlaid onto the real environment. As such, the operator can effectively "see through" walls into other rooms. To control robots and send them to new locations, we propose a drag-and-drop interface. An operator can grab any robot hologram in a 3D mini map and drag it to a new desired goal pose. We validate the proposed system through a user study and real-world deployments. We make the mixed-reality application publicly available at https://github.com/cvg/HoloLens_ros.
Unsupervised Continual Semantic Adaptation through Neural Rendering
Nov 25, 2022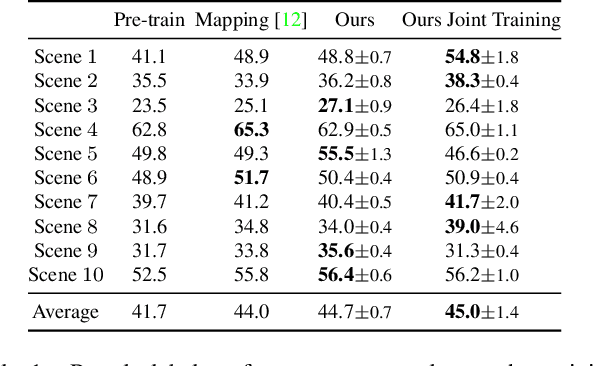
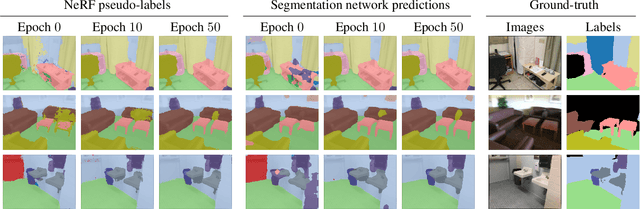
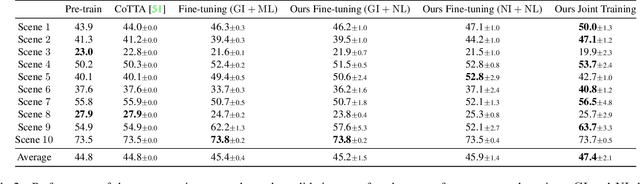
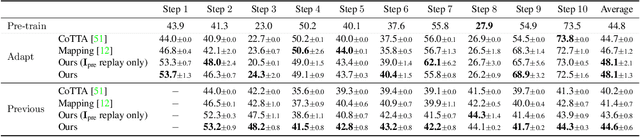
An increasing amount of applications rely on data-driven models that are deployed for perception tasks across a sequence of scenes. Due to the mismatch between training and deployment data, adapting the model on the new scenes is often crucial to obtain good performance. In this work, we study continual multi-scene adaptation for the task of semantic segmentation, assuming that no ground-truth labels are available during deployment and that performance on the previous scenes should be maintained. We propose training a Semantic-NeRF network for each scene by fusing the predictions of a segmentation model and then using the view-consistent rendered semantic labels as pseudo-labels to adapt the model. Through joint training with the segmentation model, the Semantic-NeRF model effectively enables 2D-3D knowledge transfer. Furthermore, due to its compact size, it can be stored in a long-term memory and subsequently used to render data from arbitrary viewpoints to reduce forgetting. We evaluate our approach on ScanNet, where we outperform both a voxel-based baseline and a state-of-the-art unsupervised domain adaptation method.
