 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXing Wei
Few-shot Online Anomaly Detection and Segmentation
Mar 27, 2024
Detecting anomaly patterns from images is a crucial artificial intelligence technique in industrial applications. Recent research in this domain has emphasized the necessity of a large volume of training data, overlooking the practical scenario where, post-deployment of the model, unlabeled data containing both normal and abnormal samples can be utilized to enhance the model's performance. Consequently, this paper focuses on addressing the challenging yet practical few-shot online anomaly detection and segmentation (FOADS) task. Under the FOADS framework, models are trained on a few-shot normal dataset, followed by inspection and improvement of their capabilities by leveraging unlabeled streaming data containing both normal and abnormal samples simultaneously. To tackle this issue, we propose modeling the feature distribution of normal images using a Neural Gas network, which offers the flexibility to adapt the topology structure to identify outliers in the data flow. In order to achieve improved performance with limited training samples, we employ multi-scale feature embedding extracted from a CNN pre-trained on ImageNet to obtain a robust representation. Furthermore, we introduce an algorithm that can incrementally update parameters without the need to store previous samples. Comprehensive experimental results demonstrate that our method can achieve substantial performance under the FOADS setting, while ensuring that the time complexity remains within an acceptable range on MVTec AD and BTAD datasets.
CEAT: Continual Expansion and Absorption Transformer for Non-Exemplar Class-Incremental Learning
Mar 12, 2024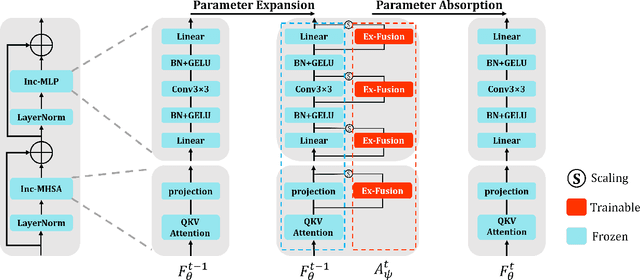
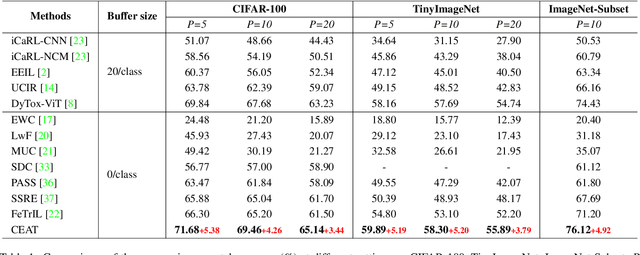
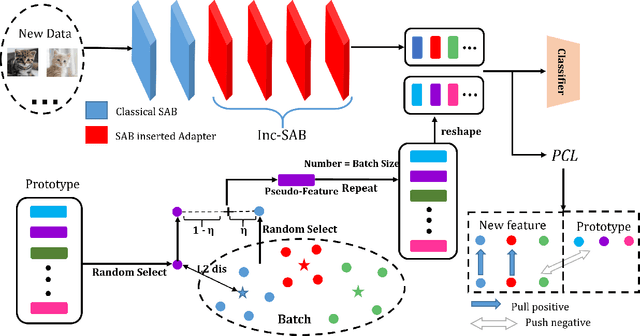
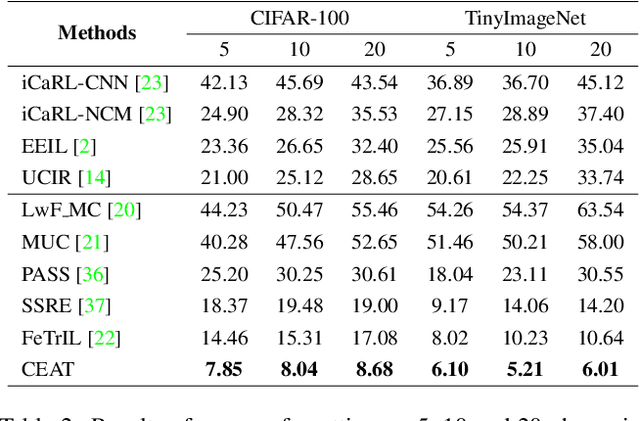
