 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDaoye Wang
Preface: A Data-driven Volumetric Prior for Few-shot Ultra High-resolution Face Synthesis
Sep 28, 2023
NeRFs have enabled highly realistic synthesis of human faces including complex appearance and reflectance effects of hair and skin. These methods typically require a large number of multi-view input images, making the process hardware intensive and cumbersome, limiting applicability to unconstrained settings. We propose a novel volumetric human face prior that enables the synthesis of ultra high-resolution novel views of subjects that are not part of the prior's training distribution. This prior model consists of an identity-conditioned NeRF, trained on a dataset of low-resolution multi-view images of diverse humans with known camera calibration. A simple sparse landmark-based 3D alignment of the training dataset allows our model to learn a smooth latent space of geometry and appearance despite a limited number of training identities. A high-quality volumetric representation of a novel subject can be obtained by model fitting to 2 or 3 camera views of arbitrary resolution. Importantly, our method requires as few as two views of casually captured images as input at inference time.
Deep Dynamic Scene Deblurring from Optical Flow
Jan 18, 2023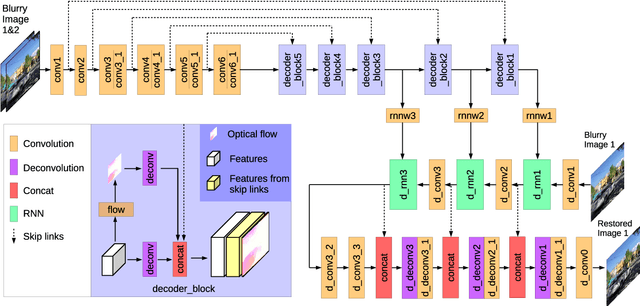


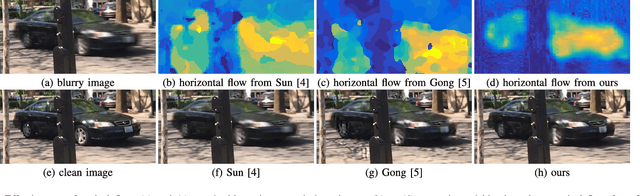
Deblurring can not only provide visually more pleasant pictures and make photography more convenient, but also can improve the performance of objection detection as well as tracking. However, removing dynamic scene blur from images is a non-trivial task as it is difficult to model the non-uniform blur mathematically. Several methods first use single or multiple images to estimate optical flow (which is treated as an approximation of blur kernels) and then adopt non-blind deblurring algorithms to reconstruct the sharp images. However, these methods cannot be trained in an end-to-end manner and are usually computationally expensive. In this paper, we explore optical flow to remove dynamic scene blur by using the multi-scale spatially variant recurrent neural network (RNN). We utilize FlowNets to estimate optical flow from two consecutive images in different scales. The estimated optical flow provides the RNN weights in different scales so that the weights can better help RNNs to remove blur in the feature spaces. Finally, we develop a convolutional neural network (CNN) to restore the sharp images from the deblurred features. Both quantitative and qualitative evaluations on the benchmark datasets demonstrate that the proposed method performs favorably against state-of-the-art algorithms in terms of accuracy, speed, and model size.
Low-Dose CT Denoising Using a Structure-Preserving Kernel Prediction Network
May 31, 2021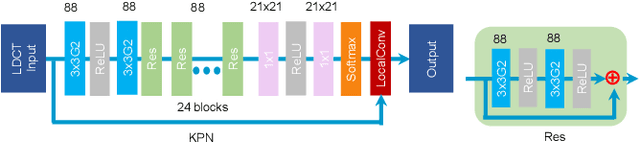
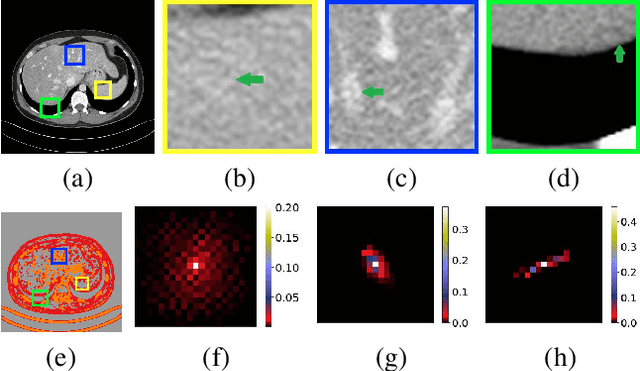


Low-dose CT has been a key diagnostic imaging modality to reduce the potential risk of radiation overdose to patient health. Despite recent advances, CNN-based approaches typically apply filters in a spatially invariant way and adopt similar pixel-level losses, which treat all regions of the CT image equally and can be inefficient when fine-grained structures coexist with non-uniformly distributed noises. To address this issue, we propose a Structure-preserving Kernel Prediction Network (StructKPN) that combines the kernel prediction network with a structure-aware loss function that utilizes the pixel gradient statistics and guides the model towards spatially-variant filters that enhance noise removal, prevent over-smoothing and preserve detailed structures for different regions in CT imaging. Extensive experiments demonstrated that our approach achieved superior performance on both synthetic and non-synthetic datasets, and better preserves structures that are highly desired in clinical screening and low-dose protocol optimization.
Dual Student: Breaking the Limits of the Teacher in Semi-supervised Learning
Sep 03, 2019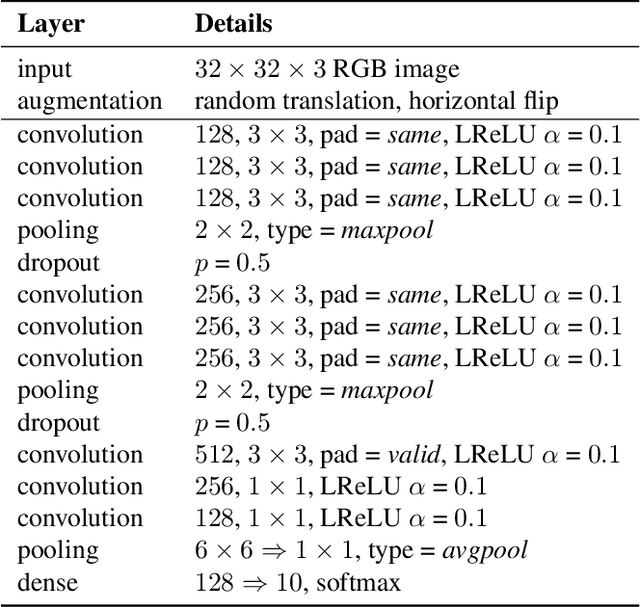

Recently, consistency-based methods have achieved state-of-the-art results in semi-supervised learning (SSL). These methods always involve two roles, an explicit or implicit teacher model and a student model, and penalize predictions under different perturbations by a consistency constraint. However, the weights of these two roles are tightly coupled since the teacher is essentially an exponential moving average (EMA) of the student. In this work, we show that the coupled EMA teacher causes a performance bottleneck. To address this problem, we introduce Dual Student, which replaces the teacher with another student. We also define a novel concept, stable sample, following which a stabilization constraint is designed for our structure to be trainable. Further, we discuss two variants of our method, which produce even higher performance. Extensive experiments show that our method improves the classification performance significantly on several main SSL benchmarks. Specifically, it reduces the error rate of the 13-layer CNN from 16.84% to 12.39% on CIFAR-10 with 1k labels and from 34.10% to 31.56% on CIFAR-100 with 10k labels. In addition, our method also achieves a clear improvement in domain adaptation.