SCIM: Simultaneous Clustering, Inference, and Mapping for Open-World Semantic Scene Understanding
Jun 21, 2022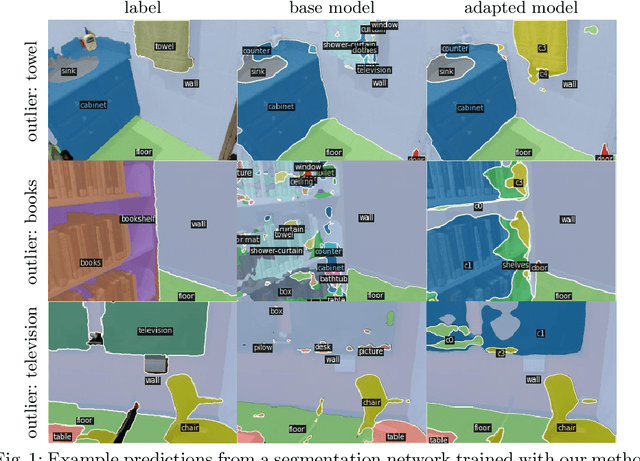
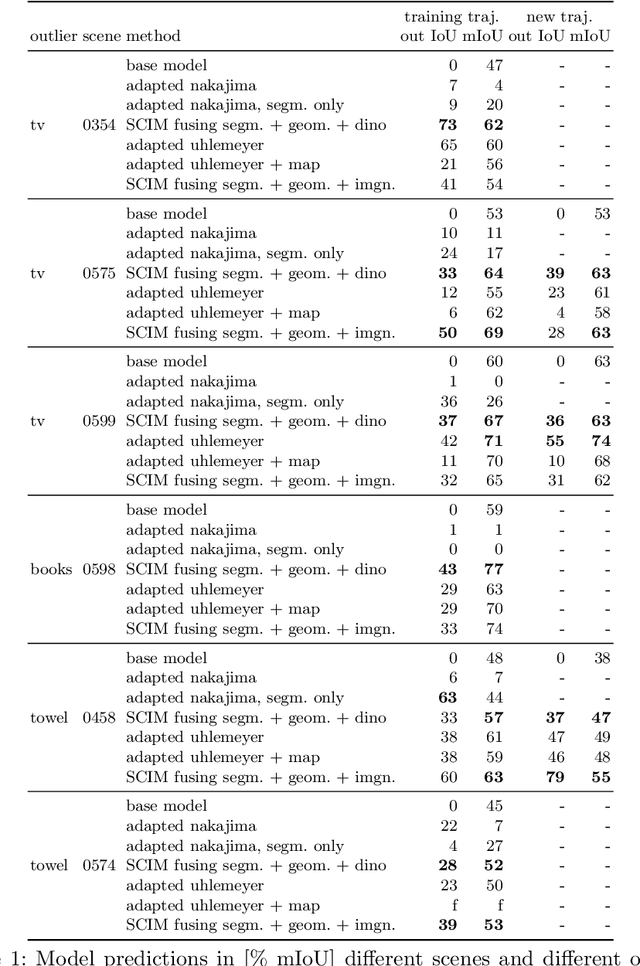
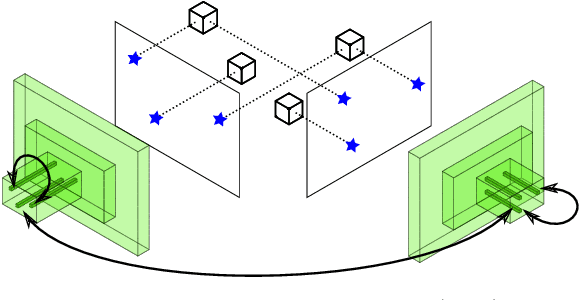
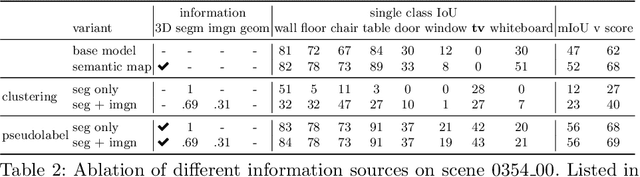
In order to operate in human environments, a robot's semantic perception has to overcome open-world challenges such as novel objects and domain gaps. Autonomous deployment to such environments therefore requires robots to update their knowledge and learn without supervision. We investigate how a robot can autonomously discover novel semantic classes and improve accuracy on known classes when exploring an unknown environment. To this end, we develop a general framework for mapping and clustering that we then use to generate a self-supervised learning signal to update a semantic segmentation model. In particular, we show how clustering parameters can be optimized during deployment and that fusion of multiple observation modalities improves novel object discovery compared to prior work.