In real-world applications, dynamic scenarios require the models to possess the capability to learn new tasks continuously without forgetting the old knowledge. Experience-Replay methods store a subset of the old images for joint training. In the scenario of more strict privacy protection, storing the old images becomes infeasible, which leads to a more severe plasticity-stability dilemma and classifier bias. To meet the above challenges, we propose a new architecture, named continual expansion and absorption transformer~(CEAT). The model can learn the novel knowledge by extending the expanded-fusion layers in parallel with the frozen previous parameters. After the task ends, we losslessly absorb the extended parameters into the backbone to ensure that the number of parameters remains constant. To improve the learning ability of the model, we designed a novel prototype contrastive loss to reduce the overlap between old and new classes in the feature space. Besides, to address the classifier bias towards the new classes, we propose a novel approach to generate the pseudo-features to correct the classifier. We experiment with our methods on three standard Non-Exemplar Class-Incremental Learning~(NECIL) benchmarks. Extensive experiments demonstrate that our model gets a significant improvement compared with the previous works and achieves 5.38%, 5.20%, and 4.92% improvement on CIFAR-100, TinyImageNet, and ImageNet-Subset.
ARTrackV2: Prompting Autoregressive Tracker Where to Look and How to Describe
Dec 29, 2023We present ARTrackV2, which integrates two pivotal aspects of tracking: determining where to look (localization) and how to describe (appearance analysis) the target object across video frames. Building on the foundation of its predecessor, ARTrackV2 extends the concept by introducing a unified generative framework to "read out" object's trajectory and "retell" its appearance in an autoregressive manner. This approach fosters a time-continuous methodology that models the joint evolution of motion and visual features, guided by previous estimates. Furthermore, ARTrackV2 stands out for its efficiency and simplicity, obviating the less efficient intra-frame autoregression and hand-tuned parameters for appearance updates. Despite its simplicity, ARTrackV2 achieves state-of-the-art performance on prevailing benchmark datasets while demonstrating remarkable efficiency improvement. In particular, ARTrackV2 achieves AO score of 79.5\% on GOT-10k, and AUC of 86.1\% on TrackingNet while being $3.6 \times$ faster than ARTrack. The code will be released.
