 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThabo Beeler
FaceFolds: Meshed Radiance Manifolds for Efficient Volumetric Rendering of Dynamic Faces
Apr 22, 2024
3D rendering of dynamic face captures is a challenging problem, and it demands improvements on several fronts$\unicode{x2014}$photorealism, efficiency, compatibility, and configurability. We present a novel representation that enables high-quality volumetric rendering of an actor's dynamic facial performances with minimal compute and memory footprint. It runs natively on commodity graphics soft- and hardware, and allows for a graceful trade-off between quality and efficiency. Our method utilizes recent advances in neural rendering, particularly learning discrete radiance manifolds to sparsely sample the scene to model volumetric effects. We achieve efficient modeling by learning a single set of manifolds for the entire dynamic sequence, while implicitly modeling appearance changes as temporal canonical texture. We export a single layered mesh and view-independent RGBA texture video that is compatible with legacy graphics renderers without additional ML integration. We demonstrate our method by rendering dynamic face captures of real actors in a game engine, at comparable photorealism to state-of-the-art neural rendering techniques at previously unseen frame rates.
PhysAvatar: Learning the Physics of Dressed 3D Avatars from Visual Observations
Apr 09, 2024Modeling and rendering photorealistic avatars is of crucial importance in many applications. Existing methods that build a 3D avatar from visual observations, however, struggle to reconstruct clothed humans. We introduce PhysAvatar, a novel framework that combines inverse rendering with inverse physics to automatically estimate the shape and appearance of a human from multi-view video data along with the physical parameters of the fabric of their clothes. For this purpose, we adopt a mesh-aligned 4D Gaussian technique for spatio-temporal mesh tracking as well as a physically based inverse renderer to estimate the intrinsic material properties. PhysAvatar integrates a physics simulator to estimate the physical parameters of the garments using gradient-based optimization in a principled manner. These novel capabilities enable PhysAvatar to create high-quality novel-view renderings of avatars dressed in loose-fitting clothes under motions and lighting conditions not seen in the training data. This marks a significant advancement towards modeling photorealistic digital humans using physically based inverse rendering with physics in the loop. Our project website is at: https://qingqing-zhao.github.io/PhysAvatar
CHOSEN: Contrastive Hypothesis Selection for Multi-View Depth Refinement
Apr 02, 2024We propose CHOSEN, a simple yet flexible, robust and effective multi-view depth refinement framework. It can be employed in any existing multi-view stereo pipeline, with straightforward generalization capability for different multi-view capture systems such as camera relative positioning and lenses. Given an initial depth estimation, CHOSEN iteratively re-samples and selects the best hypotheses, and automatically adapts to different metric or intrinsic scales determined by the capture system. The key to our approach is the application of contrastive learning in an appropriate solution space and a carefully designed hypothesis feature, based on which positive and negative hypotheses can be effectively distinguished. Integrated in a simple baseline multi-view stereo pipeline, CHOSEN delivers impressive quality in terms of depth and normal accuracy compared to many current deep learning based multi-view stereo pipelines.