Embodied Active Domain Adaptation for Semantic Segmentation via Informative Path Planning
Mar 01, 2022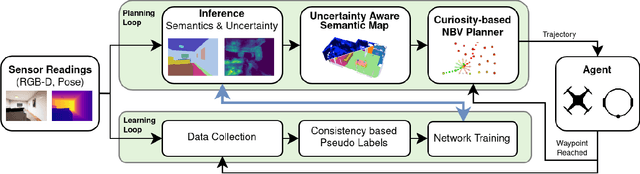
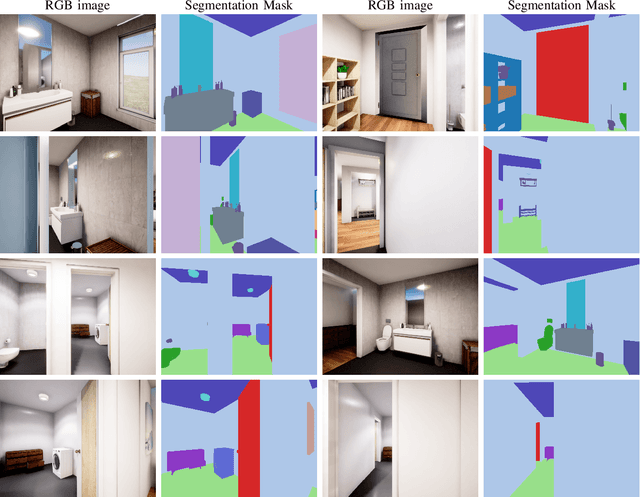


This work presents an embodied agent that can adapt its semantic segmentation network to new indoor environments in a fully autonomous way. Because semantic segmentation networks fail to generalize well to unseen environments, the agent collects images of the new environment which are then used for self-supervised domain adaptation. We formulate this as an informative path planning problem, and present a novel information gain that leverages uncertainty extracted from the semantic model to safely collect relevant data. As domain adaptation progresses, these uncertainties change over time and the rapid learning feedback of our system drives the agent to collect different data. Experiments show that our method adapts to new environments faster and with higher final performance compared to an exploration objective, and can successfully be deployed to real-world environments on physical robots.
SL Sensor: An Open-Source, ROS-Based, Real-Time Structured Light Sensor for High Accuracy Construction Robotic Applications
Jan 22, 2022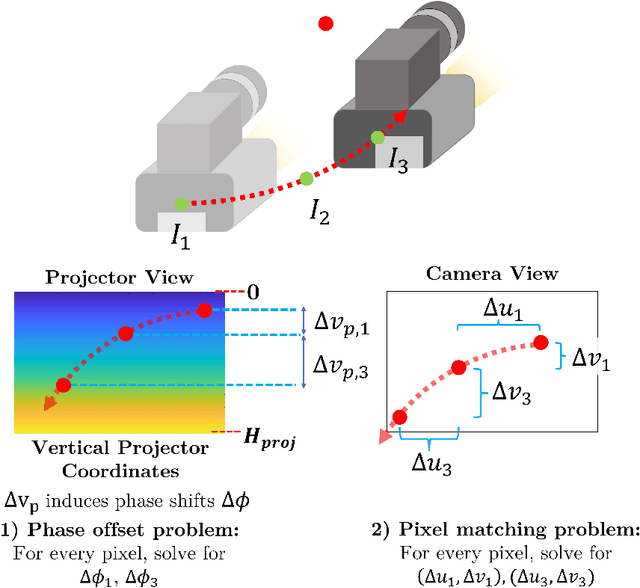


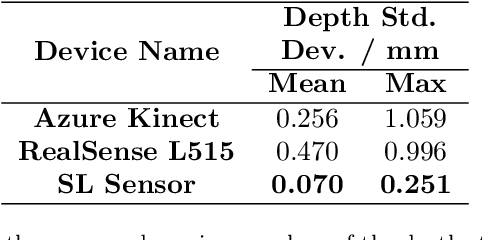
High accuracy 3D surface information is required for many construction robotics tasks such as automated cement polishing or robotic plaster spraying. However, consumer-grade depth cameras currently found in the market are not accurate enough for these tasks where millimeter (mm)-level accuracy is required. We present SL Sensor, a structured light sensing solution capable of producing high fidelity point clouds at 5Hz by leveraging on phase shifting profilometry (PSP) codification techniques. We compared SL Sensor to two commercial depth cameras - the Azure Kinect and RealSense L515. Experiments showed that the SL Sensor surpasses the two devices in both precision and accuracy. Furthermore, to demonstrate SL Sensor's ability to be a structured light sensing research platform for robotic applications, we developed a motion compensation strategy that allows the SL Sensor to operate during linear motion when traditional PSP methods only work when the sensor is static. Field experiments show that the SL Sensor is able produce highly detailed reconstructions of spray plastered surfaces. The software and a sample hardware build of the SL Sensor are made open-source with the objective to make structured light sensing more accessible to the construction robotics community. All documentation and code is available at https://github.com/ethz-asl/sl_sensor/ .