MachMap: End-to-End Vectorized Solution for Compact HD-Map Construction
Jun 17, 2023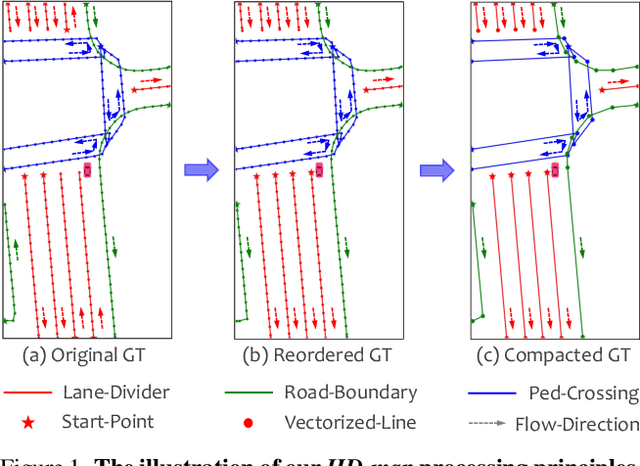

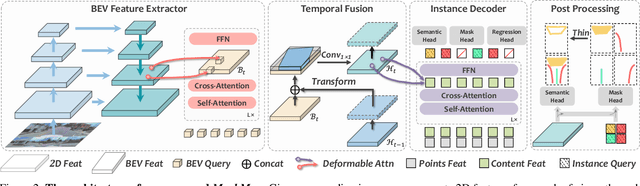
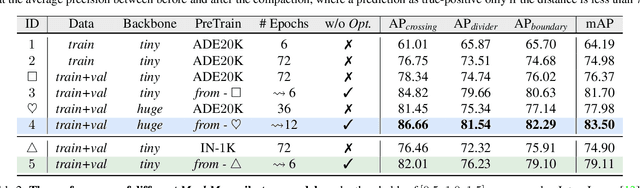
This report introduces the 1st place winning solution for the Autonomous Driving Challenge 2023 - Online HD-map Construction. By delving into the vectorization pipeline, we elaborate an effective architecture, termed as MachMap, which formulates the task of HD-map construction as the point detection paradigm in the bird-eye-view space with an end-to-end manner. Firstly, we introduce a novel map-compaction scheme into our framework, leading to reducing the number of vectorized points by 93% without any expression performance degradation. Build upon the above process, we then follow the general query-based paradigm and propose a strong baseline with integrating a powerful CNN-based backbone like InternImage, a temporal-based instance decoder and a well-designed point-mask coupling head. Additionally, an extra optional ensemble stage is utilized to refine model predictions for better performance. Our MachMap-tiny with IN-1K initialization achieves a mAP of 79.1 on the Argoverse2 benchmark and the further improved MachMap-huge reaches the best mAP of 83.5, outperforming all the other online HD-map construction approaches on the final leaderboard with a distinct performance margin (> 9.8 mAP at least).
Knowledge Restore and Transfer for Multi-label Class-Incremental Learning
Mar 07, 2023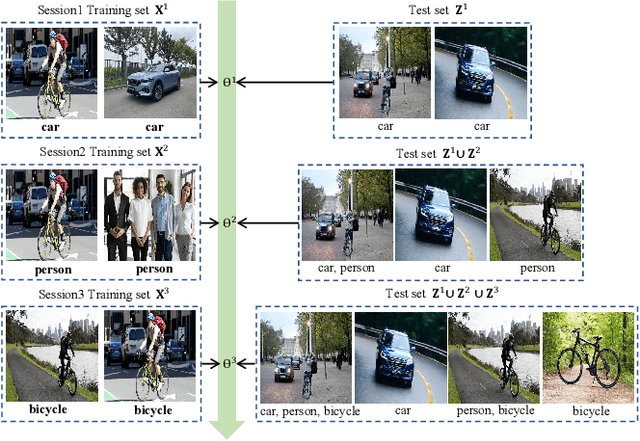
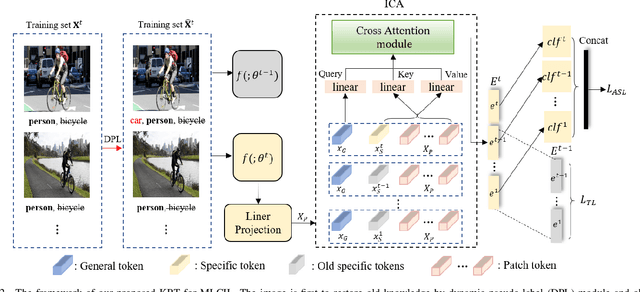
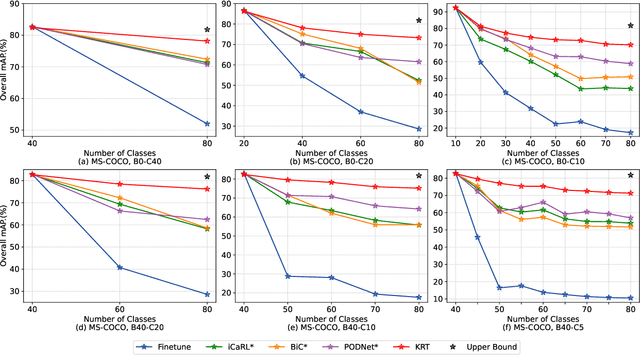
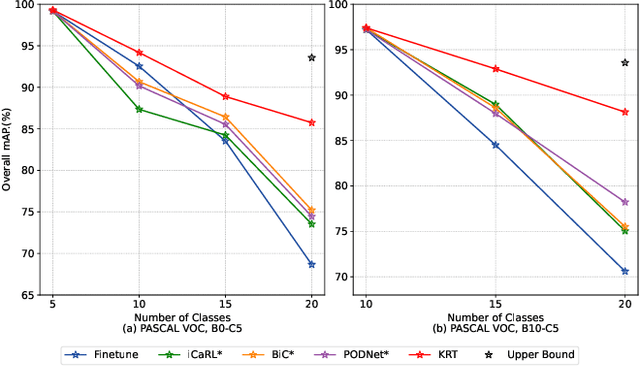
Current class-incremental learning research mainly focuses on single-label classification tasks while multi-label class-incremental learning (MLCIL) with more practical application scenarios is rarely studied. Although there have been many anti-forgetting methods to solve the problem of catastrophic forgetting in class-incremental learning, these methods have difficulty in