MagicMirror: Fast and High-Quality Avatar Generation with a Constrained Search Space
Apr 01, 2024We introduce a novel framework for 3D human avatar generation and personalization, leveraging text prompts to enhance user engagement and customization. Central to our approach are key innovations aimed at overcoming the challenges in photo-realistic avatar synthesis. Firstly, we utilize a conditional Neural Radiance Fields (NeRF) model, trained on a large-scale unannotated multi-view dataset, to create a versatile initial solution space that accelerates and diversifies avatar generation. Secondly, we develop a geometric prior, leveraging the capabilities of Text-to-Image Diffusion Models, to ensure superior view invariance and enable direct optimization of avatar geometry. These foundational ideas are complemented by our optimization pipeline built on Variational Score Distillation (VSD), which mitigates texture loss and over-saturation issues. As supported by our extensive experiments, these strategies collectively enable the creation of custom avatars with unparalleled visual quality and better adherence to input text prompts. You can find more results and videos in our website: https://syntec-research.github.io/MagicMirror
MACS: Mass Conditioned 3D Hand and Object Motion Synthesis
Dec 22, 2023The physical properties of an object, such as mass, significantly affect how we manipulate it with our hands. Surprisingly, this aspect has so far been neglected in prior work on 3D motion synthesis. To improve the naturalness of the synthesized 3D hand object motions, this work proposes MACS the first MAss Conditioned 3D hand and object motion Synthesis approach. Our approach is based on cascaded diffusion models and generates interactions that plausibly adjust based on the object mass and interaction type. MACS also accepts a manually drawn 3D object trajectory as input and synthesizes the natural 3D hand motions conditioned by the object mass. This flexibility enables MACS to be used for various downstream applications, such as generating synthetic training data for ML tasks, fast animation of hands for graphics workflows, and generating character interactions for computer games. We show experimentally that a small-scale dataset is sufficient for MACS to reasonably generalize across interpolated and extrapolated object masses unseen during the training. Furthermore, MACS shows moderate generalization to unseen objects, thanks to the mass-conditioned contact labels generated by our surface contact synthesis model ConNet. Our comprehensive user study confirms that the synthesized 3D hand-object interactions are highly plausible and realistic.
Optimizing Diffusion Noise Can Serve As Universal Motion Priors
Dec 19, 2023We propose Diffusion Noise Optimization (DNO), a new method that effectively leverages existing motion diffusion models as motion priors for a wide range of motion-related tasks. Instead of training a task-specific diffusion model for each new task, DNO operates by optimizing the diffusion latent noise of an existing pre-trained text-to-motion model. Given the corresponding latent noise of a human motion, it propagates the gradient from the target criteria defined on the motion space through the whole denoising process to update the diffusion latent noise. As a result, DNO supports any use cases where criteria can be defined as a function of motion. In particular, we show that, for motion editing and control, DNO outperforms existing methods in both achieving the objective and preserving the motion content. DNO accommodates a diverse range of editing modes, including changing trajectory, pose, joint locations, or avoiding newly added obstacles. In addition, DNO is effective in motion denoising and completion, producing smooth and realistic motion from noisy and partial inputs. DNO achieves these results at inference time without the need for model retraining, offering great versatility for any defined reward or loss function on the motion representation.
Egocentric Whole-Body Motion Capture with FisheyeViT and Diffusion-Based Motion Refinement
Dec 02, 2023In this work, we explore egocentric whole-body motion capture using a single fisheye camera, which simultaneously estimates human body and hand motion. This task presents significant challenges due to three factors: the lack of high-quality datasets, fisheye camera distortion, and human body self-occlusion. To address these challenges, we propose a novel approach that leverages FisheyeViT to extract fisheye image features, which are subsequently converted into pixel-aligned 3D heatmap representations for 3D human body pose prediction. For hand tracking, we incorporate dedicated hand detection and hand pose estimation networks for regressing 3D hand poses. Finally, we develop a diffusion-based whole-body motion prior model to refine the estimated whole-body motion while accounting for joint uncertainties. To train these networks, we collect a large synthetic dataset, EgoWholeBody, comprising 840,000 high-quality egocentric images captured across a diverse range of whole-body motion sequences. Quantitative and qualitative evaluations demonstrate the effectiveness of our method in producing high-quality whole-body motion estimates from a single egocentric camera.
Preface: A Data-driven Volumetric Prior for Few-shot Ultra High-resolution Face Synthesis
Sep 28, 2023NeRFs have enabled highly realistic synthesis of human faces including complex appearance and reflectance effects of hair and skin. These methods typically require a large number of multi-view input images, making the process hardware intensive and cumbersome, limiting applicability to unconstrained settings. We propose a novel volumetric human face prior that enables the synthesis of ultra high-resolution novel views of subjects that are not part of the prior's training distribution. This prior model consists of an identity-conditioned NeRF, trained on a dataset of low-resolution multi-view images of diverse humans with known camera calibration. A simple sparse landmark-based 3D alignment of the training dataset allows our model to learn a smooth latent space of geometry and appearance despite a limited number of training identities. A high-quality volumetric representation of a novel subject can be obtained by model fitting to 2 or 3 camera views of arbitrary resolution. Importantly, our method requires as few as two views of casually captured images as input at inference time.