Continual Learning of Semantic Segmentation using Complementary 2D-3D Data Representations
Nov 03, 2021
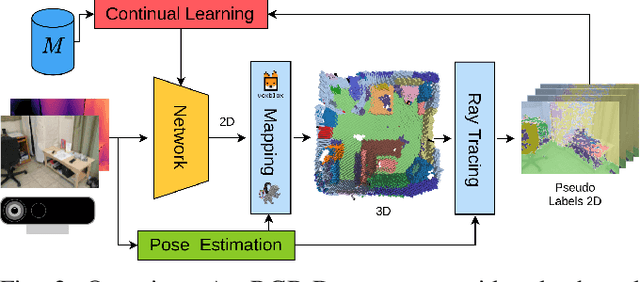
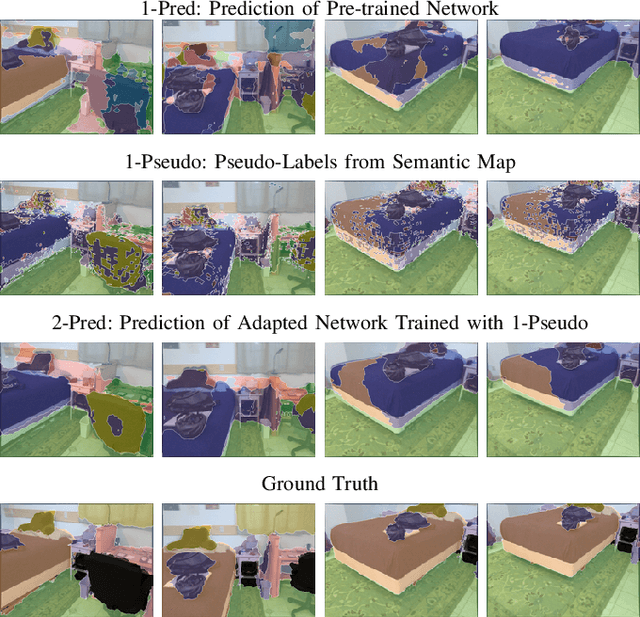

Semantic segmentation networks are usually pre-trained and not updated during deployment. As a consequence, misclassifications commonly occur if the distribution of the training data deviates from the one encountered during the robot's operation. We propose to mitigate this problem by adapting the neural network to the robot's environment during deployment, without any need for external supervision. Leveraging complementary data representations, we generate a supervision signal, by probabilistically accumulating consecutive 2D semantic predictions in a volumetric 3D map. We then retrain the network on renderings of the accumulated semantic map, effectively resolving ambiguities and enforcing multi-view consistency through the 3D representation. To preserve the previously-learned knowledge while performing network adaptation, we employ a continual learning strategy based on experience replay. Through extensive experimental evaluation, we show successful adaptation to real-world indoor scenes both on the ScanNet dataset and on in-house data recorded with an RGB-D sensor. Our method increases the segmentation performance on average by 11.8% compared to the fixed pre-trained neural network, while effectively retaining knowledge from the pre-training dataset.