solving the MLCIL problem due to label absence and information dilution. In this paper, we propose a knowledge restore and transfer (KRT) framework for MLCIL, which includes a dynamic pseudo-label (DPL) module to restore the old class knowledge and an incremental cross-attention(ICA) module to save session-specific knowledge and transfer old class knowledge to the new model sufficiently. Besides, we propose a token loss to jointly optimize the incremental cross-attention module. Experimental results on MS-COCO and PASCAL VOC datasets demonstrate the effectiveness of our method for improving recognition performance and mitigating forgetting on multi-label class-incremental learning tasks.
Deep Dynamic Scene Deblurring from Optical Flow
Jan 18, 2023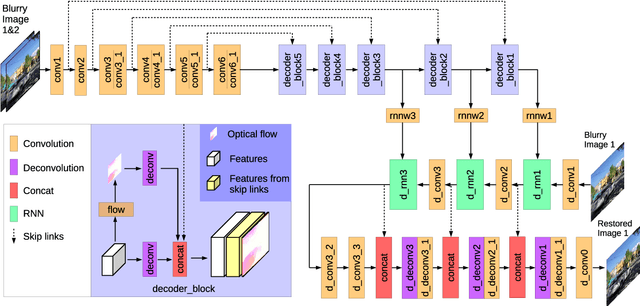


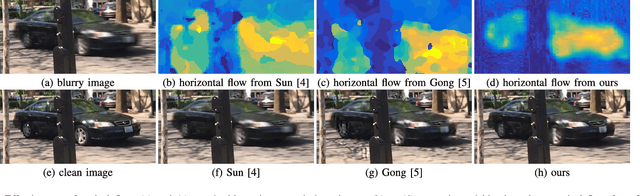
Deblurring can not only provide visually more pleasant pictures and make photography more convenient, but also can improve the performance of objection detection as well as tracking. However, removing dynamic scene blur from images is a non-trivial task as it is difficult to model the non-uniform blur mathematically. Several methods first use single or multiple images to estimate optical flow (which is treated as an approximation of blur kernels) and then adopt non-blind deblurring algorithms to reconstruct the sharp images. However, these methods cannot be trained in an end-to-end manner and are usually computationally expensive. In this paper, we explore optical flow to remove dynamic scene blur by using the multi-scale spatially variant recurrent neural network (RNN). We utilize FlowNets to estimate optical flow from two consecutive images in different scales. The estimated optical flow provides the RNN weights in different scales so that the weights can better help RNNs to remove blur in the feature spaces. Finally, we develop a convolutional neural network (CNN) to restore the sharp images from the deblurred features. Both quantitative and qualitative evaluations on the benchmark datasets demonstrate that the proposed method performs favorably against state-of-the-art algorithms in terms of accuracy, speed, and model size.