ITI-GEN: Inclusive Text-to-Image Generation
Sep 11, 2023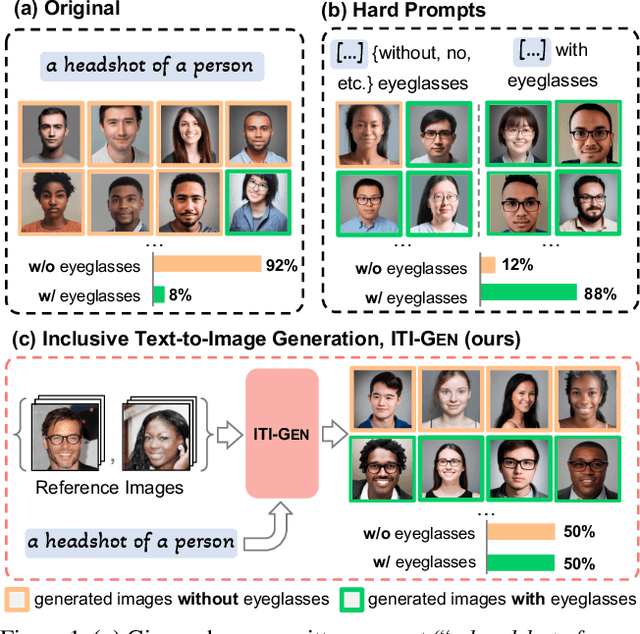
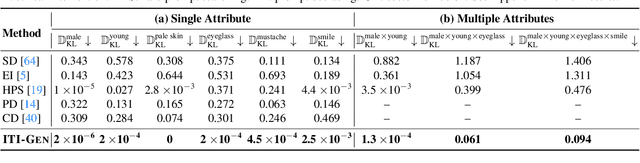
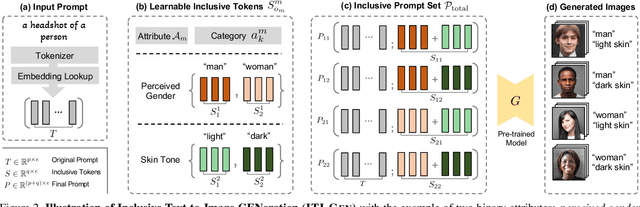
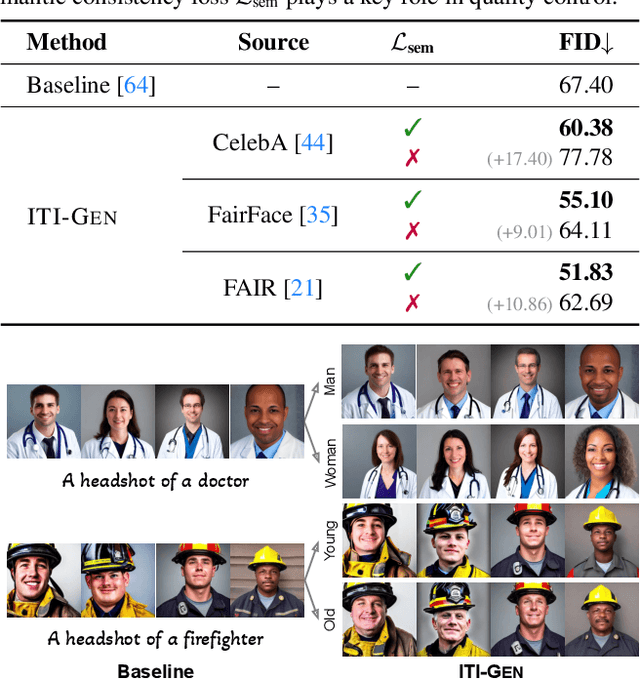
Text-to-image generative models often reflect the biases of the training data, leading to unequal representations of underrepresented groups. This study investigates inclusive text-to-image generative models that generate images based on human-written prompts and ensure the resulting images are uniformly distributed across attributes of interest. Unfortunately, directly expressing the desired attributes in the prompt often leads to sub-optimal results due to linguistic ambiguity or model misrepresentation. Hence, this paper proposes a drastically different approach that adheres to the maxim that "a picture is worth a thousand words". We show that, for some attributes, images can represent concepts more expressively than text. For instance, categories of skin tones are typically hard to specify by text but can be easily represented by example images. Building upon these insights, we propose a novel approach, ITI-GEN, that leverages readily available reference images for Inclusive Text-to-Image GENeration. The key idea is learning a set of prompt embeddings to generate images that can effectively represent all desired attribute categories. More importantly, ITI-GEN requires no model fine-tuning, making it computationally efficient to augment existing text-to-image models. Extensive experiments demonstrate that ITI-GEN largely improves over state-of-the-art models to generate inclusive images from a prompt. Project page: https://czhang0528.github.io/iti-gen.