IR2Net: Information Restriction and Information Recovery for Accurate Binary Neural Networks
Oct 06, 2022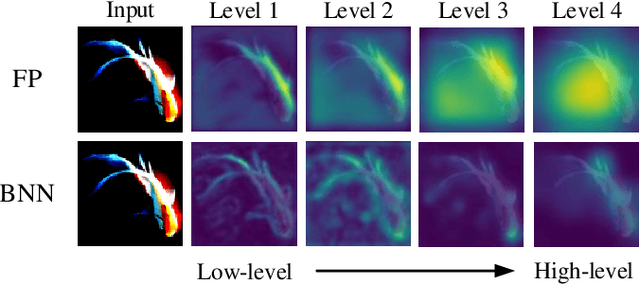
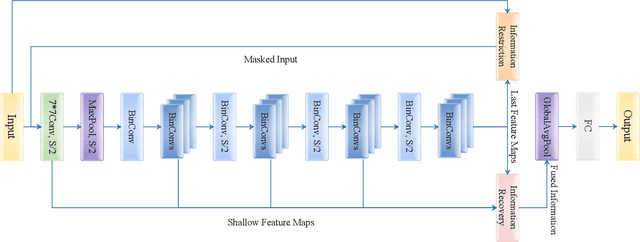
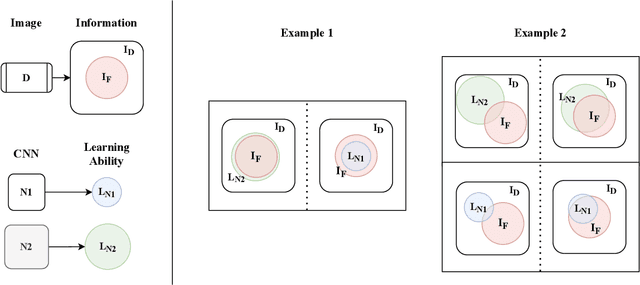
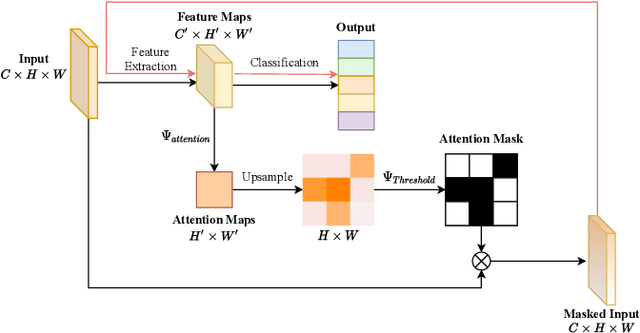
Weight and activation binarization can efficiently compress deep neural networks and accelerate model inference, but cause severe accuracy degradation. Existing optimization methods for binary neural networks (BNNs) focus on fitting full-precision networks to reduce quantization errors, and suffer from the trade-off between accuracy and computational complexity. In contrast, considering the limited learning ability and information loss caused by the limited representational capability of BNNs, we propose IR$^2$Net to stimulate the potential of BNNs and improve the network accuracy by restricting the input information and recovering the feature information, including: 1) information restriction: for a BNN, by evaluating the learning ability on the input information, discarding some of the information it cannot focus on, and limiting the amount of input information to match its learning ability; 2) information recovery: due to the information loss in forward propagation, the output feature information of the network is not enough to support accurate classification. By selecting some shallow feature maps with richer information, and fusing them with the final feature maps to recover the feature information. In addition, the computational cost is reduced by streamlining the information recovery method to strike a better trade-off between accuracy and efficiency. Experimental results demonstrate that our approach still achieves comparable accuracy even with $ \sim $10x floating-point operations (FLOPs) reduction for ResNet-18. The models and code are available at https://github.com/pingxue-hfut/IR2Net.