Spectral Graphormer: Spectral Graph-based Transformer for Egocentric Two-Hand Reconstruction using Multi-View Color Images
Aug 21, 2023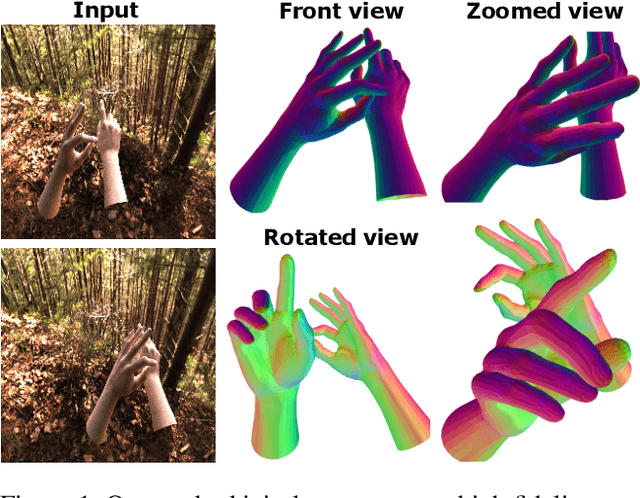
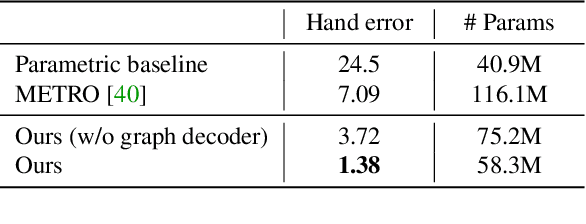
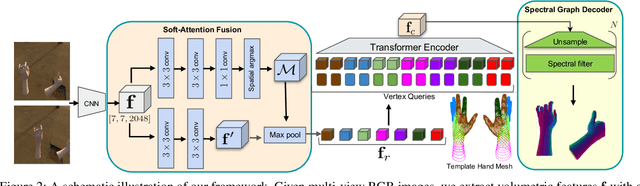

We propose a novel transformer-based framework that reconstructs two high fidelity hands from multi-view RGB images. Unlike existing hand pose estimation methods, where one typically trains a deep network to regress hand model parameters from single RGB image, we consider a more challenging problem setting where we directly regress the absolute root poses of two-hands with extended forearm at high resolution from egocentric view. As existing datasets are either infeasible for egocentric viewpoints or lack background variations, we create a large-scale synthetic dataset with diverse scenarios and collect a real dataset from multi-calibrated camera setup to verify our proposed multi-view image feature fusion strategy. To make the reconstruction physically plausible, we propose two strategies: (i) a coarse-to-fine spectral graph convolution decoder to smoothen the meshes during upsampling and (ii) an optimisation-based refinement stage at inference to prevent self-penetrations. Through extensive quantitative and qualitative evaluations, we show that our framework is able to produce realistic two-hand reconstructions and demonstrate the generalisation of synthetic-trained models to real data, as well as real-time AR/VR applications.