Scene-Adaptive Attention Network for Crowd Counting
Dec 31, 2021
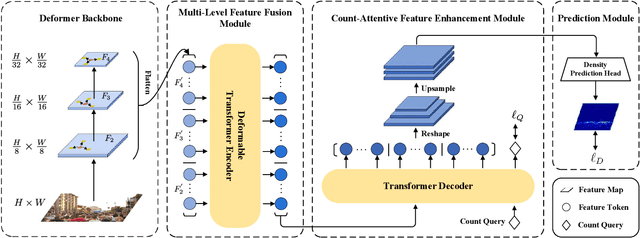
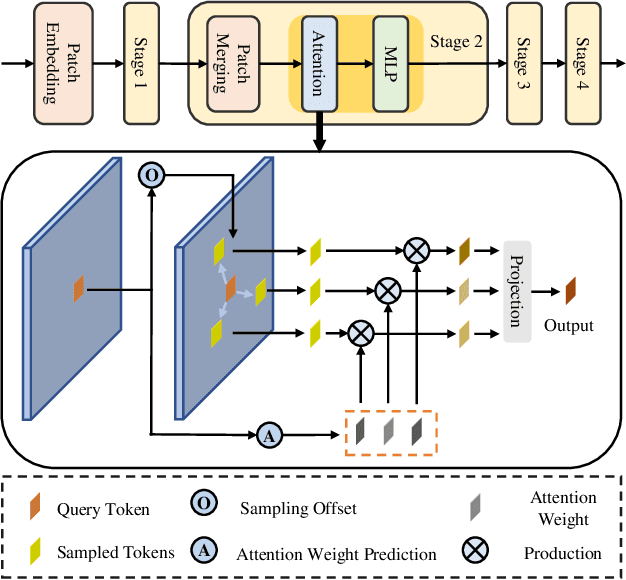
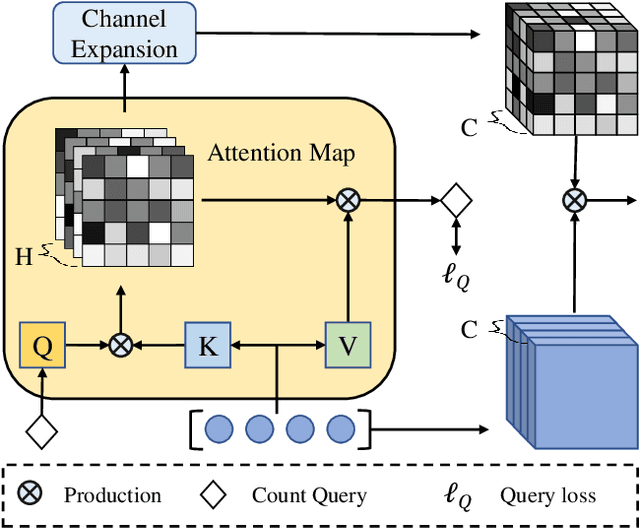
In recent years, significant progress has been made on the research of crowd counting. However, as the challenging scale variations and complex scenes existed in crowds, neither traditional convolution networks nor recent Transformer architectures with fixed-size attention could handle the task well. To address this problem, this paper proposes a scene-adaptive attention network, termed SAANet. First of all, we design a deformable attention in-built Transformer backbone, which learns adaptive feature representations with deformable sampling locations and dynamic attention weights. Then we propose the multi-level feature fusion and count-attentive feature enhancement modules further, to strengthen feature representation under the global image context. The learned representations could attend to the foreground and are adaptive to different scales of crowds. We conduct extensive experiments on four challenging crowd counting benchmarks, demonstrating that our method achieves state-of-the-art performance. Especially, our method currently ranks No.1 on the public leaderboard of the NWPU-Crowd benchmark. We hope our method could be a strong baseline to support future research in crowd counting. The source code will be released to the community.
SOIT: Segmenting Objects with Instance-Aware Transformers
Dec 23, 2021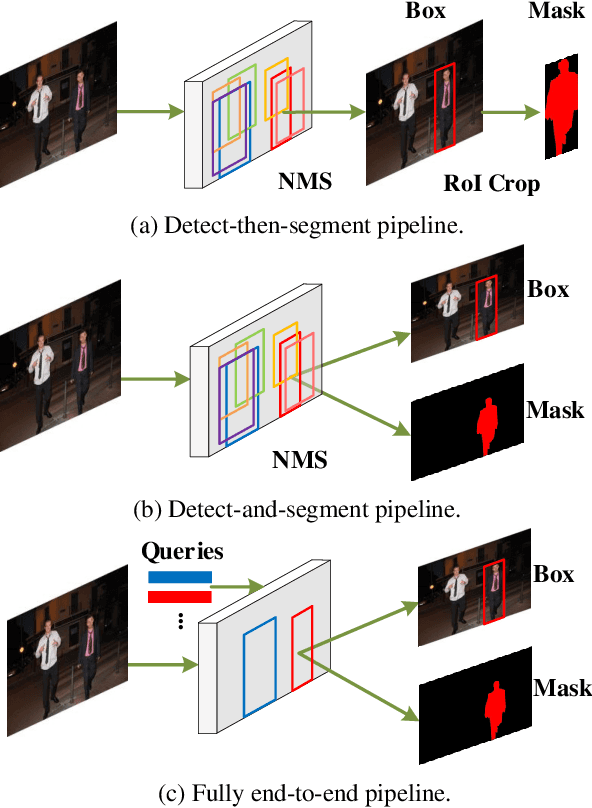
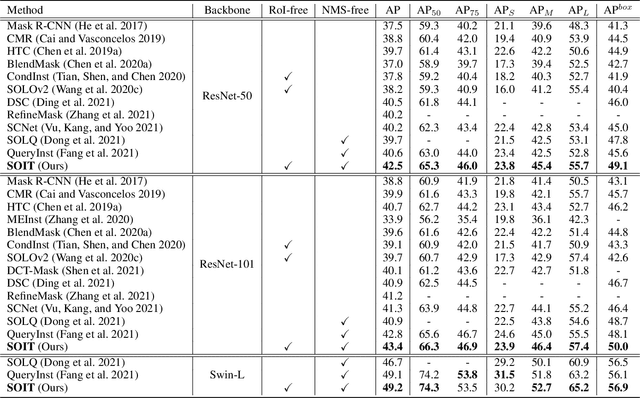
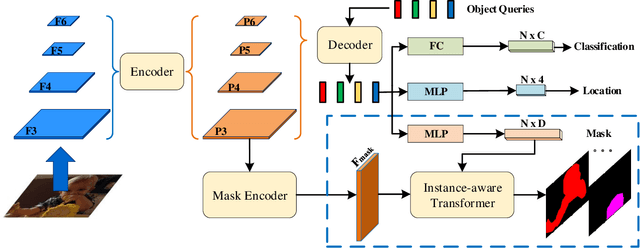
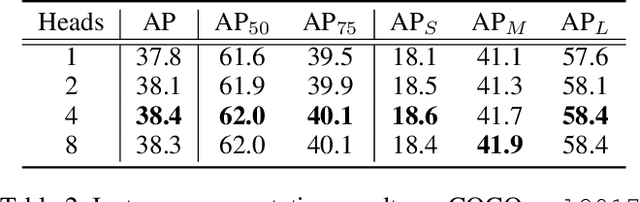
This paper presents an end-to-end instance segmentation framework, termed SOIT, that Segments Objects with Instance-aware Transformers. Inspired by DETR \cite{carion2020end}, our method views instance segmentation as a direct set prediction problem and effectively removes the need for many hand-crafted components like RoI cropping, one-to-many label assignment, and non-maximum suppression (NMS). In SOIT, multiple queries are learned to directly reason a set of object embeddings of semantic category, bounding-box location, and pixel-wise mask in parallel under the global image context. The class and bounding-box can be easily embedded by a fixed-length vector. The pixel-wise mask, especially, is embedded by a group of parameters to construct a lightweight instance-aware transformer. Afterward, a full-resolution mask is produced by the instance-aware transformer without involving any RoI-based operation. Overall, SOIT introduces a simple single-stage instance segmentation framework that is both RoI- and NMS-free. Experimental results on the MS COCO dataset demonstrate that SOIT outperforms state-of-the-art instance segmentation approaches significantly. Moreover, the joint learning of multiple tasks in a unified query embedding can also substantially improve the detection performance. Code is available at \url{https://github.com/yuxiaodongHRI/SOIT}.
Online Continual Learning via Multiple Deep Metric Learning and Uncertainty-guided Episodic Memory Replay -- 3rd Place Solution for ICCV 2021 Workshop SSLAD Track 3A Continual Object Classification
Nov 04, 2021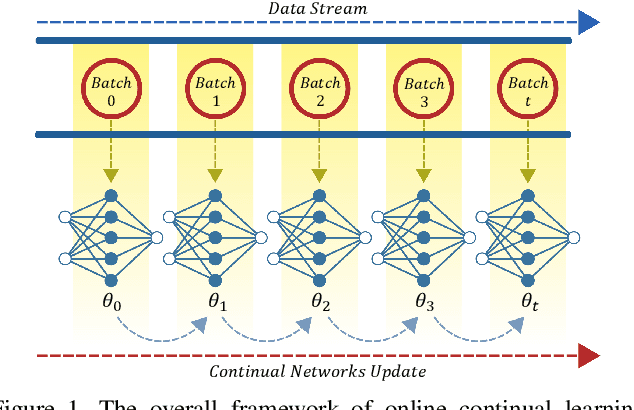
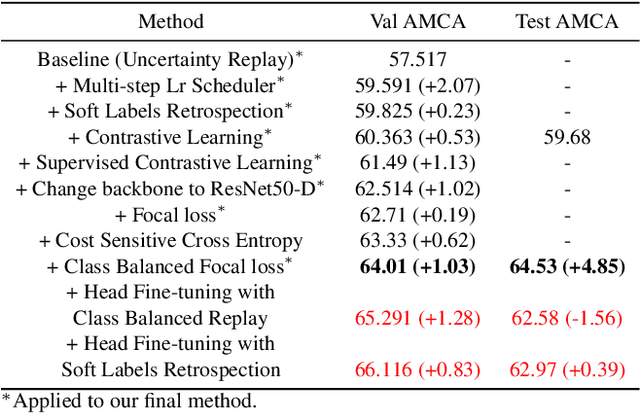
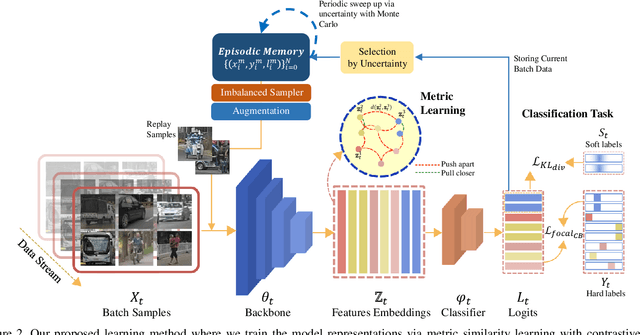
Online continual learning in the wild is a very difficult task in machine learning. Non-stationarity in online continual learning potentially brings about catastrophic forgetting in neural networks. Specifically, online continual learning for autonomous driving with SODA10M dataset exhibits extra problems on extremely long-tailed distribution with continuous distribution shift. To address these problems, we propose multiple deep metric representation learning via both contrastive and supervised contrastive learning alongside soft labels distillation to improve model generalization. Moreover, we exploit modified class-balanced focal loss for sensitive penalization in class imbalanced and hard-easy samples. We also store some samples under guidance of uncertainty metric for rehearsal and perform online and periodical memory updates. Our proposed method achieves considerable generalization with average mean class accuracy (AMCA) 64.01% on validation and 64.53% AMCA on test set.